《好运》专题
-
为什么允许设置集合是不好的做法?
假设我们有一个具有简单集合(例如列表)的类。类包含一个构造函数、getter和setter。有人告诉我,直接设置集合是一种不好的做法。 有人能指出编写方法的缺点吗?
-
使用spy进行mockito更好的预期异常测试
如何进行第三个测试来检查异常消息中原因1的存在?我还列出了前两个测试中存在的缺点。首先是不检查消息,其次需要大量样板代码。 我在Mockito中找不到一些有用的东西,但有一些东西看起来是可能的(在语法级别)和功能。 使用catchexception,我创建了这样的测试
-
优步Cadence中延迟任务的好用例是什么?
我想实现一个延迟任务,发现了一个cadence cron例子,如何用cadence实现一个延迟任务?
-
在PROD中更改Azure cosmos db文档的更好选择
需要通过在PROD上一次性添加新属性来修改大约10,000个Azure cosmos db文档。NET SDK v3(OR)Cosmos DB Bulk Executor(OR)最好用一个循环逐个替换文档,应该考虑哪一个?
-
为什么Ruby中的`rescreve Exception=>E`是不好的样式?
Ryan Davis的Ruby QuickRef说(没有解释): 不营救例外。永远不会。不然我就捅你一刀。 为什么不呢?做什么才是正确的?
-
缓存是NSDateformatter应用程序范围的好主意吗?
众所周知,创建NSDate格式器是“昂贵的” 甚至苹果的数据格式指南(2014-02年更新)也指出: 创建日期格式化程序并不是一项廉价的操作。如果您可能经常使用格式化程序,缓存单个实例通常比创建和处理多个实例更有效。一种方法是使用静态变量。 但该文档似乎并不是swift的最新版本,我在最新的NSDateFormatter类参考中也找不到任何关于缓存格式化程序的信息,所以我只能假设swift和obj
-
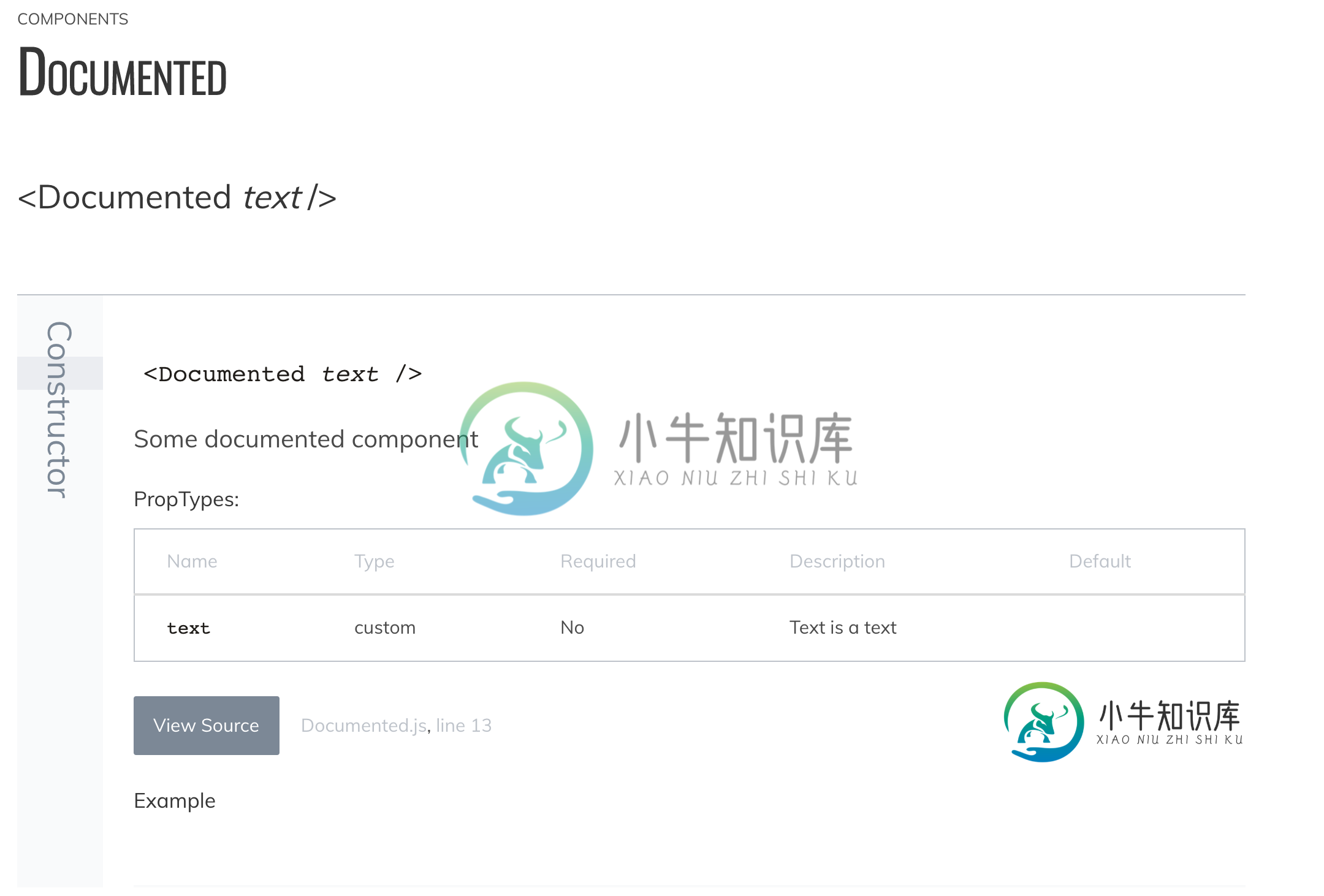 JSDoc(更好的文档)未正确显示所需的propType
JSDoc(更好的文档)未正确显示所需的propType使用带有React应用程序的JSDocs的更好的文档插件。它旨在解析PropType,并从PropType获取信息,并将其放入数组中。确实如此。但在表中显示必需为'否',即使当proType标记为是必需的。 https://github.com/SoftwareBrothers/better-docs#usage-2 https://softwarebrothers.github.io/admin
-
Uber Cadence中的子工作流有什么好的用例?
我试图了解Uber Cadence的子工作流的用例。与简单地将工作流拆分为函数相比,子工作流的优势是什么?我有一个相当复杂的工作流,我正在考虑将其拆分为多个子工作流,但我不确定这样做的利弊。
-
如何使用ApacheKafka实现“恰好一次”kafka消费者?
我们有一个应用程序,它使用来自Kafka主题(3个分区)的消息,丰富数据,并将记录保存在DB(Spring JPA)中,然后将消息发布到另一个Kafka主题(在同一个代理上),所有这些都通过使用Camel 2.4.1和Spring Boot 2.1.7进行编排。释放 我们想为 kafka 消费者-生产者组合实现“exactly-once”语义。 消费者设置: 生产者设置: 豆接线: 骆驼路线: 但
-
邻接子数组。有比O(n^2)更好的解吗?
我正在解决以下问题: null 输入:Array arr是一个非空的唯一整数列表,范围在1到1,000,000,000之间,大小N在1到1,000,000之间 输出:一个数组,其中每个索引i包含一个整数,表示ARR[i]的最大相邻子数组数 示例:arr=[3,4,1,6,2]输出=[1,3,1,5,1] 计算从1到N的每个i的g[i]是一种很有希望的方法,但我们仍然需要考虑如何尽可能有效地这样做。
-
为什么 OOMKilled 在重新安排时没有准备好?
我有一个错误,不健康的pod,即使我认为pod在重新安排后按预期工作。如果我重新启动(删除)它,它就准备好了,但我想了解为什么它最终会处于不健康状态。 我的探头很简单,就像这样: 事件: 状态 如果我跑了 我得到200英镑。好的。 有人能解释为什么吊舱没有准备好吗?我想这与OOMKilled有关,因为内存限制,这应该是固定的。但我想知道为什么它不能正确重启。
-
 JMeter:负载测试RESTAPI的好测试结构是什么?
JMeter:负载测试RESTAPI的好测试结构是什么?我正在使用JMeter对一堆API(例如用户服务、播放器服务等)进行负载测试(基线、容量、寿命)。这些服务中的每一个都有几个endpoint(例如创建、更新、删除等)。我正在尝试找出一种在JMeter中组织我的测试计划的好方法,以便我可以加载测试所有这些服务。 1)为每个API创建一个单独的JMeter测试计划(jmx),而不是创建一个JMeter测试计划并添加线程组,如“用户服务线程组”、“播放
-
角度4:ng发球很好,但ng构建--prod失败
当我试图运行时,它运行时没有任何错误,但当我试图使用''创建生产构建时,它停止了,错误如下。我试图调整版本,但没有成功。然后发生了一些其他问题,就像其他API版本兼容性问题一样。如有任何帮助,我们将不胜感激。 请查找package.json以供参考:
-
AWS ELB和Nat网关不能很好地协同工作
我有一个基本的 VPC,其中包含两个运行 Apache 的 Linux EC2 实例,它们位于经典 ELB 后面。 我想从web应用程序中使用DynamoDB,这要求EC2实例具有出站互联网访问,因为DynamoDBendpoint无法通过后端获得。 我正在使用 ELB 来避免将公有 IP 附加到 EC2 实例,因此我宁愿不附加它们,以便可以访问 DynamoDB。 在这一点上,我被卡住了。 我设
-
使用facebook API检索好友的完整列表[重复]
新的2.0版本有一个分页,限制一个请求的朋友数量,这不允许我一次检索所有朋友,尽管有一个参数调用“limit”,它只能通过循环“偏移量”直到最后来完成。问题是每个用户都有不同数量的朋友! 我已经四处寻找了几个小时,但仍然没有解决方案。