《欢聚时代》专题
-
 利用K均值聚类精确检测图像中的颜色区域
利用K均值聚类精确检测图像中的颜色区域我在基于颜色的图像分割中使用了K-均值聚类。我有一个2D图像,它有3种颜色,黑色,白色,和绿色。这是图像, 我想让K-means产生3个簇,一个代表绿色区域,第二个代表白色区域,最后一个代表黑色区域。 这是我使用的代码, 但我没有按要求得到结果。我得到一个带有绿色区域的簇,一个带有绿色区域边界的簇,还有一个带有灰色、黑色和白色的簇。下面是产生的集群。 这样做的目的是,在得到正确的聚类结果后,我想利
-
Google chrome使用jQuery选项卡“无效的表单控件不可聚焦”
我创建了一个表单,它使用jQuery拆分为许多“选项卡”;以及在各个选项卡中找到的字段。 表单中的所有字段都已检查到位,有些是必填字段,有些必须有最小值,等等。 null 这里你可以找到我所描述的一个例子,尽管它比实际的表单要简单得多,但如果你将它加载到Google Chrome中并立即提交表单,你就会在控制台中看到错误。
-
在嵌套数组mongoose中仅返回第一个匹配键的聚合
我有一个如下的猫鼬模式: 我已经获取了所有具有给定id的特定用户发表评论的帖子,即所有那些评论数组中包含uid等于给定uid的对象的文档。例如,假设用户id为101,则查询结果可能如下所示: 为了更好地理解一切,我想获取所有那些特定用户评论过的帖子,甚至回复过的帖子,以及只有该用户的评论和回复。 我所能做的就是: 此查询仅返回相应帖子的第一个匹配的评论项数组。我想要所有符合条件的物品。 请帮助我为
-
线程“main”org.openqa.selenium.WebDriverException中出现异常:未知错误:无法聚焦元素
我一直试图使用Selenium sendkeys(),但没有成功使用Chrome。我在这里研究过类似的问题,但似乎没有成功。我可以生成URL,调用按钮(click()),但是当我试图在特定的文本字段中输入值时,我会得到: 线程“main”org.openqa.selenium.WebDriverException中出现异常:未知错误:无法聚焦元素。
-
spring-integration并行分裂路由聚合流由于单向MessageHandler而失败
我希望通过拆分项目、将每个项目路由到相应的网关并聚合结果来并行处理项目列表。但是,我的应用程序没有启动,我得到以下错误: 这是一个示例流定义,它说明了行为: 我看到Error'是spring-integration aggregator DSL的单向'MessageHandler',但是这里的解决方案不适用,我没有登录handle()方法。我还试图将。DefaultOutputToparentFl
-
Java流:在列表中聚合map()中接收的所有非空集合
我有包含字符串ID的集合idList。函数getCollection返回单个ID项的集合(类型为MyType)。此外,它可能返回null。 所以对于idList中的许多id,我会得到一些null和一些集合。 目标是收集getCollection对一组ID的所有回复到最终列表中。 我想象过 但它似乎不是一个有效的表达式。如何使它有效? 另外,这个实现的性能如何?
-
小精灵查询:如何添加包含聚合信息的多条边?
我的图包含一些“个人”节点,这些节点“参与”了一些“对话”节点。我想编写一个小精灵查询,它将直接在“Person”节点之间创建“TalksWith”边缘。该边缘应包含一个属性“countConversations”,显示这两个人参与了多少对话。 这是否可能同时对所有“Person”节点使用一个小精灵查询? 这是我的图形设置(使用Gremlin控制台): 我想做的是创建这样的“TalkedWith”
-
必须出现在GROUP BY子句中或在聚合函数中使用
我有一张桌子看起来像这个叫“Makerar”的人 并且我要为每个CNAME选择最大平均数值。 所以我这样做 然而,这将不会给出预期的结果,并且下面显示了不正确的输出。 实际结果应该是 我如何解决这个问题? 注意:此表是根据以前的操作创建的视图。
-
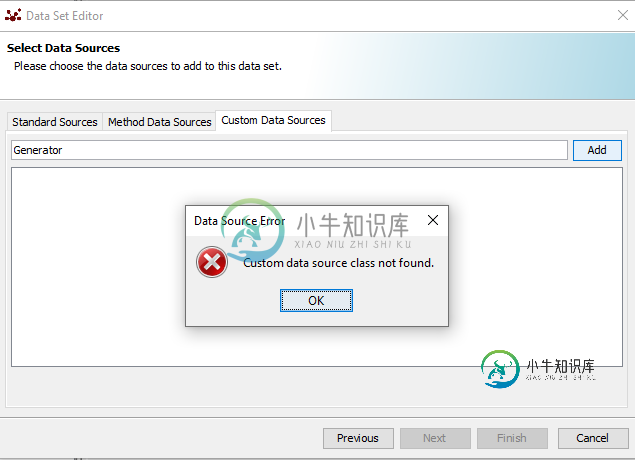 Repast聚合数据集,但在Repast Simphony中分别针对每个实例
Repast聚合数据集,但在Repast Simphony中分别针对每个实例我正在使用Repast Simphony框架进行模拟。假设我有以下类: 然后我创建了这个类的几个实例,将它们添加到上下文中并运行模拟: 是否有任何方法可以收集聚合数据,但对于类的每个实例分别?我想找出每个生成器的所有生成值的平均值,因此输出统计信息应采用以下格式: 如果我使用方法数据源创建新的聚合(均值)数据集并重复每个刻度,我会得到大量的值列表: 其中每个值都是平均值,但所有生成器的指定刻度值的
-
Jackson模块处理Spring Data REST中的抽象聚合根及其子类
Spring Data REST将存储库导出为REST资源,您可以在http://localhost:8080/api/criterial/上访问它 导出的资源如下所示: 当我尝试跟踪self链接时,没有http://localhost:8080/api/namecriterion/1的映射 换句话说,我应该创建什么Jackson模块?
-
在MondoDB聚合中没有特定字段的筛选器数组元素
我在mongodb中有一个集合,如下所示。 MongoDB版本:4.0.13
-
对某些默认标记使用@Timed聚合的直方图存储桶
我正在为超文本传输协议请求启用直方图,所以我可以在普罗米修斯中使用histogram_quantile。 所以我配置了,并且还设置了最小期望值和最大期望值,以防止存储桶过多,并尝试减少基数。 默认情况下,spring boot为@RestController(异常、方法、结果、状态、uri)设置以下WebMvc标记。例如,对于http_服务器_请求_秒数_计数指标来说,这是非常有用的。 然而,对于
-
如何用数组字段将文档流聚合成单个文档?(mongodb)
我有这个数据集: 我想用聚合来实现这种形式: 其中文档流组合成单个文档内的单个数组字段,我想在其中添加一些额外的字段。初始数据集在聚合管道中的第n个阶段后检索。 鉴于所有这些: 下一阶段应该是什么? 我需要$group吗? 我的下一阶段应该是什么样子?
-
我如何确保我的聚合过滤出过期的mongo子文档?
我想计算当前活动的resetPassword(用户架构中的子文档)代码数。要激活代码,其到期日期必须大于当前日期。 这是我的用户模式。如果有人请求重置密码,我们将把一个新的对象推送到数组中。 我在尝试对活动重置代码的总数求和时遇到问题。下面是我正在运行的查询,它返回一个空数组。。。请注意,如果要删除match节,它将返回所有代码。我试着将这个匹配语句移出初始阶段,然后进行放松 这将返回一个空数组,
-
带有QueryDSL的Spring数据JPA,带有聚合函数的计数问题
我正在使用查询DSL的Spring数据JPA,并试图在条件中使用求和函数,因为我正在使用分页,所以我必须首先获得计数。所以我有如下的Java代码:- 它创建这样的查询:- 我得到。 上述查询在中也不起作用,因为sum函数不能与count-in-where条件一起使用。当我必须先进行计数,然后再获取真实数据时,我不知道如何处理这样的问题。有人能帮我解决这个问题的方法吗。 请不要建议注释,因为我不能使