《新浪集团》专题
-
Java流-收集、转换和收集
我想获取地图的值,找到min值,并为地图的每个条目构造一个新的CodesWitMinValue实例。我希望使用Java11个流,我可以在多行中使用多个流(一个用于min值,一个用于转换)来实现这一点。是否可以使用java 11流和收集器在单行中实现?谢谢。
-
集合子集的穷举匹配
我有一个关于使用“永远”类型的穷举开关/情况的问题。 比如说,我有一组字符串:{a,B}(字符串可以是任意长的单词,而且集合本身可能非常大),对于每个子集(比如{},{a,B}),我想创建一个函数:show:Set= 预发伪代码: 是否有可能在编译时保证show函数中包含所有可能的子集?所以把C加到集合{A,B,C}需要我扩充show函数吗?并为{C}、{A,C}、{B,C}和{A,B,C}添加案
-
18. 函数的集合与系集
在连续情景中,我们不得不处理函数的集合和函数的系集。由函数集的名字可以看出,它就是一组函数,通常是一个变量——时间的函数。为描述函数集,我们可以给出集合中各种函数的显式表达式,也可以给出只有集合中的函数才拥有的性质。下面是一些示例: 由以下函数组成的集合: 。 的每个具体值确定了集合中的一个特定函数。 一个由时间函数组成的集合,其中包含频率不超过W周期/秒的所有时间函数。 一个由带宽局限于W、幅度
-
 JavaFX:如何在新场景中更新observableArrayList中的选定项。不传递整个支持它的数据集?
JavaFX:如何在新场景中更新observableArrayList中的选定项。不传递整个支持它的数据集?JavaFX:如何在新场景中更新observableArrayList中的选定项。不传递整个支持它的数据集? 我认为只要把一个选定的项传递到新窗口就有意义了。通过这样做,我无法让observableArrayList反映更改。 我只能通过传入整个数据集来使我的程序工作。ArrayList支持observableArrayList和observableArrayList本身。然后在ArrayList
-
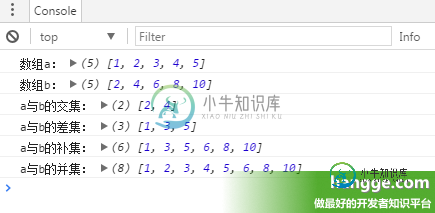 JS计算两个数组的交集、差集、并集、补集(多种实现方式)
JS计算两个数组的交集、差集、并集、补集(多种实现方式)本文向大家介绍JS计算两个数组的交集、差集、并集、补集(多种实现方式),包括了JS计算两个数组的交集、差集、并集、补集(多种实现方式)的使用技巧和注意事项,需要的朋友参考一下 方法一:最普遍的做法 使用 ES5 语法来实现虽然会麻烦些,但兼容性最好,不用考虑浏览器 JavaScript 版本。也不用引入其他第三方库。 1,直接使用 filter、concat 来计算 2,对 Array 进行扩展
-
刷新与刷新
问题内容: 如果将新文档索引到Elasticsearch索引,则可在索引操作后1秒钟左右搜索新文档。但是,可以通过调用或对索引进行操作来强制使该文档可立即搜索。这两个操作之间有什么区别- 结果似乎对他们来说是相同的,可以立即搜索文档。 这些操作中的每一项到底是什么? ES文档似乎并未深入解决此问题。 问题答案: 您得到的答案是正确的,但我认为值得详细说明。 刷新有效地调用了Lucene索引读取器上
-
Java,MongoDB:如何在迭代庞大的集合时更新每个对象?
问题内容: 我收集了约100万条记录,每个记录有20个字段。我需要更新每个记录(文档)中的整数字段,并向该字段随机分配1或2 。在游标遍历整个集合时如何执行此操作?第二次搜索MongoDB已经找到的对象只是为了能够更新它似乎不是一个好主意: 如何有效地更新具有不同值的巨大MongoDB集合的每个文档中的字段? 问题答案: 您的方法基本上是正确的。但是,我不会将这样的集合视为“巨大的”。您可以从sh
-
通过MongoDB集合中的ID搜索数组条目并执行更新
本文向大家介绍通过MongoDB集合中的ID搜索数组条目并执行更新,包括了通过MongoDB集合中的ID搜索数组条目并执行更新的使用技巧和注意事项,需要的朋友参考一下 要通过id搜索数组,请使用position $运算符。要进行更新,请使用MongoDB中的UPDATE。让我们创建一个包含文档的集合- 在方法的帮助下显示集合中的所有文档- 这将产生以下输出- 以下是在MongoDB集合中通过其ID
-
将Jade集成到Yeoman的服务器/监视/重新加载任务中
问题内容: 我一直在和Yeoman&Jade玩耍。我通过创建了一个小型测试应用程序(这是一个有角度的应用程序,但这不是重点)。 当我在命令行输入时,它将: 编译coffeescript和罗盘文件 启动服务器 启动浏览器 在浏览器中观看并重新加载CoffeeScript和指南针更改 Yeoman的一大特色! 现在我想要与Jade相同的功能。 所以我通过安装 grunt-jade并在 GruntFil
-
如何在2.5版本的新flutter模板上集成底部导航栏?
如何在2.5版本的新flutter模板上集成底部导航栏? 我理解了这个原理,但我不能在模板的正文中插入这一行:(这行代码来自flutter doc),因为正文返回一个 谢谢你的帮助! '小部件构建(BuildContext上下文){返回脚手架(appBar: AppBar(title: const Text('Sample Items')),操作:[IconButton(icon: const I
-
Springboot集成测试:在bean初始化之前用pwd更新application.yml属性
我已经编写了Springboot集成测试。src/test/资源中有一个application.yml。yml中有一个属性: 测试中使用的bean必须在bean(类)构造函数中读取这个值“testFilePath”。 就在执行集成测试之前,我希望能够用用户目录(或PWD路径)替换的值。因此,bean初始化具有正确的完整路径,即 我尝试使用BeforeAll()方法,它将取代应用程序。yml文件内容
-
根据一系列值作为截止值生成新的数据子集
我有一个包含压力数据的大型数据集。我希望能够创建多组以各种值过滤的数据(即 例如,这可能与我目前所做的类似: 有没有一种方法可以做到这一点,而不必为每个感兴趣的截止值创建多个单独的数据集,然后单独运行每个分析? 就像如果我想测试多个压力截止值,例如,我不想对序列中生成的每个值重复上述过程。 我考虑过将< code>dplyr与< code>filter()函数一起使用,并手动设置一组值,但这不仅会
-
将Kafka Topic迁移到新集群(以及对德鲁伊特的影响)
我正在从Kafka的话题中摄取数据到德鲁伊。现在,我想将我的Kafka Topic迁移到新的KafkaCluster。在不重复数据和不停机的情况下,有哪些可能的方法可以做到这一点 我考虑了以下将Topic迁移到新Kafka集群的可能方法。 手动迁移: 在新的Kafka集群中创建具有相同配置的主题。 停止在Kafka集群中推送数据。 开始在新集群中推送数据。 停止从旧集群消耗。 从新集群开始消费。
-
如何使用Datastax连接器从Spark Dataframe更新特定的Cassandra列集
我有一个只有几个列的Cassandra表,我想更新其中的一个(对于多个列,还有什么?)来自Spark 2.4.0。但是如果我没有提供所有的列,那么记录就不会得到更新。 Cassandra模式:
-
多个线程是否会在受约束集上导致重复更新?
在postgres中,如果我运行以下语句 在默认的 级别中,我可以保证从多个并发会话中: 在单个匹配的情况下,只有1个线程将获得1的ROWCOUNT(意味着只有一个线程写入) 在多匹配的情况下,只有1个线程将获得ROWCOUNT