《欢聚时代》专题
-
kafka中每个聚合根事件的单个或多个主题(流)
-
Google chrome使用jQuery选项卡“无效表单控件不可聚焦”
我已经创建了一个表单,它使用jQuery被拆分为许多“选项卡”;以及在各个选项卡中找到的字段。 表单中的所有字段都有相应的检查,有些字段是必需的,有些字段必须具有最小值,等等。 但是,当我尝试提交一个在字段中包含无效值的表单时,如果这些字段位于不同于当前选项卡的选项卡下,我会在控制台上从GoogleChrome得到一个错误: 无效的表单控件不可聚焦 但用户看不到任何效果,也找不到错误的字段,因为浏
-
Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?
本文向大家介绍Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?相关面试题,主要包含被问及Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?时的应答技巧和注意事项,需要的朋友参考一下 Elasticsearch 提供的首个近似聚合是 cardinality 度量。它提供一个字段的基数,即该字段的 distinct 或者unique 值的数目。它是基于 HLL 算
-
弹性搜索嵌套聚合-文档中的方法不起作用
我是ES新手,正在努力解决嵌套聚合问题。这是我的虚拟数据对象([这是我的数据对象][1][1]:https://i.stack.imgur.com/X7oaM.png). 我只是想把“现代”领域的成本降到最低。 我已经阅读了以下关于我试图解决的问题的帖子。他们都没有帮助我解决问题 -弹性搜索6嵌套查询聚合-https://www.elastic.co/guide/en/elasticsearch/
-
使用聚合结果构造示例SearchResponse对象以进行测试
我想创建一个带有聚合结果的searchResponse对象以进行测试。 我尝试了以下方法 这里的第一个参数用于我不想要的点击,但第二个参数接受聚合。 现在,我无法使用bucket创建自定义聚合对象。 测试代码如下: 我还尝试使用Json创建SearchResponse,如下所示: 我使用以下json调用getSearchResponse(json)方法: 并获取ParseException:[无法
-
设置Flink应用程序与多个不同的SQL查询(聚合)
我需要使用来自同一来源的不同列聚合构建管道,例如,一个按userId,另一个按productId,等等。我还希望有不同的颗粒度聚合,例如按小时、每天。每个聚合将有不同的接收器,例如不同的nosql表。 使用表API构建SQL查询似乎很简单。但我想减少管理太多Flink应用程序的操作开销。所以我想把所有不同的SQL查询放在一个pyflink应用程序中。 这是我第一次创建Flink应用程序。所以我不确
-
用于文本字段数组中聚焦文本字段的JavaFX-getter
我在寻找一种方法来放弃我的程序中的一个getter。我有一堆动态创建的文本字段: 下面是getter,我想在这里返回聚焦的TextField 处理程序将接收聚焦字段并调用我的“model”-class中的checkInput()方法。 此刻,它接收到一个由我自己设置的预定义字段。检查答案的代码有效。感谢任何帮助我的人,如果我自己找到了一个方法,我一定会把它贴在这里。
-
获取更多字段,而不是Elasticsearch聚合中的唯一字段
我是Elasticsearch的新手,我的程序有问题。 为了将结果分组,如SQL中的“group by”语句。我使用了聚合。 但我意识到这里有一个问题需要解决。我使用以下语句对我的结果进行分组: 我的问题是:字段2和字段3的值取决于字段1的值,所以如果你可以得到字段1的值,你也可以得到字段2和字段3的值。因此,像上面这样进行聚合会花费很多时间来完成我的程序(我已经测试过它,并意识到它比只对字段1进
-
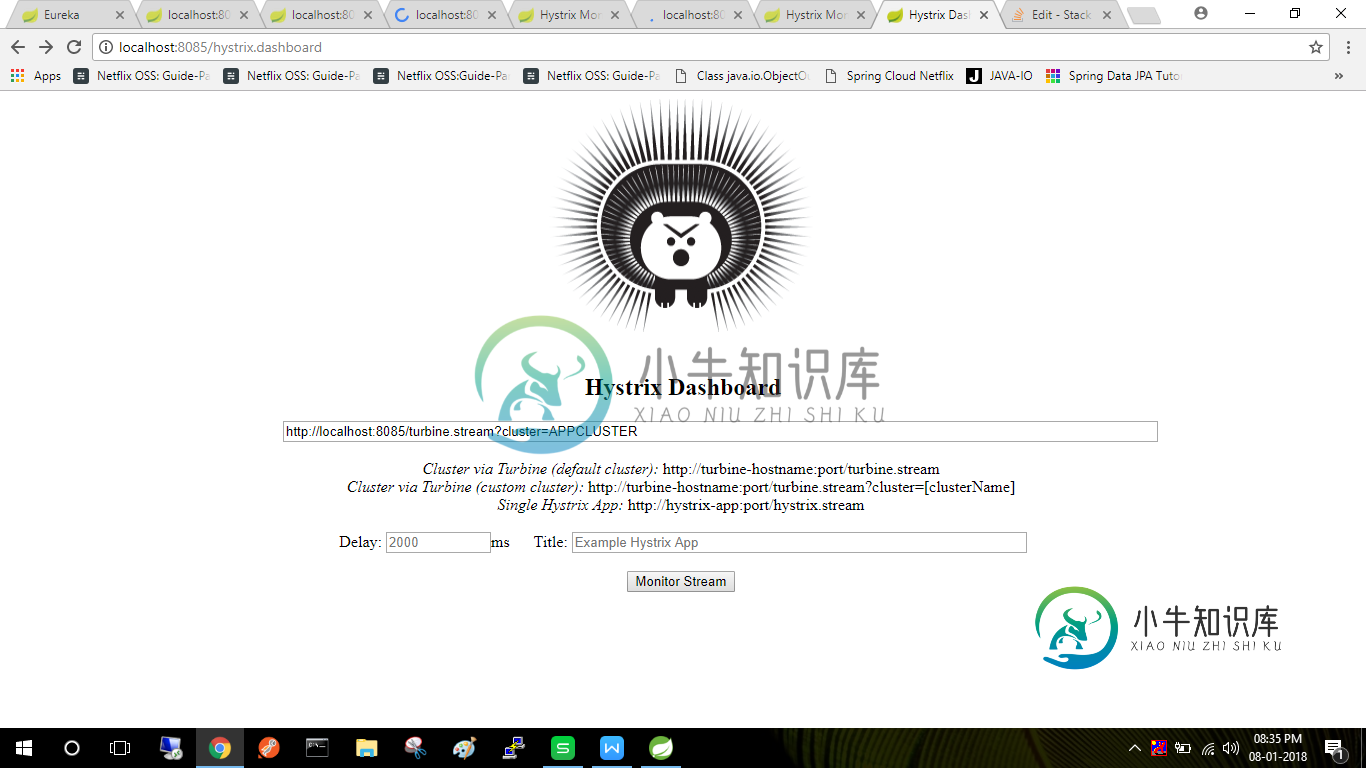 Spring Cloud微服务中未加载Turbine仪表板以进行聚合
Spring Cloud微服务中未加载Turbine仪表板以进行聚合我正在尝试使用spring MVC和spring boot框架开发一个spring云微服务。以及用于spring Cloud的Eureka服务器、Zuul、Ribbon、hystrix和Turbine。我已经开发了一个微服务,只实现了hystrix仪表板。我可以带上hystrix仪表盘。现在我正在实现更多的服务。所以我选择了涡轮进行聚合监控。但它没有得到仪表板。我在单独的spring boot项目
-
Jacoco:报告-聚合要么得到浅覆盖,要么根本没有
在“jacoco-aggregate”中手动运行构建之前,我查看了其他模块中引用的几个“jacoco.exec”文件,它们都存在并且是非空的。
-
使用聚合[重复]在mongoDB中限制和排序每个分组
我如何在mongoDB中按对每个组进行排序和限制。 考虑以下数据: 现在,我将按国家分组,按评级排序,并将每组的数据限制为2。 所以答案是: 我想只使用聚合框架来实现这一点。 我试图包括排序的评级,但简单的查询后处理没有结果。
-
ElasticSearch:基于反向嵌套doc\u计数订购顶级聚合桶
我正在使用ElasticSearch 6.3,我正在处理一个包含多个子聚合的聚合,其中我需要根据较低级别reverse_nested聚合的doc_count来排序顶级聚合桶。 我的索引是这样创建的: 这些是我索引的示例文档: 我需要我的聚合能够提取包含每个子项id/名称对的文档数。(考虑子项ID始终对应于相同的子项名称)。即: 这是原始聚合查询: 聚合似乎返回了我需要的所有数据: 但是,存储桶是根
-
将聚类分析结果转换为数据。R中的帧格式
这篇文章来自于这个主题,使用R对单词中的相同模式进行分类。解决方案很好,但是我需要数据帧格式。数据是相同的 我们来进行聚类分析 代码完成后,如何将结果转换为data.frame? 预期产出 s=as。数据(函数(…,row.names=NULL,check.rows=FALSE,check.names=TRUE)中的frame(拆分(文本,集群))错误:参数表示行数不同:7,1,2 所以理想的输出
-
是否可以用spring cloud stream API聚合字符串的对象instad?
我想使用spring cloud stream api聚合来自主题的事件。因此,我使用kstream作为输入。 现在我想使用聚合器将我的新对象存储在KeyValue存储区中,所以我使用以下代码: 为什么我只能使用字符串作为初始值设定项,不可能使用任何对象? 我错过什么了吗?
-
使用聚合检索查询结果中术语的文档频率
对于我对ElasticSearch的一些查询,我希望返回三条信息: 结果文档集中出现了哪些术语T? T的每个元素在结果文档集中出现的频率是多少? T的每个元素在整个索引(-- 使用缺省术语facet或现在的术语aggregation方法可以很容易地确定第一点。所以我的问题其实是关于第三点。在ElasticSearch 1.x之前,即在切换到“聚合”范式之前,我可以使用一个term facet,将“