《性能》专题
-
碰撞的可能性
我想散列一个内部帐号,并将结果用作帐户记录的唯一公共标识符。标识符限制为40个字符。我有大约250条具有唯一帐号的记录。 什么不太可能导致碰撞。 < li >取账号SHA-256哈希的SHA-1。 < li >取账号的SHA-256,挑出40个字符。
-
Apache Ant功能特性
Apache Ant功能特性如下: 开源 灵活 使用方便 跨平台 扩展 可扩展 XML 1. 开源 Apache Ant是一个开源库。 它允许用户访问源代码并重现它。 Ant拥有开源软件许可证。 它可以用来研究,重新分配。 2. 灵活 Ant本质上非常灵活,它可以毫不费力地与各种编程语言一起使用。 除了Java之外,其他有用的编程语言(如C,C++)也可以使用Ant来自动完成任务。 3. 使用方便
-
16-JavaScript-性能优化
页面性能 浏览器缓存 缓存分类 强缓存:直接拿来用的缓存 Expires Expires:Thu, 21 Jan 2018 23:39:02 GMT (表示绝对时间,时间来自服务器,但是做比较的时候以本地浏览器的时间作为比较) Cache-Control Cache-Control:max-age = 3600(客户端相对时间)它的判断优先级高 协商缓存:本地有副本,但无法确实是否可以使用,需要询
-
MySQL中的CASE性能?
问题内容: 我想知道是否在MySQL查询中使用CASE … WHEN … THEN表达式 对性能有负面影响? 而不是使用CASE表达式(例如,在UPDATE查询中), 您始终可以在程序中用 php,python,perl,java等编写if语句来选择要发送的查询(例如,以伪代码) ): 或侵入: (这里的c1只需要表明在两种情况下都发生了某些事情) 哪种方法具有更好的性能? 性能损失是多少? 问题
-
SQL Server性能提示
问题内容: 关于此查询,我有以下问题: 如果第一个条件为true(),SQL Server仍会进行内部选择吗?还是在第一个条件为真时停止(例如C) 问题答案: 当(1 = 1)为true时,它将停止。您可以先按Ctrl-M再按Ctrl-E轻松检查 考虑这个查询 执行计划仅显示的扫描,而没有的活动。 与C相反,当 LEFTMOST 条件为true时,它不会停止,而是查询优化器 独立于给出的顺序 工作
-
SSIS与DTS的性能
问题内容: 似乎在这么晚的时候这样做很疯狂,但是… 我正在使用Rocket Software UniVerse源和SQL目标重建一些ETL基础结构。旧的目标平台是Windows Server 2003上的SQL 2000,新的平台是Windows Server 2012上的SQL2012。在两种情况下,都使用ODBC驱动程序连接到源。一切似乎都可以在新平台上正常运行,但包的执行时间却成倍降低。例如
-
SQL JOIN vs IN性能?
问题内容: 在某些情况下,使用JOIN或IN将为我提供正确的结果…哪一种通常具有更好的性能,为什么?它在多大程度上取决于您正在运行的数据库服务器?(仅供参考,我正在使用MSSQL) 问题答案: 一般来说,和是可以产生不同结果的不同查询。 与…不同 ,除非是唯一的。 但是,这是第一个查询的同义词: 如果联接列被标记为,则这两个查询将在中产生相同的计划。 如果不是,则比on快。 有关性能的详细信息,请
-
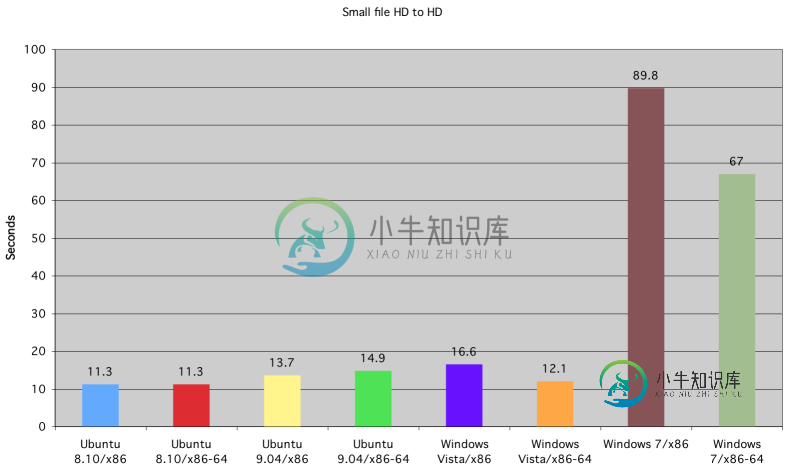 Windows上的Python性能
Windows上的Python性能问题内容: 与* nix机器相比,Windows上的Python通常会慢吗?Python似乎在Mac OS X机器上火起来,而在Window的Vista机器上 似乎 运行慢。这些机器的处理能力相似,而Vista机器则具有1GB以上的内存。 我在Mercurial中特别注意到了这一点,但我认为这可能只是Mercurial在Windows上打包的方式。 问题答案: 我想对此进行跟进,发现了一些我认为是
-
解构变量性能
问题内容: 编写之间是否存在性能差异(如果有) 与 另外,如果我们在参数签名中进行结构分解,会获得或失去任何性能?参见example3 我认为在这种情况下example3是编写函数的最佳方法? 功能性反应组件示例: 问题答案: 由于您的代码将被编译/缩小,因此不会有任何性能问题。 注意,使用React,您的代码将被转译,其作用与 在babel编译器在线测试仪上检查结果
-
React的性能问题
问题内容: 我读到React非常快。最近,我写了一个应用程序来测试对角的反应。不幸的是,我发现反应的表现要慢于角度反应。 http://shojib.github.io/ngJS/#/speedtest/react/1 这是react的源代码。我是新来的人。我确定我的反应代码在这里做错了。我发现它异常缓慢。 https://jsbin.com/viviva/edit?js,输出 看看是否有任何反应
-
Python SQL查询性能
我正在使用jaydebeapi(Mac OS X)查询Netezza数据库,并执行一些快速/肮脏的计时: 完成大约需要10分钟(平均超过10次)。 现在,当我使用WinSQL(Windows7,ODBC)运行相同的SQL查询时,返回数据大约需要3分钟。我似乎不明白为什么在Python中要花这么长的时间,也不确定如何或从哪里开始寻找。
-
 Oracle vs IBM Java性能
Oracle vs IBM Java性能我试图比较两个主要Java实现的性能:Oracle和IBM运行以下测试: 通过以下方式运行上述代码: IBMJRE 1.8.0 java版本“1.8.0”java(TM)SE运行时环境(build pwa6480sr3fp22-20161213\U 02(SR3 FP22))IBM J9 VM(build 2.8,JRE 1.8.0 Windows 10 amd64-64压缩引用20161209\
-
SQL Server查询性能
问题内容: 我在繁忙的数据库上有一个存储过程,该数据库在某种程度上一直在昂贵的查询列表中排在首位。该查询非常简单,它采用单个参数(@ ID,int)作为表的主键,并选择与该ID匹配的记录。主键是带有聚簇索引的身份字段,所以我很困惑如何进一步优化它? 查询如下 不确定发布执行计划的最佳方法-显示的全部内容是聚集索引扫描占用了100%的操作 问题答案: 我认为通过使用您,您将获得次优的计划。将其分为2
-
SQL Server:合并性能
问题内容: 我有一个500万行的数据库表。聚簇索引是“自动增量标识”列。PK是代码生成的256个字节,它是URL的SHA256哈希,这是表上的非聚集索引。 下表如下: 是图像URL的SHA256哈希,例如“ http://blah.com/image1.jpg ”,它哈希为256个长度的varchar。 是由代码生成的guid,可在其中标识图像(以后将用作索引,但现在我已将此列省略为索引) 是图片
-
Spring Cloud StreamBridge性能低?
我正在使用Spring Cloud StreamBridge将消息发布到RabbitMQ交换机。使用本机RabbitMQ完美测试,我可以使用单个生产者轻松获得100kmsgs/s(1个通道)。如果我使用发送StreamBrige(也是1个通道)启动带有时循环的线程,我只获得~20kmsgs/s的类似设置(没有持久性,没有手动打包或确认,相同的Docker容器...)。我使用的是Spring Clo