《数据分析师面经》专题
-
 两年经验-不知名小公司-数据开发工程师-面经
两年经验-不知名小公司-数据开发工程师-面经在现公司干得有点憋屈,想跑路了,得先找一下感觉,看差点啥,再补补,明年拿了年终就可以跑了。 一上来,不多说,自我介绍。 然后介绍项目,介绍完开始抠细节: 1、团队多少人?数据量多少? 2、业务调研怎么做的? 3、如何确定主题域的? 4、怎么分层的? 5、为什么这么分层? 6、各个表抽取策略是怎样的?如何确定增量抽还是全量抽? 7、数据质量怎么保证的? 8、数据开发规范是怎么样的? 9、任务是怎么调
-
 电信智科-大数据开发运营工程师(成都base)面经
电信智科-大数据开发运营工程师(成都base)面经电信智科(中国电信股份有限公司数字智能科技分公司)-大数据开发运营工程师面经 9月1日投的,15日笔试,26日一面。这个公司是在国聘行动上投递的,在成都就这一个岗位,本来没抱希望投的,结果没想到还给面试了。面试在腾讯会议上的,一共25分钟左右,比较短;感觉有点凉,像kpi面,我准备了kafka的很多八股,结果一个没问,一直在怼网络,感觉有点像kpi面试。 以下回答绝大部分是GPT4.0回答
-
分析
StackExchange.Redis公开了一些方法和类型来启用性能分析。 由于其异步和多路复用 表现分析是一个有点复杂的主题。 接口 分析接口由 IProfiler, ConnectionMultiplexer.RegisterProfiler(IProfiler) ,ConnectionMultiplexer.BeginProfiling(object) , ConnectionMultipl
-
分析
分析支持从平台、账号、区域、项目、计费模式、时间以及标签等角度综合分析不同条件下的消费趋势等信息。 云账号 以云账号的维度查看云账号的费用分析情况。 平台统计 平台统计用于统计不同平台的消费趋势以及平台下不同云账号、资源、资源类型、项目、区域、计费模式的消费金额及比例。 域 以域的维度展示每个域的费用分析情况。 项目 以项目的维度展示每个项目的费用分析情况。 标签 以标签的维度展示每个标签的费用分
-
分布分析
1. 简介 分布分析报告可以帮助您查看事件在不同区间的发生频次,从而判断用户的使用习惯和活跃情况。除了次数,您还能够查看其它事件指标的用户数量分布。 分布分析能够帮助您洞察这些问题: · 对比不同来源渠道的用户在站点的行为次数分布,如浏览页面1-3次,3-10次,10次以上,不同区间的用户数量有多少 · 上周推广活动客单价的人数分布情况 · 改版后,用户的每日启动次数是否增加 2. 使用说明 2.
-
 【春招】多益网络用户研究分析师-笔试
【春招】多益网络用户研究分析师-笔试楼主大四,数据科学与大数据技术专业,目前找工作中,岗位数据分析,除了一份简历笔试什么都没准备反正。 虽然有过一段数分实习,但这确实是楼主第一次做笔试题,同时对游戏公司不太感兴趣,看了友友分享的帖子,这家公司也emm...所以这次笔试就当长一下见识吧,记录一下需要的友友可以看看。 笔试分为三部分:综合选择、费米估算、业务问答。 综合选择:感觉全是统计学的知识,正态、分布、计算反正就是统计学的,楼主大
-
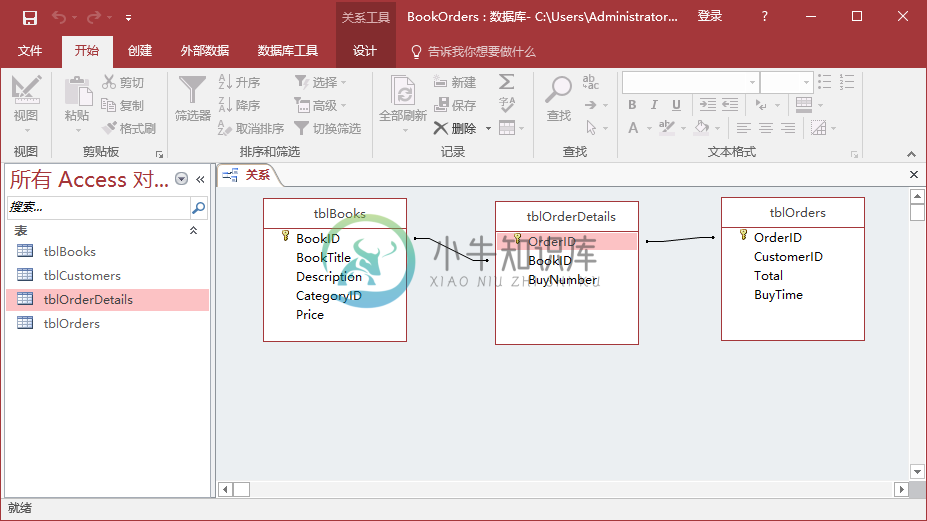 Access分组数据
Access分组数据主要内容:聚合查询,Access中的连接,示例在本章中,我们将介绍Access中如何计算如何分组记录。 我们创建了一个按行计算或按记录计算的字段来创建行总计或小计字段,但是如果想通过分组记录而不是单个记录来计算,那该怎么办呢? 可以通过创建聚合查询来实现这一点。 聚合查询 聚合查询也称为总计或汇总查询是总和,质量或组的详细信息。它可以是总金额或总金额或记录的组或子集。 聚合查询可以执行许多操作。下面是一个简单的表格,列出了分组记录中总的方法。
-
hazelcast数据分布
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
数据集拆分
在机器学习中,通常将所有的数据划分为三份:训练数据集、验证数据集和测试数据集。它们的功能分别为 训练数据集(train dataset):用来构建机器学习模型 验证数据集(validation dataset):辅助构建模型,用于在构建过程中评估模型,为模型提供无偏估计,进而调整模型超参数 测试数据集(test dataset):用来评估训练好的最终模型的性能 不断使用测试集和验证集会使其逐渐失去
-
 百度 机器学习/数据挖掘/自然语言处理工程师 一面面经
百度 机器学习/数据挖掘/自然语言处理工程师 一面面经面试岗位:机器学习/数据挖掘/自然语言处理工程师 面试时间:23/08/14 面试时长:50min 面试内容: 自我介绍 介绍两段实习经历 熟悉哪些机器学习/深度学习/搜广推算法 两道代码题:寻找两个正序数组的中位数;根据字符出现频率排序;(力扣原题) 反问:部门业务;对新人期待/要求:学习能力强、基础:Python离线模型开发、C++在线开发; 总结:面试官对面试者的研究背景较为包容开放,为人和
-
 UI设计师面试常见问题分享
UI设计师面试常见问题分享下面是我每个环节面试碰到的一些问题,因为每个公司那个面试官都有自己的面试方法和逻辑,我整理的这些内容也只是我碰到的,希望能对大家有所帮助, 第一轮: 1、 先做一下自我介绍 2、 为什么从上家公司离职/为什么想要离职? 3、 你的设计是怎么解决发现的问题的? 4、 你们是怎么判定这次改版是成功的? 5、 如果要判定这次成功该怎么打点,看什么数据? 6、 这个项目是你独立完成的吗?你在这个项目中的角
-
 算法工程师面试面经 | 经典分类网络与发展
算法工程师面试面经 | 经典分类网络与发展专栏地址:http://t.csdnimg.cn/HAbwF pipeline:LeNet-5->AlexNet->Network in Network->VGGNet->GoogLeNet->ResNet->Inception->DenseNet->Inception->MobileNet->ShffleNet->SENet 4.1 AlexNet AlexNet模型有以下特点: 1. 所有卷积
-
大数据工程师技能图谱
大数据通用处理平台 Spark Flink Hadoop Drill 分布式协调 ZooKeeper 分布式存储 HDFS Alluxio(tachyon) Ignite 存储格式 Parquet ORC CarbonData Kudu 数据库 HBase 资源调度 Yarn Mesos Kubernetes 工作流调度 Oozie Azkaban 机器学习工具 Mahout Spark Mlib
-
 携程 数开 校招 数据研发工程师 凉经
携程 数开 校招 数据研发工程师 凉经一面(2023.9.15) 11点开始,11点41分结束 面试官很和蔼,不过周围有点吵。(面试官叫王xx,我不太记得了,人挺好的) 自我介绍 实习项目介绍(我这真是面出经验了,只要你项目他不感兴趣,接下来就是八股时间) 学校里有什么课程 八股问的多到离谱,总共就30分钟不到,全八股。 int和Integer有什么区别? Integer(200) new 两次,他们是一样的吗? valueOf方法介
-
 美团商业分析面经 2022秋招
美团商业分析面经 2022秋招美团买菜 30min 一面 20220822 1.自我介绍 2.两个商业case: (1)估算2022年北京医美市场销售额 (2)估算海南免税店2023年营业额 (3)估算滴滴2025年巴西乘客人数 PS:本来两个,因为前两个都回答不出来,换成了第三个 3.实习深挖 (1)滴滴周报:哪些指标、哪些数据要自己取、哪些要合作 (2)怎么给运营或产品提供数据 (3)什么指标更重要?为什么?如何提高