《光峰科技》专题
-
 数蓬科技 NLP面
数蓬科技 NLP面1.介绍项目(推荐算法比赛,和nlp相关) 2.介绍Transformer 3.是否了解大模型(不会) 4.了解那些损失函数,优化器(答Adagrad,问原理) 5.做题(没做出来,可恶啊很简单的题) 面试官小姐姐人很好,一直叫我不要紧张... 感觉要凉
-
 亚信科技面试
亚信科技面试首先先吐槽一下,随便投的亚信,上面要求会一种后端语言即可,我golang的就投了。今天晚上8点突然打电话说有空吗,我以为是约面试,谁知道是直接面试,赶紧找个地方坐。主要是我的简历上全是golang,怎么全部问java,幸好学过。 1.知道java的那些框架 2.springboot的启动方式 3.建立一个快速的springboot微服务,核心依赖是什么 4.springboot的核心注解 5.my
-
 绿盟科技一面
绿盟科技一面五一假期前约的一面,今天早上9点开始面试,面试官3个,面了快50分钟。 1.自我介绍 2.你做过的项目中都遇见过那些问题,怎么解决的 3.python的装饰器 4.python的迭代器和生成器 5.golang的并发通信 6.golang的文章锁 7.你对gin框架的了解(其实就是优点) 8.gin框架的缺点 7.gin框架的路由在源码中是怎么实现的 8.你对gorm的了解 9.gorm的局限性也
-
JS实现字符串转驼峰格式的方法
本文向大家介绍JS实现字符串转驼峰格式的方法,包括了JS实现字符串转驼峰格式的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS实现字符串转驼峰格式的方法。分享给大家供大家参考,具体如下: 实现效果如:border-bottom-color =>borderBottomColor 传传统方法 分析: 1.转大写,需要用到字符串的toUpperCase()方法 2.去掉-,需要用到字符
-
在C ++的链接列表中查找峰值元素
本文向大家介绍在C ++的链接列表中查找峰值元素,包括了在C ++的链接列表中查找峰值元素的使用技巧和注意事项,需要的朋友参考一下 在本教程中,我们将编写一个程序,该程序在给定的链表中查找峰值元素。 峰值元素是大于周围元素的元素。让我们看看解决问题的步骤。 为链表创建一个struct节点。 用伪数据创建链接列表。 检查基本情况,例如链表是否为空或长度为1。 将第一个元素存储在一个名为previou
-
从驼峰路由向Weblogic JMS队列发送消息
我试图通过驼峰路由将消息放到Weblogic JMS中的队列中。 我的目标是最终配置一个Route以使用来自jms队列的消息,我将早期Route的数据发布到该队列。 这是我的配置: 我的路线如下所示: 我尝试执行此路由时遇到此异常: 我按照以下过程创建了此处提到的队列:https://blogs.oracle.com/soaproactive/entry/how_to_create_a_simpl
-
如何在驼峰路线中访问正文/交换
我正在尝试以骆驼路线记录交换或尸体,如下所示: 这张照片是空白的,比如“身体:”。但是,通过传递以下参数,在同一路径中调用某些处理器: 如果要查看exchange的内容,如何从camel路由记录exchange/body?
-
在驼峰路由中看不到标头或属性
我有以下骆驼上下文XML。我设置了一个名为MediaType的标题。但是,当我在RenamerProcessor中设置断点时,我看不到标题(我也尝试过使用setProperty,但结果相同。我对Camel非常陌生,我发现了几个例子,似乎下面的例子应该可以使用。 怎么了?
-
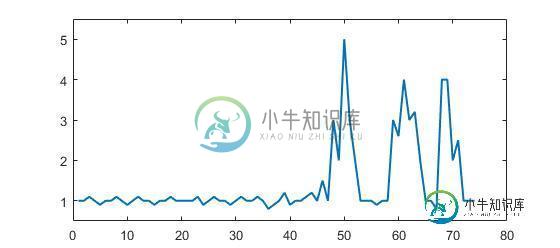 实时时序数据中的峰值信号检测
实时时序数据中的峰值信号检测更新:到目前为止,性能最好的算法就是这个。 这个问题探索了检测实时时间序列数据中突然峰值的鲁棒算法。 考虑下面的示例数据: 此数据的示例为Matlab格式(但此问题与语言无关,而与算法有关): 你可以清楚地看到有三个大峰和一些小峰。此数据集是问题所涉及的timeseries数据集类的一个特定示例。此类数据集具有两个一般特征: 存在具有一般平均值的基本噪声 存在明显偏离噪声的大“峰值”或“更高数据点
-
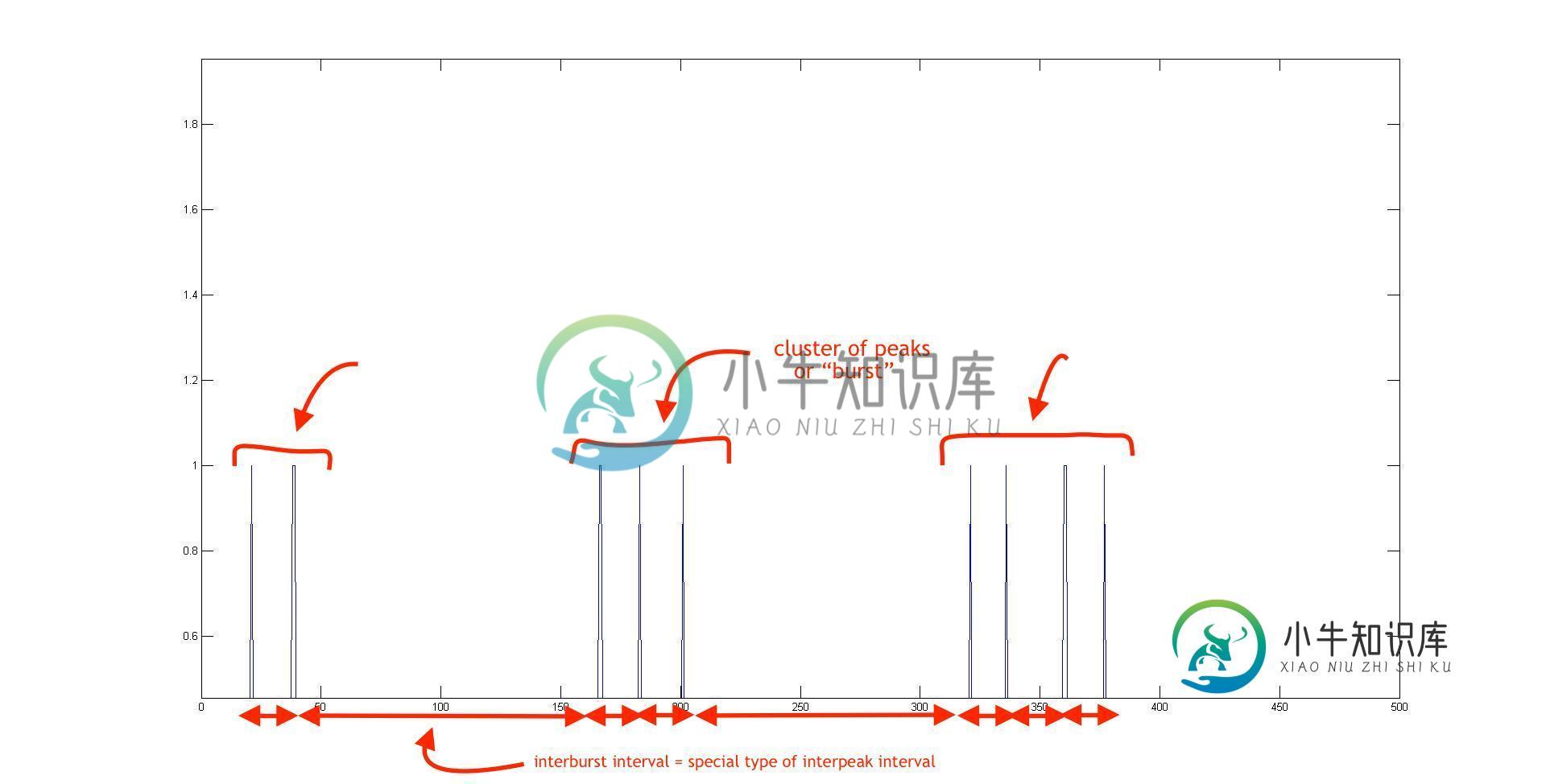 时间序列信号峰值聚类检测算法
时间序列信号峰值聚类检测算法我有一个带有开/关数据的二进制时间序列数据集。on通常是短暂的,因此看起来像一个峰值。这就是它的样子。 我已经检测到了峰值,并提取了峰值之间的时间间隔,并且也有数据(底部的红色小双向箭头)。问题是,可以看出,峰值是聚集的,我想对突发大小(集群中的峰值数量)、突发间隔(第一个集群的最后一个峰值和最后一个集群的第一个峰值之间的距离)、突发数量等进行量化。 一旦确定了集群,所有这些都很容易做到。这可以通
-
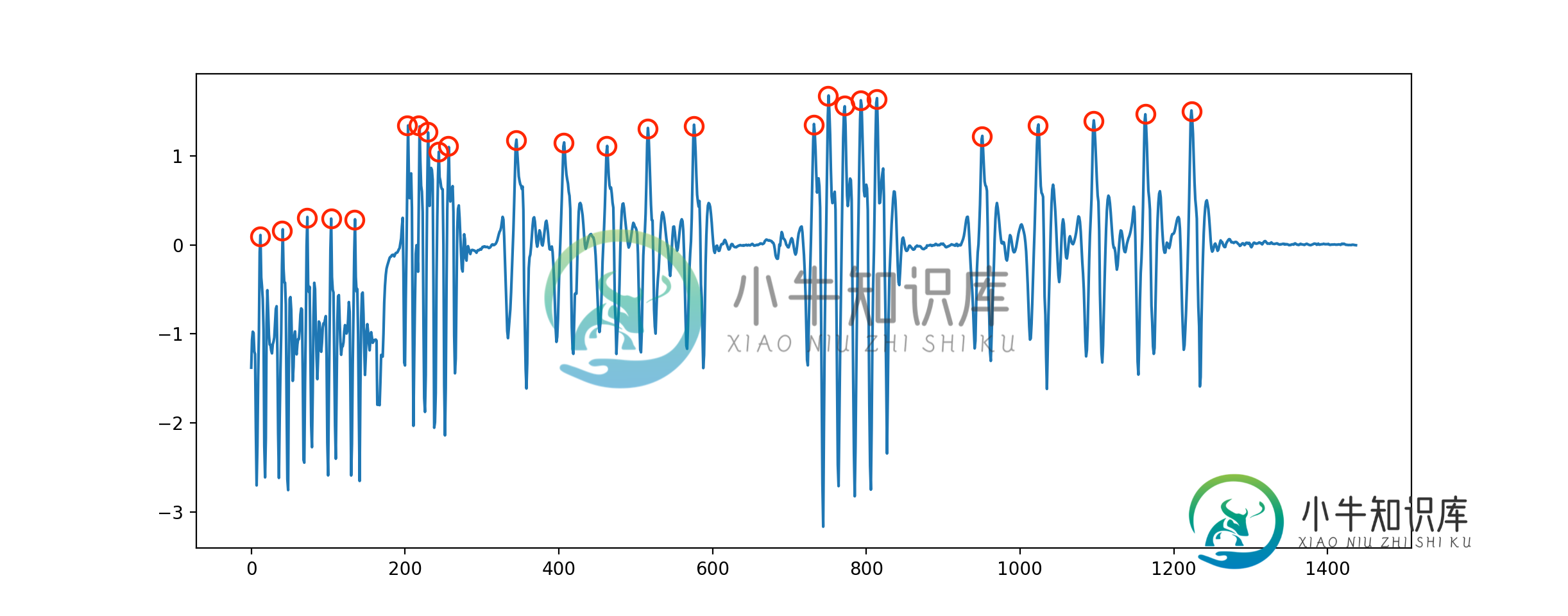 基于Swift的增长时间序列峰值检测
基于Swift的增长时间序列峰值检测谁会有一个好的算法来使用Swift(v3)测量不断增长的时间序列数据的峰值?因此,在数据流入时检测峰值。 例如,平滑z波算法的快速版本。那个算法似乎是合适的。 我需要检测如下所示的峰值。数据包含正数和负数。输出应该是峰值的计数器,和/或该特定样本的真/假。 示例数据集(上一系列的摘要): 最新消息:感谢Jean Paul首次提供Swift端口。但不确定z-wave算法是否适合此数据集
-
 Pandas/Python在读取3.2 GB文件时内存峰值
Pandas/Python在读取3.2 GB文件时内存峰值因此,我一直在尝试使用pandas<code>read_csv。 所以作为选择 > < li> 我尝试定义< code>dtype以避免将数据作为字符串保存在内存中,但看到了类似的行为。 尝试numpy read csv,以为我会得到一些不同的结果,但肯定是错误的。 试着一行一行地读也遇到了同样的问题,但是真的很慢。 我最近转到了python 3,所以认为那里可能有一些bug,但在python2
-
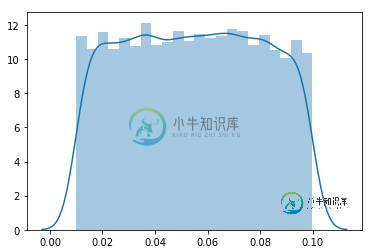 生成峰度大于3的随机正态分布
生成峰度大于3的随机正态分布正态分布的峰度为 3。随着分布中异常值的增加,尾部变得“胖”,峰度增加到3以上。 如何在峰度大于3(最好在5-7左右)的两个数之间生成随机分布? 进口 0.01-0.10之间的随机均匀性 1.8124891901330156 0.01-0.10之间的随机正态分布 3.015004351756201 0.01-0.10之间的厚尾随机正态分布 ???
-
完美解决idea光标变成了insert光标状态的问题
本文向大家介绍完美解决idea光标变成了insert光标状态的问题,包括了完美解决idea光标变成了insert光标状态的问题的使用技巧和注意事项,需要的朋友参考一下 在 Intellj IDEA总每次打开一个新文件,光标都会变成insert光标状态 ,按下insert键之后又恢复了,可再打开另外一个文件又恢复了 解决办法: 卸载Intellj IDEA插件IdeaVim 1、打开file ->
-
 中国银行信息科技运营中心 中行信科
中国银行信息科技运营中心 中行信科面完了,写个面经吧。(base 上海 信息科技岗) 1、自我介绍 2、本科绩点 3、实习经历 4、是否挂过科 5、家在哪 6、是否有其他offer 7、数据清洗流程 8、特征选择、降维方法 9、分类的作用(具体应用场景) 10、数据有缺失值怎么处理 11、offer城市选择 大概流程12分钟吧。中间的面试官追问了好多细节,还说了一句“这就没了?”。我估计是g了,明天面试的xdm加油