《性能》专题
-
ThreadLocal变量的性能
问题内容: 从变量读取的速度比从常规字段读取的速度慢多少? 更具体地说,简单对象创建比访问变量快还是慢? 我认为它足够快,因此与每次创建实例相比,拥有实例要快得多。但这是否也适用于字节[10]或字节[1000]? 编辑:问题是调用get 时真正发生了什么?如果那只是一个领域,就像其他领域一样,那么答案将是“它总是最快的”,对吗? 问题答案: 运行未发布的基准测试,我的计算机上每次迭代大约需要35个
-
Android上的Guice性能
问题内容: 作为Java开发人员,我已经习惯了在应用程序中使用依赖项注入。但是对于Android,我尤其对性能保持警惕。在Android应用中使用Guice对性能有何影响?我认为会有一些开销,但是是否足够重要,我应该避免使用Guice? 我对它的使用可能只是将一些共享对象注入到各种活动中。 问题答案: 从版本3开始,Guice缓存反射对象以提高性能。至少有一个针对dalvik的错误可以使注解查找更
-
Java CharAt()和deleteCharAt()性能
问题内容: 我一直想知道java中String / StringBuilder / StringBuffer的charAt函数的实现是什么?还有StringBuffer / StringBuilder中的deleteCharAt()呢? 问题答案: 对于,和,是恒定时间的运算。 对于和,是线性时间运算。 并具有非常相似的性能特征。主要区别在于前者是(因此是线程安全的)而后者则不是。
-
Array vs ArrayList的性能
问题内容: Object类型的Array和Object类型的ArrayList之间的性能哪一个更好? 假设我们有一个对象数组: 和一个数组列表: 现在我正在做 , 哪一个应该更快,为什么? 问题答案: 很显然,array [10]比array.get(10)更快,因为后者在内部进行相同的调用,但是增加了函数调用的开销以及其他检查。 但是,现代JIT会在某种程度上优化它,您几乎不必担心此,除非您的应
-
HashMaps与阵列性能
问题内容: 在知道数组索引的情况下,使用Arrays或HashMaps更好(在性能方面)吗?请记住,示例中的“对象数组/映射”只是一个示例,在我的真实项目中,它是由另一个类生成的,因此我不能使用单个变量。 ArrayExample: HashMapExample: HashMap看起来好得多,但我确实需要在此方面具有性能,因此具有优先权。 编辑: 那么是数组,仍然欢迎建议 编辑: 我忘了提,Arr
-
Java ByteBuffer性能问题
问题内容: 在处理多个千兆字节文件时,我注意到了一些奇怪的事情:似乎使用文件通道从文件读取到分配有allocateDirect的重复使用的ByteBuffer对象中,比从MappedByteBuffer中读取要慢得多,实际上,它甚至比读取字节中的记录还要慢。使用常规读取调用的数组! 我期望它(几乎)与从mapedbytebuffers读取的速度一样快,因为我的ByteBuffer是使用alloca
-
MySQL Enum性能优势?
问题内容: 在一个字段只有5-10个不同的可能值的情况下使用枚举是否有性能优势?如果不是,优势是什么? 问题答案: 使用以下操作会导致巨大的性能 损失: 查询中的允许值列表,例如,填充一个下拉菜单。您必须从查询数据类型,并从返回的BLOB字段中解析列表。 更改允许值的集合。它需要一条语句,该语句锁定表并可以进行重组。 我不是MySQL的粉丝。我更喜欢使用查找表。另请参阅我对“ 如何在数据库中没有枚
-
mysql像性能提升
问题内容: 如果涉及通配符,有什么办法可以加快mysql等操作员的性能吗?例如。如“%test%” 问题答案: 如果查询看起来像或,MySQL可以使用索引。它可以将索引用于第一个通配符之前的任何部分或字符串。如果需要在字符串中的任意位置匹配单词,则可能需要考虑使用索引。 有关索引的更多详细信息: http //dev.mysql.com/doc/refman/5.1/en/mysql- index
-
MySQL中的UUID性能?
问题内容: 我们正在考虑将UUID值用作MySQL数据库的主键。所插入的数据是从数十台,数百台甚至数千台远程计算机生成的,并且以每秒100-40,000次插入的速度插入,我们将永远不会进行任何更新。 在我们开始选择数据之前,数据库本身通常会获得大约5000万条记录,因此不是庞大的数据库,但也不小。我们也计划在InnoDB上运行,但是如果我们有更好的引擎来进行我们的工作,我们愿意改变它。 我们已经准
-
MYSQL OR vs IN性能
问题内容: 我想知道以下两个方面在性能方面是否有差异 还是MySQL将以与编译器优化代码相同的方式优化SQL? 编辑:改变了‘s到的在注释中规定的原因。 问题答案: 我确实需要知道这一点,因此我对这两种方法进行了基准测试。我始终发现它比使用快得多。 不要相信给出意见的人,科学就是测试和证据。 我运行了1000倍等效查询的循环(出于一致性考虑,我使用): :2.34969592094s :5.837
-
JNI与JNA的性能
问题内容: 我们有一个本机应用程序,它使用GPU(OpenCL)通过一种特定的方法处理大数据,并且运行得很好,没有问题。该项目的一部分(网络和分发)由进行开发,我们只需要调用本机应用程序/库即可。 我们试图使用类将其称为独立的外部过程。问题是我们无法控制应用程序(事件,处理程序,线程等)。我们还尝试将C代码转换为Java代码,但是性能下降了。除了将本机代码作为进程运行之外,我还在考虑JNA和JNI
-
Swift String性能缓慢
问题内容: 我正在尝试解决回文分割问题。您可以在https://leetcode.com/problems/palindrome- partitioning/中 找到问题。 我想出了解决方案: 但是性能很差。超过时间限制。 但是Python实现的相同想法可以通过: 这让我想知道如何改进swift的实现以及为什么swift的实现比python慢。 问题答案: Swift 是的集合,并且a 表示单
-
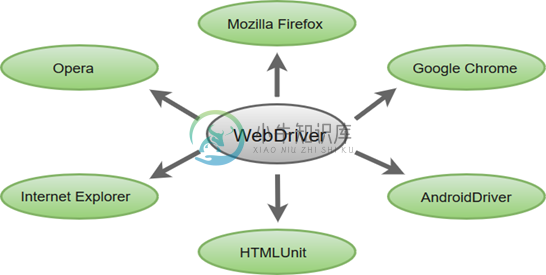 Selenium WebDriver功能特性
Selenium WebDriver功能特性Selenium WebDriver一些最重要的功能特性是: 多浏览器支持 :Selenium WebDriver支持各种Web浏览器,如Firefox,Chrome,Internet Explorer,Opera等等。它还支持一些非传统或罕见的浏览器,如HTMLUnit。 多编程语言支持:WebDriver还支持大多数常用的编程语言,如Java,C#,JavaScript,PHP,Ruby,Pe
-
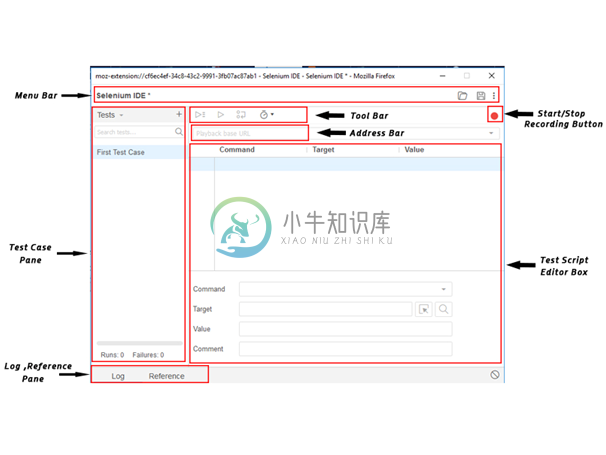 Selenium IDE功能特性
Selenium IDE功能特性主要内容:1.菜单栏,2. 工具栏,3. 地址栏,4. 测试用例窗格,5.测试脚本编辑器框,6. 开始/停止录制按钮,7. 日志,引用窗格Selenium IDE分为不同的组件,每个组件都有自己的特性和功能。这里对Selenium IDE的七个不同组件进行了分类,其中包括: 菜单栏 工具栏 地址栏 测试案例窗格 测试脚本编辑器框 开始/停止录制按钮 日志,引用窗格 现在,我们将详细介绍每个组件的特性和功能。 1.菜单栏 菜单栏位于Selenium IDE界面的最顶部。 最常用的菜单栏模块包括:
-
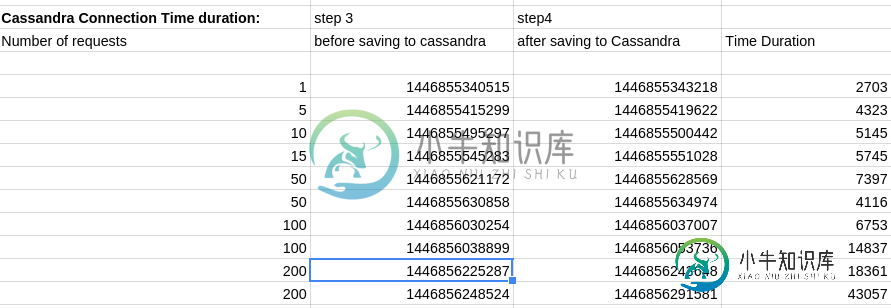 Spark Cassandra性能问题
Spark Cassandra性能问题我是Spark和Cassandra的新学员。我正面临着一个主要的性能问题,我在Spark中每5秒将来自Kafka的数据流化,然后使用JRI在R语言中对数据执行分析,最后将数据保存到Cassandra各自的列族中。将数据保存到Cassandra的持续时间(以毫秒为单位)随着输入请求的数量迅速增加[每个请求为200KB]。 火花代码: