
程序员 - SAS生存分析LIFEREG做区间删失数据的参数分布后,怎么求出结局变量的百分位数啊?

SAS生存分析LIFEREG做区间删失数据(如潜伏期)的参数分布后,对于得到的各类参数分布模型,怎么估计潜伏期的百分位数呢?
比如这篇文献,右边的潜伏期百分位数数据怎么得到呀???
还有参数分布的累积密度分布函数?/?
求大佬带带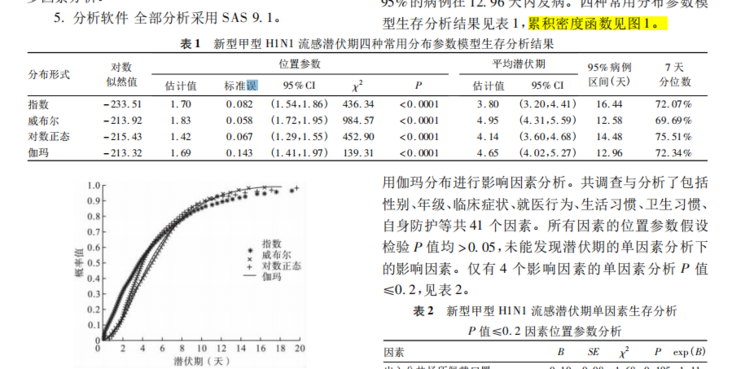
共有1个答案

计算生存时间的25%,50%和75%百分位数,可以用:
proc lifereg data=your_data;
model y*c(0)=x1 x2 x3 / d=weibull;
output out=outdata quantile=(0.25 0.50 0.75);
run;累积密度函数(CDF),你可以用生存函数(S)来算:
CDF(t) = 1 - S(t)
在Weibull分布里,生存函数的公式:
S(t) = exp(-λt^p)
-
本文向大家介绍你是怎么做数据分析的?相关面试题,主要包含被问及你是怎么做数据分析的?时的应答技巧和注意事项,需要的朋友参考一下 考察的是数据分析的能力。主要从以下4个维度回答,结合具体的数据分析来进行阐述: 明确数据分析的目的; 确定数据分析的方法以及获取所需要的数据; 对数据进行预处理,并进行分析; 输出数据分析报告,提出相应建议。
-
匹配可以用来解析简单的参数: use std::env; fn increase(number: i32) { println!("{}", number + 1); } fn decrease(number: i32) { println!("{}", number - 1); } fn help() { println!("usage: match_args <stri
-
spark如何在使用< code>orderBy后确定分区的数量?我一直以为生成的数据帧有< code > spark . SQL . shuffle . partitions ,但这似乎不是真的: 在这两种情况下,spark都< code >-Exchange range partitioning(I/n ASC NULLS FIRST,200),那么第二种情况下的分区数怎么会是2呢?
-
null 假设我有100张唱片。缓存只能保存40条记录(最常用)和100条记录在磁盘文件(不在任何其他数据库中)。 所以,如果从这100条记录中请求任何东西,我就不必去实际的数据库(例如Sybase db)? 如果在100条记录中找到了密钥,但它不存在于内存缓存中(40条记录),则获取该密钥,放入内存缓存中,并使用驱逐策略将其他密钥交换到磁盘文件中(但在磁盘上,我总是有100条记录) 如果缓存和磁
-
本文向大家介绍java中成员变量与局部变量区别分析,包括了java中成员变量与局部变量区别分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了java中成员变量与局部变量区别。分享给大家供大家参考。具体分析如下: 成员变量:在这个类里定义的私有变量,属于这个类。 创建以及使用成员变量 成员变量初始化过程 一、类的初始化 对于类的初始化:类的初始化一般只初始化一次,类的初始化主要是初始化静态
-
本文向大家介绍数据科学家,数据工程师,数据分析师之间的区别。,包括了数据科学家,数据工程师,数据分析师之间的区别。的使用技巧和注意事项,需要的朋友参考一下 数据科学家,数据工程师和数据分析师是信息技术公司中的各种职位档案。 数据科学家 数据科学家是一个非常特权的工作,负责监督整体功能,提供监督以及对信息,数据的未来显示的关注。 数据工程师 数据工程师专注于技术优化,以所需格式构建数据等。 数据分析