《大数据分析》专题
-
 快手-电商-数据分析师-日常实习(凉经)
快手-电商-数据分析师-日常实习(凉经)复盘一下面试经历,总体来说回答地磕磕绊绊,面试官很耐心一直在引导回答。 但是我的水平不够,缺少深入思考,回答的点很散不成体系,逻辑性也不强。 有些题面试官点出了关键,对比自己的回答,明显感受到思维层次差距。 把面试题和自己的回答都放上来,给自己攒点人品,也希望大佬们指教~ 1,自我介绍(主要介绍了一段互联网电商运营实习) 2,在实习经历中有没有对某个指标进行分析,有无相关case经历? 答:没有(
-
 中金所暑期实习(数据分析)笔试内容
中金所暑期实习(数据分析)笔试内容综合能力测试: 1、言语理解与表达(10题) 2、判断推理(20题) 3、数字关系(10题) 4、资料分析(5题) 5、常识判断(10题) 专业测试: 1、单选题(20题) 2、不定选项题(8题) 3、简答题(2题) 4、算法题(2题)
-
 字节跳动-数据分析实习生-客服平台
字节跳动-数据分析实习生-客服平台一面(约50分钟) 1、自我介绍 2、详细说明工作经历做了什么,有什么成果即工作业绩 3、SQL用的最多的函数有哪些 4、窗口函数rank()、dense_rank()、row_number()的区别 4、两道SQL口述题目 一个表三列分别是:id,顾客的问题,对问题的回答 a)获得顾客问的最多的10个问题 b)获得每个顾客问的最多的10个问题 5、讲述ABtest的过程 6、怎么分析ABtest
-
 vivo数据分析实习面经以及入职攻略
vivo数据分析实习面经以及入职攻略不知不觉已经来到vivo一个多月,现分享下面经及入职攻略 lz坐标南京vivo大厦,岗位是数据分析实习生 首先介绍下timeline:4.18(boss上投递)-4.19约面(此时boss上已经关闭岗位)-4.23(一面)-4.25(hr面)-4.28(offer) 面经干货: 一面:有两位面试官,其中一位是当时boss上的对接人,后续入职知道,这位是数据团队负责人,另外一位是mentor。整个面
-
 拼多多25届数据分析笔试,估计凉了……
拼多多25届数据分析笔试,估计凉了……哎,应该很少有人笔试只做出来15分的75%吧。 15道单选,都是关于概率论的,基础牢不牢一做题就能感觉到。 显然,我基础不牢。 考的内容,有右偏,期望,方便,相关系数,计算概率,等。还有AB测试相关的。 一题4分,总分60分。 编程3道都是关于SQL的,分值分别是10分 15分 15分。 我做出来1道15分的,用例测试对了75%。怎么会75%呢,不理解。 还有一道题,感觉和having杠上了,没调
-
 三一重工-提前批-风电数据分析方向
三一重工-提前批-风电数据分析方向6月3技术面一面 读研期间做了什么项目? 数据采集用了什么软件? 基本流程是什么? 你方法的优势在哪里?
-
 百度数据分析面试2|提前批二面挂
百度数据分析面试2|提前批二面挂一面,7月17日,面试官是数据分析师 1. 自我介绍。 2. 实习中最有成就感的一段经历?实习经历深挖。 3. 使用过百度APP吗? 4. 知乎优缺点以及优化改进建议。 5. 对直播了解吗,直播为什么能吸引用户? 6. 对数据分析师的看法,以及自己的优势? 7. 某日APP日活突然下降,如何分析? 8. 数分相关硬技术如何? 9. 反问。 二面,7月30日,面试官是产品经理,两周后挂 1. 自我介
-
 百度数据分析面试1|日常实习两面
百度数据分析面试1|日常实习两面百度贴吧业务部数据分析日常实习两面 一面 1. 自我介绍。 2. 说一下SELECT FROM WHERE GROUP BY HAVING ORDER BY的执行顺序。 3. 说一下SQL和Hive SQL的不同。 4. 平常用SQL还是Hive SQL? 5. SQL题:①用户id,月份,销售额。计算每个月的用户数;截至当月的用户数;截至当月的销售额。②学生id,科目(语文、数学),成绩。计算语
-
 字节跳动数据分析面试7|四面已Offer
字节跳动数据分析面试7|四面已Offer电商方向的数据分析岗 一面,12月14日,30分钟 1. 自我介绍。 2. SQL题,10月销量排名前十的商品。 3. 抖音某主播要投放广告怎么计算ROI,如何衡量新客的价值(电商方向)? 4. 对抖音内电商各行业出一份2020年分析报告,用来指导2021年,你会怎么做? 5. 你觉得在抖音下的电商应该关注什么指标?(回答了GMV、复购率、购买转化率、退单率等,面试官说这是需求侧,问能不能说说供给
-
根据div大小调整字体大小
问题内容: 它由9个框组成,中间带有文本。我已经制作了框,以便它们可以随着屏幕大小的变化而调整大小,以便始终保持在同一位置。 但是,即使我使用百分比,文本也不会调整大小。 如何调整文本的大小,使其在整个页面上始终具有相同的比例? 这是处理多种分辨率的合适解决方案吗?还是我应该在CSS中进行很多检查并为每种媒体类型设置许多布局? ``` html, body { } #launchmain { }
-
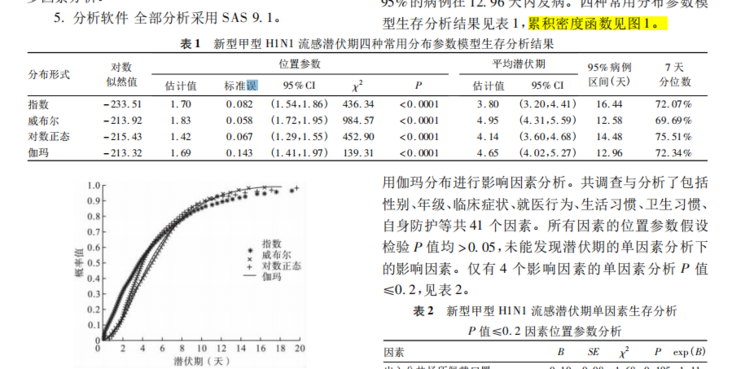 程序员 - SAS生存分析LIFEREG做区间删失数据的参数分布后,怎么求出结局变量的百分位数啊?
程序员 - SAS生存分析LIFEREG做区间删失数据的参数分布后,怎么求出结局变量的百分位数啊?SAS生存分析LIFEREG做区间删失数据(如潜伏期)的参数分布后,对于得到的各类参数分布模型,怎么估计潜伏期的百分位数呢? 比如这篇文献,右边的潜伏期百分位数数据怎么得到呀??? 还有参数分布的累积密度分布函数?/? 求大佬带带
-
整数太大
问题内容: 嗨,我很难理解为什么这不起作用 莫尔斯电码只是一串数字。问题是它说Integer number太大:4545454545,但是我确定Long可以更长。 问题答案: 您需要使用或将其限定为。默认情况下,是文字,超出的范围。 建议使用大写字母以避免混淆,因为和看起来很相似 你可以做 : 要么 根据JLS 3.10.1 : 如果整数文字 以ASCII字母L或l(ell) 为后缀,则其类型为l
-
大菲波数
题目描述 斐波那契数列是这样定义的:f(1)=1;f(2)=1;f(n)=f(n-1)+f(n-2)(n>=3)。所以1,1,2,3,5,8,13……就是斐波那契数列。输入一个整数n,求斐波那契数列的第n项。 输入格式: 首先输入一个正整数T,表示测试数据的组数,然后输入T组测试数据。每组测试数据输入一个整数n(1≤n≤1000)。 输出格式: 对于每组测试,在一行上输出斐波那契数列的第n项f(n
-
大数运算
大数取模 取模运算的性质 因为 (a%n) - (b%n) 可能小于 n,所以 +n 因为 (a%n)(b%n) 可能溢出,计算前应该强转为 long long Code - C++ 输入 a 为长度小于 1000 的字符串,b 为小于 100000 的整数 int big_mod(const string& a, int b) { long ret = 0; // 防止 ret * 1
-
使用分页处理大量数据库条目会随着时间的推移而变慢
问题内容: 我正在尝试处理表中的数百万条记录(大小约为30 GB),目前正在使用分页(mysql 5.1.36)进行处理。我在for循环中使用的查询是 对于大约50万条记录,这完全可以正常工作。我正在使用的页面大小为5000,在第100页之后,查询开始显着放缓。前约80页在2-3秒内提取出来,但在第130页左右之后,每页检索大约需要30秒,至少直到200页为止。我的一个查询大约有900页,这将花费