《工作压力大怎么缓解》专题
-
操作系统中缓冲与缓存之间的区别
本文向大家介绍操作系统中缓冲与缓存之间的区别,包括了操作系统中缓冲与缓存之间的区别的使用技巧和注意事项,需要的朋友参考一下 在这篇文章中,我们将了解操作系统中缓冲和缓存之间的区别- 正在缓冲 它是主内存中的一个区域。 这意味着它与RAM(随机存取存储器)相关联。 缓冲区将数据的原始副本存储在内存中。 缓冲与发送方和接收方之间的数据流速度匹配。 快取 缓存将数据的原始副本存储在内存中。 缓存可以提高
-
hbase的rowkey怎么创建好?列族怎么创建比较好?
本文向大家介绍hbase的rowkey怎么创建好?列族怎么创建比较好?相关面试题,主要包含被问及hbase的rowkey怎么创建好?列族怎么创建比较好?时的应答技巧和注意事项,需要的朋友参考一下 解答: hbase存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性) 一个列族在数据底层是一个文件
-
Mapreduce 的 map 数量 和 reduce 数量 怎么确定 ,怎么配置?
本文向大家介绍Mapreduce 的 map 数量 和 reduce 数量 怎么确定 ,怎么配置?相关面试题,主要包含被问及Mapreduce 的 map 数量 和 reduce 数量 怎么确定 ,怎么配置?时的应答技巧和注意事项,需要的朋友参考一下 解答: map的数量有数据块决定,reduce数量随便配置。
-
 javascript - 接口传参怎么传多维数组,应该怎么传?
javascript - 接口传参怎么传多维数组,应该怎么传?接口传参的时候需要给后端传的参数是数组 大概是这样的: 在这弹窗里面,点击弹窗下面的保存按钮调接口,需要把每一行的单位代码和总人口作为参数传过去,还要判断一下id,这条数据有id的话就传id,没有id的话就不传id 只传单位代码和总人口 请问接口传参应该怎么传多维数组,把每一行的单位代码和总人口传给后端,还有判断id应该怎么去操作呢?
-
VBA代码在新工作簿中工作,但不是我希望它在其中工作的工作簿
我有一个工作簿,宏不起作用,基本上只是从单元格A3上下复制每个工作表中的值,然后连续将每个值粘贴到新的摘要工作表中。 当我真的创建了一个新工作簿,并将我所有的工作表复制粘贴到新工作簿中时,一切都很好。但如果我继续写旧的工作手册,就会出现错误 选择工作表类的方法失败 在我使用与我复制的完全相同的工作表创建的其他2个工作簿中,它没有失败...为什么是这个特定的工作簿? 我关闭所有其他工作簿以避免Act
-
当您在mysql上需要大于20的整数时该怎么办?
问题内容: 好像是MySQL上可用的最大整数,对不对? 例如,当您需要存储BIGINT(80)时该怎么办? 为什么在某些情况下,例如Twitter API文档中的某个地方,他们建议我们将这些大整数存储为? 选择使用一种类型而不使用另一种类型的真正原因是什么? 问题答案: 大整数实际上并不受限于20位数字,它们限于可以用64位表示的数字(例如,该数字尽管长20位,但不是有效的大整数)。 出现此限制的
-
使用webpack打包React项目,怎么减小生成的js大小?
本文向大家介绍使用webpack打包React项目,怎么减小生成的js大小?相关面试题,主要包含被问及使用webpack打包React项目,怎么减小生成的js大小?时的应答技巧和注意事项,需要的朋友参考一下 打包优化的问题解决思路: 代码压缩: 代码分组 , 网络传输压缩gzip: 抽取css代码: 组件动态加载:
-
javascript - 求助大佬们,vue项目怎么隐藏接口地址啊?
由于是H5页面,使用浏览器的调试功能就能看到接口的真实地址,很容易被攻击,想要隐藏接口地址,在vue项目里应该怎么写啊?
-
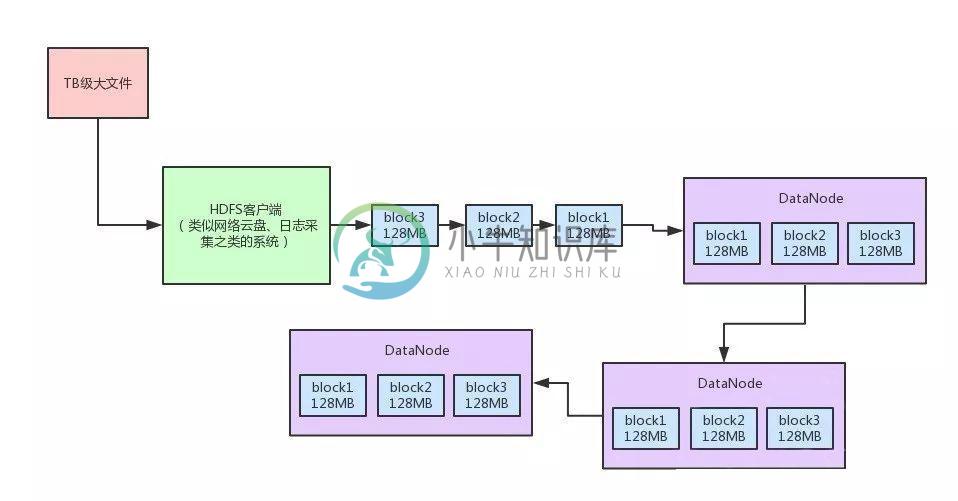 大厂面试题: TB级文件上传该怎么优化性能?
大厂面试题: TB级文件上传该怎么优化性能?主要内容:一、写在前面,二、原始的文件上传方案,三、HDFS对大文件上传的性能优化,1. Chunk缓冲机制,2. Packet数据包机制,3. 内存队列异步发送机制,四、总结一、写在前面 上一篇文章,我们聊了一下Hadoop中的NameNode里的edits log写机制。 主要分析了edits log写入磁盘和网络的时候,是如何通过分段加锁以及双缓冲的机制,大幅度提升了多线程并发写edits log的吞吐量,从而支持高并发的访问。 如果没看那篇文章的同学,可以回看一下:《放几十亿数据的系统还
-
java - 多语言应用后台系统大家是怎么处理的?
多语言应用后台系统大家是怎么处理的 请教一下大家,比如我要开发一个多语言版本的视频 app,需要投放到欧美市场,以及越南市场,还有就是国内,大家的后台系统是否要根据不同的语言分开做呢?因为 app 的内容是需要根据语言来变的。 比如:视频 a 在欧美市场中,他的视频封面图就需要展示英文的,在国内展示中文的宣传图,在越南展示越南文;首页轮播图也是这样。 还有就是广告,欧美,越南使用谷歌的广告,在国内
-
用ffmpeg怎么把25个小视频组合成一个大视频?
用ffmpeg怎么把25个小视频组合成一个大视频? 每个小视频90X160px,没有声音,只有视频 5行5列 一共25个 以下代码来自网络,但是行不通,小视频没有声音,只有画面
-
 前端 - 大佬们这段代码提示报错,要怎么写啊?
前端 - 大佬们这段代码提示报错,要怎么写啊? -
前端 - 怎么提高页面中大量图表渲染的性能?
我的使用场景是需要批量绘制大量图表,不过这些图表具有一定的规律性,整行或者整列是同类型图表,有什么方式可以优化性能呢?现在问题是当滚动的时候,图表渲染跟不上,滚动交互也不流畅。
-
Python:解释Flask脚本工作的常用方法是什么?
Flask脚本工作的常用方法是: 应用程序的导入路径 或者是Python文件的路径
-
为什么我的ReaderWriter解决方案不工作?java,并发
所以最近我一直在努力思考并发问题。目前,我正在努力寻找读者作家问题的解决方案。 我有一个类文件,它计算读者/作家的数量,并有两个信号量。 当读卡器尝试读取时,只要有写入线程在写入,它就必须等待。当它进入readCount时,readerSemaphore中的readCount会增加 当一个编写器试图进入时,只要有多个读卡器,它就必须等待。当它进入时,获取writerSemaphore并增加writ