《好运》专题
-
使用POJO对象列表有什么更好的方法
我有一个结构如下的JSON: 当我用下面的代码反序列化对象时,引用对象列表“item”给出了错误:“JSONMappingException:Can not反序列化java.util.ArrayList实例out of START_OBJECT token” 对于我来说,在一次调用中重新获得父对象Firebase和它们的子对象,对json来说,最好的POJO是什么?
-
你好,我有一个问题与键盘输入程序
当我输入名字时,它会给我一个有效的数字或一个特殊字符。我想这样做,使数字不被考虑在内,不会被返回,或者它可能会给出一个错误消息。
-
在REST API中使用POST参数和JSON哪个更好?
-
jdbc是否在内存中保留准备好的语句?
我正在为我的sqlite日志数据库使用准备好的语句。 我的线程每50ms运行一次,将日志缓冲区中的内容写入数据库。 目前,我正在对每个线程运行一个新的准备好的语句批处理,并在所有数据线写入后关闭它们。 现在我想知道是否最好将准备好的语句保存在内存中,并仅在线程关闭/中断时关闭它? 我之所以进行这种预优化,是因为我希望这个日志线程对主应用程序性能的干扰尽可能小,我可以想象每50秒分配/解析/验证资源
-
与Swagger相比,使用Spring REST文档有什么好处
Spring REST文档最近发布,文档中说: 这种方法将您从像Swagger这样的工具强加的限制中解放出来 所以,我想问一下,与Swagger相比,SpringREST文档什么时候更适合使用,以及它释放了哪些限制。
-
如何将“读者友好的”sessionInfo()写入文本文件
我想将“sessioninfo()”的输出保存到文本文件中。使用“write()”失败,因为“list()不能由'cat()'处理”。然后,我使用ascii=T尝试“save()”,但是得到的文件并没有真正的帮助。 我希望在文本文件中有这样的输出。有什么简单直接的方法可以做到这一点吗?
-
如何在R中最好地结合独特和匹配?
我发现自己经常编写代码,例如 加速一个缓慢的矢量化“纯”函数,其中每个输入项理论上可以单独计算,并且输入预计包含许多重复项。 现在我想知道这是否是实现这种加速的最佳方式,或者是否有一些函数(最好是在基本R或tidyverse中)同时执行诸如和之类的操作? 谢谢你提供的答案。我编写了一个小型基准测试套件来比较这些方法: 目前,基于rcpp的方法在我的机器上的所有测试设置中都是最好的,但几乎没有超过独
-
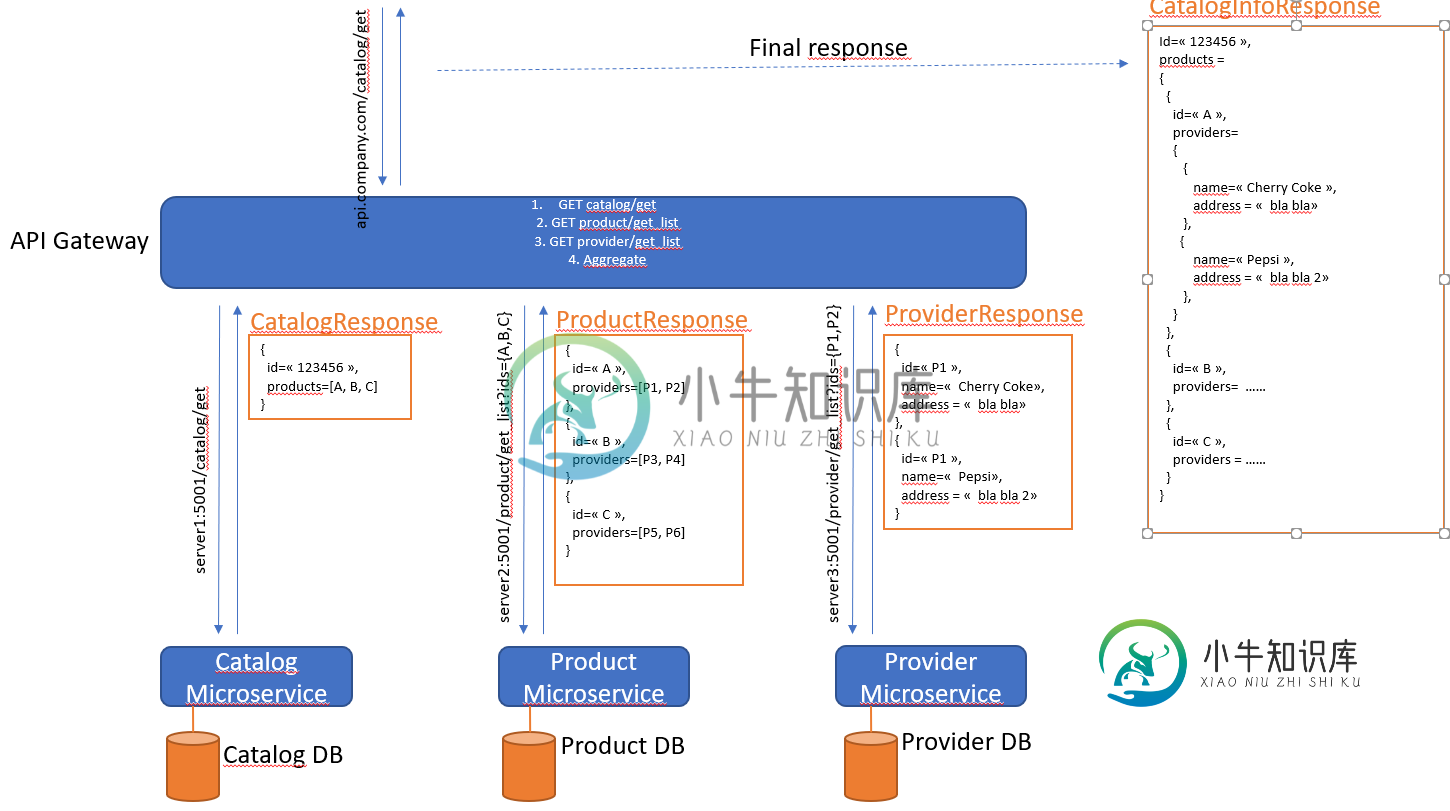 微服务:聚合数据:有什么好的模式吗?
微服务:聚合数据:有什么好的模式吗?我有以下微服务架构的用例。 我的问题是,在当前情况下,我有3个微服务和一个APIGateway。 最后,网关必须在聚合(合成)来自3个服务的数据之前进行大量查询。因为3个微服务只提供基本的数据集。 请查看图片了解更多详情! 这是一个好的模式吗?还有其他模式吗?
-
如何在OpenNLP中创建良好的NER训练模型?
我刚开始使用OpenNLP。我需要创建一个简单的训练模型来识别名称实体。
-
Android后台蓝牙处理:最好的方法是什么?
我刚刚开发了一个Android应用程序(MINSDKVersion23/TargetSDKVersion29),它可以连接到BluetoothLE设备以定期获取数据。 现在,在MainActivity(不是第一个活动)中,我执行以下注册BroadcastReciever的操作: 当设备连接/发现/datareCieved时执行的所有回调都在StatusActivity中,而不是在BleServic
-
从卡桑德拉接收已经准备好的声明
我并不完全理解预准备语句的概念,但是根据python驱动程序文档,预准备语句是< code >“针对至少一个Cassandra节点准备的语句”。对我来说,在集群中的某个地方有关于已经准备好的查询的信息。该文档还规定< code >“prepared statement应该只准备一次。重新准备语句可能会影响性能(因为该操作需要网络往返),"。 如果我的概念是正确的,那么从集群中接收已经准备好的语句而
-
为什么兰特()的使用被认为是不好的?
我听到一些人说,即使在使用获得种子之后,使用也是很糟糕的。为什么会这样?我想知道事情是怎么发生的...抱歉,我又问了一个问题..但是,有什么办法可以替代这一点呢?
-
Gradle:如果我从Groovy切换到Kotlin有什么好处?
我是安卓开发者。因此,我使用Gradle构建android项目。我在Groovy上写(大约2年)分级脚本。因此脚本非常紧凑,清晰,易于支持。非常好。 而在新版本的Gradle中引入了新的语言--Kotlin。 我的问题是:如果我从Groovy切换到Kotlin(对于编写Gradle脚本)有什么好处?
-
你好,我部署了war文件,但无法启动它
错误是:至少扫描了一个JAR的顶级域,但没有包含顶级域。为此记录器启用调试日志记录,以获取已扫描但未在其中找到TLD的JAR的完整列表。在扫描过程中跳过不需要的JAR可以提高启动时间和JSP编译时间。
-
 当代码编译良好时,Resharper“无法解析符号”
当代码编译良好时,Resharper“无法解析符号”我认为,错误消息与无关,而是因为代码/程序集/包特定的结构/修饰符等。 因此,当导航(通过命令)到元数据并很好地编译代码(包括,也成功地显示方法说明)时,会显示错误(并且无法访问(来自引用的程序集的)代码)。 该方法在程序集中定义如下: 有什么想法吗?