《欢聚时代》专题
-
获取时数与时差的时差
问题内容: 我想通过Node.js矩模块获得纽约和香港之间的时差。我已经做了一些初步的工作。 然后,我可以继续编写一个函数,以小时为单位计算两个时区之间的时差。我希望有一个更简单的方法。 矩型库中有更优雅,更简单的方法吗? 问题答案: 不确定“更简单”,但更正确(因为并非所有时区都相隔一个小时):
-
1小时时差夏令时问题
函数获取用于本地设备转换的简单日期格式: 产出: 日期=2018-04-22 14:30 上面的示例是基于伦敦时区的,而当我们在IST时区中尝试时,它返回的是正确的时间。 我们通过检查时区的函数来处理不同的DST时间,但它不起作用。 我肯定与夏令时有关,但我不明白。谢谢你的帮助?
-
sqlite时间戳转时间语句(时间转时间戳)
本文向大家介绍sqlite时间戳转时间语句(时间转时间戳),包括了sqlite时间戳转时间语句(时间转时间戳)的使用技巧和注意事项,需要的朋友参考一下 下面是具体的实现代码:
-
 js实现的奥运倒计时时钟效果代码
js实现的奥运倒计时时钟效果代码本文向大家介绍js实现的奥运倒计时时钟效果代码,包括了js实现的奥运倒计时时钟效果代码的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了js实现的奥运倒计时时钟效果代码。分享给大家供大家参考,具体如下: 运行效果截图如下: 具体代码如下: 希望本文所述对大家JavaScript程序设计有所帮助。
-
Spring kafka NonResponsiveConsumerEvent甚至在代理关闭时触发时间
我让消费者在我的机器上运行。当我停止Kafka broker时,我在应用程序中得到警告 但是在2-4分钟后被触发。根据此文档 https://github.com/spring-projects/spring-kafka/blob/master/src/reference/asciidoc/kafka.adoc#idle-containers 它说“如果轮询未在 pollInterval 属性的
-
 JavaScript实时更新当前的时间的示例代码
JavaScript实时更新当前的时间的示例代码本文向大家介绍JavaScript实时更新当前的时间的示例代码,包括了JavaScript实时更新当前的时间的示例代码的使用技巧和注意事项,需要的朋友参考一下 实现的效果如下: 时间会实时更新 具体的JS代码如下 在控制台上可以实时的打印出当前的时间和星期 ps:js获取当前时间并实时刷新 效果如图: 代码如下: 到此这篇关于JavaScript实时更新当前的时间的文章就介绍到这了,更多相关js
-
在java代码中使用EST时区时的DST[副本]
-
如果处理了内部路由中的异常,则不执行具有聚合策略的Splitter后的代码(Apache Camel)
我面对过我无法理解的行为。执行“聚合策略”拆分时,会发生此问题,并且在其中一次迭代期间发生异常。在另一个路由(每次迭代调用的直接终结点)中,拆分器内部发生异常。似乎路由执行在拆分器之后停止。 下面是示例代码。 这是一个路由,每个客户端生成一个报告,并收集文件名称以进行内部统计信息。 AggregationStrategy非常简单,它只提取文件名。如果没有标头,则返回NULL。 当分割后一切顺利时,
-
针对你最喜欢的一位歌手或艺人设计一份采访提纲,不少于10个问题
本文向大家介绍针对你最喜欢的一位歌手或艺人设计一份采访提纲,不少于10个问题相关面试题,主要包含被问及针对你最喜欢的一位歌手或艺人设计一份采访提纲,不少于10个问题时的应答技巧和注意事项,需要的朋友参考一下 讳莫如深最喜欢的艺人是主持人 崔永元。 提纲如下: 采访对象:国内资深节目主持人崔永元 采访目的:深入了解 实话实说背后的勇气和魄力 采访问题: 崔老师的睡眠障碍精神抑郁好些了吗?是如何会有这
-
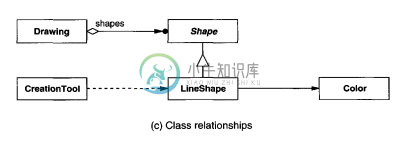 多个对象是否可以聚合、熟悉或实例化同一个对象?
多个对象是否可以聚合、熟悉或实例化同一个对象?Gamma等人所说的设计模式 考虑对象聚合和熟悉之间的区别,以及它们在编译和运行时的表现方式。 聚合意味着一个对象拥有或负责另一个对象。一般来说,我们所说的一个物体具有或是另一个物体的一部分。聚合意味着聚合对象及其所有者具有相同的生存期。 熟人关系意味着一个对象仅仅知道另一个对象。有时熟人关系被称为“关联”或“使用”关系。熟人对象可能会请求彼此的操作,但它们并不对彼此负责。熟人关系比聚合关系弱,表
-
配置Spring集成聚合器以组合来自RabbitMq扇出交换的响应
我正在尝试使用Spring集成配置以下内容: 向频道发送消息。 将此消息发布到与 n 个使用者的兔子扇出(发布/订阅)交换。 每个使用者都提供一条响应消息。 让 Spring 集成聚合这些响应,然后再将它们返回给原始客户端。 到目前为止,我有一些问题。。。 > 我使用发布订阅通道来设置属性,以便correlationId、sequenceSize sequenceSize 属性仅设置为 1,即使在
-
聚合器,它根据相关性释放部分组,但保留其余消息
我想在聚合器上设置相关策略,以便它使用传入文件(作为消息)名称之外的日期来关联文件,以便所有具有今天日期的文件都属于同一组。现在,由于我可能有多天的数据,我可能已经聚合了2天的文件。我想把发布策略建立在一个已完成的文件(消息)的基础上,该文件包括文件名中的日期,因此基本上每天都会有一堆文件和一个已完成的文件。摄取完成的文件应该从聚合器中释放当天的文件,但仍然保留其他日期的文件,直到摄取当天的完成文
-
如何将聚合函数应用于从Google BigQuery中的JSON提取的数据?
问题内容: 我正在使用从BigQuery列中提取JSON数据。现在,我要提取值列表并对其运行汇总函数(如)。在http://jsonpath.curiousconcept.com/上测试JsonPath表达式成功。但是查询: 在BigQuery上引发 JsonPath解析错误 。 在BigQuery上可能吗? 还是我需要预处理数据以便对JSON内部的数据运行聚合函数? 我的数据看起来像这样: 更新
-
在Access 2007 SQL中按聚合功能对分组中的差异进行计数
问题内容: 您好,我浏览了一段时间的论坛,并在这里问我的第一个问题。我有点束手无策,想知道是否能得到一些帮助。我正在使用Access 2007,但尚未在网上找到一个很好的答案。 我的数据是诊断代码和客户ID,而我正在寻找的原因就是为什么要为每个诊断代码找到不同的客户ID计数。理想情况下,在非Access SQL中,它看起来应该像这样: 我知道这是一个非常简单的问题,但是我发现的答案太复杂(多个聚合
-
Django Rest Framework序列化程序中的聚合(和其他带注释的)字段
问题内容: 我正在尝试找出将带注释的字段(例如任何聚合的(计算的)字段)添加到DRF(模型)序列化器的最佳方法。我的用例仅是端点返回未存储在数据库中但从数据库计算出的字段的情况。 让我们看下面的例子: models.py serializers.py 所需的JSON输出: 我有几个可行的解决方案,但是每个解决方案都有一些问题。 选项1:为模型添加吸气剂并使用SerializerMethodFiel