《数据分析师》专题
-
 美团探索分析产品组-数据产品(分析方向)面经
美团探索分析产品组-数据产品(分析方向)面经一面 2023.1.10 着重考察个人性格能力(自驱性、积极主动性、对成长的思考)、过往项目的参与深度 自我介绍 选一段实习经历,讲一下你的工作和角色 快手这段经历干了很久,为什么要离职 你说你在快手后期是主动思考的角色,讲一个例子证明一下 你觉得这些实习经历里,让你觉得有挑战,比较困难的事情或者时刻是什么 用一句话形容你自己 你下一段实习的目标是什么,希望获得什么 面试官介绍岗位对接的业务、工作
-
 数据分析24暑期实习总结(3)-淘天数分oc
数据分析24暑期实习总结(3)-淘天数分oc写在前面 bg:9本+水硕,投递时实习经历:中厂数分+大厂数据产品+大厂数分本身数学统计基础很差,ml相关基础也差,求职意向主要为业务向数分手动加粗:希望认出的大佬手下留情,私聊就好,社恐害怕评论区掉马甲。也欢迎各位牛友交流哇!打破信息差~ ---分割线--- 岗位:淘天-天猫事业部-数据分析 tl:3.19投递-4.6一面-4.7二面-4.12oc-5.17再次oc。。 ---分割线--- 一面
-
 2023届秋招 猿辅导 数据分析师 笔试
2023届秋招 猿辅导 数据分析师 笔试一 选择 40道选择 其中 包含概率、sql、逻辑推断、机器学习相关 每题1分较为简单 二 填空 略 三 主观题 1 需要调研目标用户规模,但是没有数据,你会怎么估算2-4岁的适龄儿童人数 ps: 考察费米估算 2 斑马app流失用户如何定义? 怎样搭建用户流失模型
-
 Oppo提前批数据分析工程师(已意向)
Oppo提前批数据分析工程师(已意向)总评:oppo整体面试难度不是很大,一面主要是简历深耕,二面会问一些更加综合的题目,包括与业务方合作机制等,二面的面试难度更大一些; 面试官态度很友好,期间我语音坏了,然后僵持了几分钟,后来通过电话联系面试官进行面试,整个过程没有任何的不耐烦,还鼓励我不要因为这个影响面试,十分感动了! 一面简历深耕: 1. 哪段实习收获最大? (回答哪一段都行其实,重点是考察面试者复盘能力,以及实践
-
 2023届校招面经:猿辅导-数据分析师
2023届校招面经:猿辅导-数据分析师TimeLine:一面20220820,二面20220827(已挂) BG:北邮本硕,管理类专业,两段实习经历:字节数据分析师、美团商业分析师 笔试 涉及统计学、概率论、机器学习、SQL等方面的知识,详情可在牛客网上搜索“猿辅导数据分析笔试”获取更多信息 一面 1. SQL题,口述解法即可 课程信息表lesson_order,字段:学科 subject, 用户id userid, 订单id ord
-
 三七互娱|数据分析师(市场岗)笔试
三七互娱|数据分析师(市场岗)笔试投递时间:2月底 笔试邮件:3月3,当天就要笔试,60min 问题: 1.给了一幅素材投放表,分析哪个最划算 2.广告roi下降,写出你的分析思路和逻辑 3.对家项目执行不到位怎么沟通 4.自己对数据分析师理解,及设想 暂无下文 bg:一般,会一点spss,擅长市场调研及报告撰写,参加过数学建模(简历都有体现) #你已经投递多少份简历了# #三七互娱# ————更———— 11号收到通过笔试通知
-
 两氢一氧(HHO)数据分析师社招面经
两氢一氧(HHO)数据分析师社招面经*刚结束面试就想说坏话 我还第一次见晚上8点面试的公司呢(假笑) ---------------------------------------------------------- HHO是阿里钉钉前CEO无招创业的公司,蛰伏了两年多今年有了新业务(看到一堆通稿),开始招人了 是在BOSS*聘上交流的,真正的BOSS直聘,负责人直接发的面试通知,备注里一行小字“要求提前了解AA,BB”(公司产品
-
 快手实习数据分析师【DA】一面凉经
快手实习数据分析师【DA】一面凉经一面:女性面试官(业务)#第一份面经# 居然没有自我介绍!!! 开始是她把自己的部门说了一遍以及对实习生的要求, 1、两道SQL T1求留存率,(id,date) T2求学生总成绩前10名——窗口函数 2、两道业务 T1分析用户视频发布数量下降的原因 T2如果你是视频发布者,你会因为什么原因减少视频发布?
-
 美团 数据分析师(产品经理向) 一面
美团 数据分析师(产品经理向) 一面27分钟,面试官是一位人特别好的小姐姐,超级礼貌 首先自我介绍,然后她简单介绍了一下部门的业务:将美团推向香港的新业务,focus在骑手配送方面,通过数据分析等手段找到潜在或已经存在的问题。 深挖了一个项目经历,会给到非常积极的反馈! 业务问题:如果一个骑手不愿意接单,你会如何分析原因? 答: 平台:补贴、工资激励政策;优化订单密度(供需供给算法) 外部:天气恶劣、交通情况(堵车...) 骑手个人
-
 2023春招-面试-杉树科技-数据分析师
2023春招-面试-杉树科技-数据分析师公司:杉树科技 岗位:数据分析师 形式:视频面试 视频面试平台:腾讯会议 面试官:数据分析师、HR 时长:25分钟 流程: 数据分析师(16分钟) 1、自我介绍 2、具体描述一下之前的实习经历,特别是数据分析这一块,比如遇到了哪些问题、有什么分析逻辑、如何去解决问题。 3、深挖项目:在这些工作中有没有得到什么有意思的结论? 4、继续深挖项目。 5、对机器学习大概有一个什么程度的了解? 6、解释一下
-
 交通银行江苏省分行_一面(数据分析)
交通银行江苏省分行_一面(数据分析)交行 金融科技储备生_数据分析 面试官两人,一个组同时把4人拉进面试间。每个人轮流发言。问题就两个:自我介绍,以及做过的项目 神仙打架,一堆有实习经历的大佬,还做了一堆牛逼的项目,呆过各种牛逼的实验室 总的来说,我这个没实习的跨专业小辣鸡,没有丝毫的竞争优势 #交通银行##交通银行面试#
-
python数据分析:关键字提取方式
本文向大家介绍python数据分析:关键字提取方式,包括了python数据分析:关键字提取方式的使用技巧和注意事项,需要的朋友参考一下 TF-IDF TF-IDF(Term Frequencey-Inverse Document Frequency)指词频-逆文档频率,它属于数值统计的范畴。使用TF-IDF,我们能够学习一个词对于数据集中的一个文档的重要性。 TF-IDF的概念 TF-IDF有两部
-
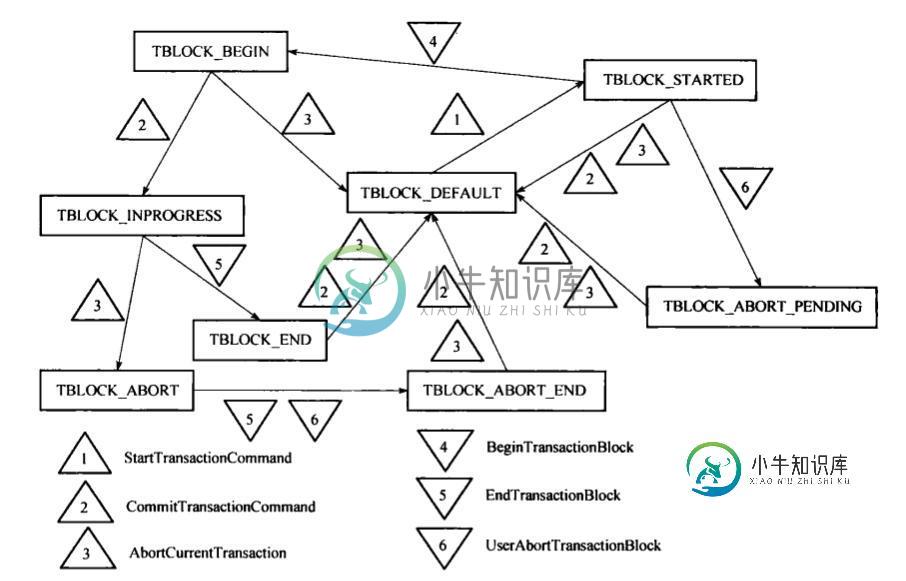 PostgreSQL数据库事务实现方法分析
PostgreSQL数据库事务实现方法分析本文向大家介绍PostgreSQL数据库事务实现方法分析,包括了PostgreSQL数据库事务实现方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PostgreSQL数据库事务实现方法。分享给大家供大家参考,具体如下: 事务简介 事务管理器:有限状态机 日志管理器 CLOG:事务的执行结果 XLOG:undo/redo日志 锁管理器:实现并发控制,读阶段采用MVCC,写阶段采用锁控
-
Regex用于分析数据库列,如JDBC ResultSet
我正在使用JDBC从查询结果中获取列。 例如: 我想在运行查询之前解析它们。本质上,我希望为列标签创建一个数组,该数组将与resultSet所期望的值相匹配。get**方法。出于说明的目的,我想用这个替换上面的循环,并得到相同的结果: 这看起来很简单。我可以用一个简单的正则表达式解析我的语句,该正则表达式接受SELECT和from之间的字符串,使用列分隔符创建组,并从组中构建arrayOf列。但是
-
如何进行探索性数据分析(EDA)?
本文向大家介绍如何进行探索性数据分析(EDA)?相关面试题,主要包含被问及如何进行探索性数据分析(EDA)?时的应答技巧和注意事项,需要的朋友参考一下 EDA的目的是去挖掘数据的一些重要信息。一般情况下会从粗到细的方式进行EDA探索。一开始我们可以去探索一些全局性的信息。观察一些不平衡的数据,计算一下各个类的方差和均值。看一下前几行数据的信息,包含什么特征等信息。使用Pandas中的df.info