《欢聚时代》专题
-
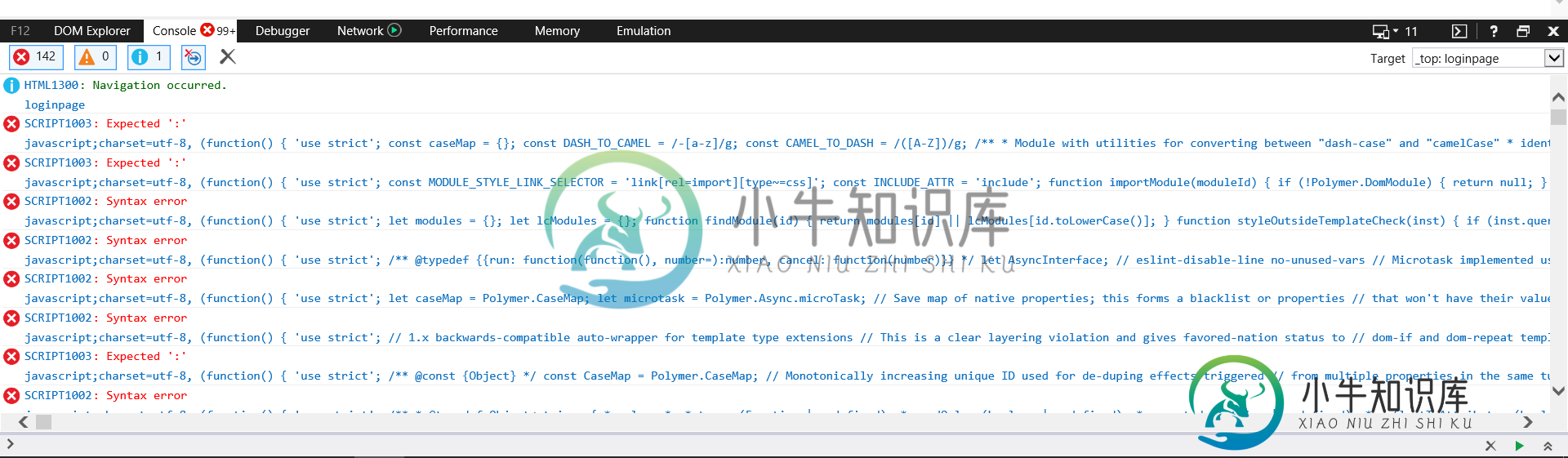 天蓝+聚合物2的应用:在铬上工作而不是在IE上
天蓝+聚合物2的应用:在铬上工作而不是在IE上null 只在Chrome和FireFox中开箱即用,不在IE中工作(空白页,没有错误)。我在DOM Explorer中看到的是app元素没有加载:它显示为 我还试图在Cloud Shell控制台上安装全球范围内的polymer-cli,重新启动应用程序服务,但没有成功。 在index.html文件中,相关部分是通常的包含: 最后一件事:如果我在本地主目录和本地目录上运行,那么每个人都在IE上工作
-
在Excel(XLSX)中聚焦并确认公式后,才计算公式单元格
因此,我使用Apache POI(在最新的稳定版本5.0.0中使用poi-ooxml),并打开一个现有的Excel(XSLX)文件进行编辑(它基本上是一个模板文件,用于填充其他数据)。我添加了多行新数据并再次导出Excel。所有的工作都很好,只要我只添加规则的内容单元格。 现在,我有一列想要添加一个公式单元格,我使用以下代码(对于本例,您可以放心,它通常编译/运行并在末尾生成一个填充的Excel文
-
是否可以将“查询”与“聚合”和“分组依据”组合(结果集)?
问题内容: 1个 结果集 : 2个 结果集2: 有没有办法可以做到这一点: 我想在RHEL 5上使用Sybase 12.5的解决方案,我也想知道在其他任何数据库系统中是否可行。 -–谢谢您的回答- 问题答案: 通过为该列使用CASE / WHEN并基于true / false求和1或0,您可以在同一查询中获得这两者。此外,如果您希望将另一个值的总和作为另一个,则可以执行相同的操作列…只需将其替换为
-
Java流按02个字段分组,并按2个BigDecimal字段的和聚合
需要帮助的一个案件流与分组由我希望能够分组由2个不同的字段,并有其他大小数字段的总和,根据不同的分组。以下是我的实体: 让我们假设我有以下列表作为输入: 下面有一个解决方案的开头,但我在添加第二个聚合来总结余额的时候阻止了:
-
在聚簇索引上使用顺序GUID键的INSERT不会明显更快
问题内容: 在SQL Server 2008中,我尝试重现来自顺序索引和非顺序GUID密钥的聚集索引的实验结果,此处的 http://sqlblog.com/blogs/denis_gobo/archive/2009/02/05/11743。 aspx, 但我并没有体验到我期望的(和作者所体验到的)插入速度的显着提高。顺序GUID明显提高了页面利用率,但是由于某些原因,插入10,000行仅快100
-
流利的NHibernate:如何在多对多联接表上创建聚簇索引?
问题内容: 为了在SQL Azure上使用Fluent NHibernate映射,我需要在每个表上都有一个聚集索引。Fluent NHibernate为多对多联接创建的默认堆表显然不这样做,因为它们没有主键。 我希望能够告诉关系的一方为其连接表创建聚簇索引,但是我不确定如何。这是我的映射的样子: 如果您需要更多信息,请告诉我! 问题答案: 我不知道Fluent是否直接支持它(如果不支持,只需包含x
-
Maven Javadoc聚合jar插件由于未解析的依赖关系而失败
我有一个多模块Maven项目,在这个项目中,我运行Maven javadoc插件来生成javadoc。在我的父母pom。xml我对插件构建的定义如下: 当我运行mvn clean install时,生成会失败,并存在未解决的依赖项,但我看到以下警告: [警告]无法解析依赖项:[我的应用程序:我的模块:jar:1.7.1],但已在反应器中找到(可能是快照)。此依赖项已从Javadoc类路径中排除。您
-
API网关模式与聚合器模式(在微服务的上下文中)
我正试图理解API网关和微服务聚合器模式之间的区别。 目前,从我对聚合器模式的理解来看,它是通过从各种微服务收集数据片段并返回一个聚合进行处理来实现的。 现在,API网关是聚合对单个微服务的调用的单一入口点。虽然这听起来可能与聚合器模式非常相似,但也有一些不同的特性。最重要的是,这个新服务不存储数据,而是负责API组合、请求路由和身份验证等新功能 我很想知道我的推理是否正确。 提前谢谢你!
-
如何将数组传递给Spark(UDAF)中的用户定义聚合函数
我想在UDAF中传递一个数组作为输入模式。 我给出的例子非常简单,它只是对2个向量求和。实际上我的用例更复杂,我需要使用UDAF。 在“显示”动作之前,所有这些都可以很好地进行转换。但这部剧引发了一个错误: 斯卡拉。MatchError:[WrappedArray(21.4,24.9,22.0)](属于org.apache.spark.sql.execution.aggregate.InputAg
-
利用并行性生成有序窗口聚合(例如,前10个查询)
我正在尝试利用并行性来加速一个前10位的窗口操作。我的应用程序由具有时间戳和键和(即)的事件组成,我的目标是为30分钟的滚动窗口生成前10个最频繁的键(使用事件时间)。为此,我的查询由一个入口、一个窗口和一个聚合阶段组成。换句话说,我的代码将需要执行类似以下内容的操作: 以上是从一个CSV文件解析数据并分配事件时间(即入口)的代码。我将并行性设置为1的原因是,我需要事件按顺序显示,以便将它们分配给
-
 多行聚合ItemReader不按照Spring批处理样本中的建议工作
多行聚合ItemReader不按照Spring批处理样本中的建议工作我正在尝试使用多行IteamReader来跟踪spring批处理示例https://github.com/spring-projects/spring-batch/tree/main/spring-batch-samples#multiline 我遇到如下编译错误- 我确信有一些与泛型相关的东西,因为它在寻找实现ItemReader的类,但是Aggregate ItemReader实现了ItemR
-
HibernateOGM MongoDB聚合查询不工作与JPA setFirstResult和setMaxResult,而下一个执行
我正在使用Hibernate OGM(5.2.0.Alpha1)和MongoDB(3.4) 在我行刑的时候 String query=“db.student.find({'collegeName':'VNSGU'})” 对于使用JPA setFirstResult()和setMaxResult()进行分页,它可以正常工作,但在执行聚合查询时 String query=“db.student.agg
-
DART-聚合物单元测试。单击事件后无法引用dom元素
总是失败,即使在div中也是null。 代码: Hi Günter,谢谢你的时间,我根据你的意见调整了我的代码,它应该可以工作,但我认为我是搞砸了我使用聚合物模板的方式。
-
AWS EMR上的纱线日志聚合-不支持的文件系统异常
我正在努力为我的Amazon EMR集群启用YARN日志聚合。我正在按照这个配置留档: http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/emr-plan-debugging.html#emr-计划调试日志存档 在标题为“使用AWS CLI聚合Amazon S3中的日志”的部分下。 我已经验证了hadoop-conf
-
 如何将微服务的招摇过市聚合为一个招摇过市
如何将微服务的招摇过市聚合为一个招摇过市我试图在我的微服务项目中生成一个单独的招摇过市,在Api网关中将所有服务招摇过市聚合成一个单独的招摇过市。为了实现这一点,我将遵循下一个教程https://objectpartners.com/2017/09/28/aggregate-services-into-a-single-swagger 这里的问题是,当我尝试设置绝对URL时,我收到的输出是未能加载API定义。未定义的http://loc