
Spark Cassandra性能问题

我是Spark和Cassandra的新学员。我正面临着一个主要的性能问题,我在Spark中每5秒将来自Kafka的数据流化,然后使用JRI在R语言中对数据执行分析,最后将数据保存到Cassandra各自的列族中。将数据保存到Cassandra的持续时间(以毫秒为单位)随着输入请求的数量迅速增加[每个请求为200KB]。
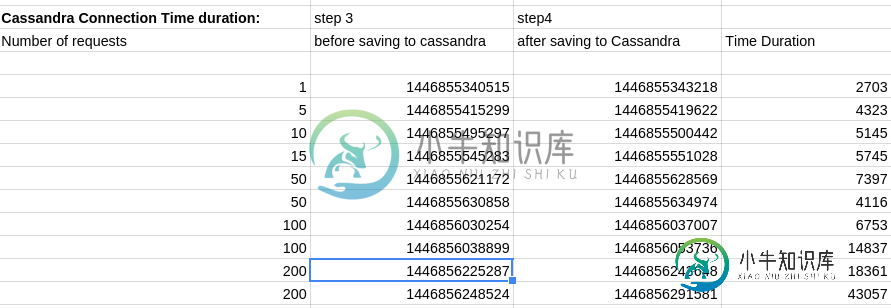
火花代码:
sessionData.foreachRDD(new Function<JavaRDD<NormalizedData>, Void>() {
public Void call(JavaRDD<NormalizedData> rdd) {
System.out.println("step-3 " + System.currentTimeMillis());
javaFunctions(rdd).writerBuilder("keyspace",normalized_data",mapToRow(NormalizedData.class)).saveToCassandra();
System.out.println("step-4 " + System.currentTimeMillis());}}
共有1个答案

我可以通过在同一台服务器上使用Spark和Cassandra来提高性能。这个延迟是因为Spark和Cassandra在不同的服务器上,虽然在AWS的同一区域。网络延迟是影响数据局部性的主要原因。谢了。
-
问题内容: 我在Java2D方面表现有些古怪。我知道sun.java2d.opengl VM参数可以为2D启用3D加速,但是即使使用该参数也有一些奇怪的问题。 这是我运行的测试结果: 在JComponent上绘制具有32x32像素图块的25x18地图, 图像1 = .bmp格式,图像2 = .png格式 没有-Dsun.java2d.opengl = true 使用.BMP图像1的120 FPS使
-
最近,我们将数据库从11g更新为19c。 在新数据库版本中测试应用程序时,我们遇到了一个特定视图的性能问题,该视图工作得非常好,但在19c中会导致性能问题。 在分析计划时,我们看到执行计划发生了巨大变化,这导致了19c中视图的性能非常差。 令人惊讶的是,其他观点的效果很好。 如果你能对这个问题有所了解,那就太好了。 谢谢你,JD
-
问题内容: 在处理多个千兆字节文件时,我注意到了一些奇怪的事情:似乎使用文件通道从文件读取到分配有allocateDirect的重复使用的ByteBuffer对象中,比从MappedByteBuffer中读取要慢得多,实际上,它甚至比读取字节中的记录还要慢。使用常规读取调用的数组! 我期望它(几乎)与从mapedbytebuffers读取的速度一样快,因为我的ByteBuffer是使用alloca
-
问题内容: 我读到React非常快。最近,我写了一个应用程序来测试对角的反应。不幸的是,我发现反应的表现要慢于角度反应。 http://shojib.github.io/ngJS/#/speedtest/react/1 这是react的源代码。我是新来的人。我确定我的反应代码在这里做错了。我发现它异常缓慢。 https://jsbin.com/viviva/edit?js,输出 看看是否有任何反应
-
我有一个flink作业(scala),它基本上是从Kafka主题(1.0)读取数据,聚合数据(1分钟事件时间翻转窗口,使用折叠函数,我知道这是不推荐的,但比聚合函数更容易实现),并将结果写入两个不同的Kafka主题。 问题是——当我使用FS状态后端时,一切都运行顺利,检查点需要1-2秒,平均状态大小为200 mb——也就是说,直到状态大小增加(例如,在缩小差距的同时)。 我想我会尝试使用rocks
-
所以我在FXML中定义了一个ListView 以及相应的方法 方法不是很大,但是第一行代码只在5秒后执行!但是在同一程序中的另一个ListView中,ListView没有速度问题?怎么会呢?如果需要任何其他信息,请评论