《新浪集团》专题
-
Kafka消费集团挂
我正在执行Kafka的ConsumerGroupExample消费程序,它挂起等待消息 它似乎正在挂起等待消息(在https://cwiki.apache.org/confluence/display/kafka/consumer+group+example,在“for(final KafkaStream stream stream:streams)”处等待。 我已经采取的几个步骤:(A)反复停止
-
 象屿集团一面
象屿集团一面云计算运维岗 谈谈虚拟化? 你理解运维是作什么的? 问了问基本情况 凉
-
 阅文集团测开
阅文集团测开十个单选 十个多选 一顿乱蒙 问答题 第一题太长没怎么看 五分 没写,好像是写测试方向 第二题写SQL语句写了三个(10分) 第三题从测试角度写出点击按键后阅读无响应的原因,并写出排查方法(5分) 第四题四个电梯,九层楼,写出测试调度电梯系统的测试用例和预期结果 编程题 删除字符串中的星号 全为星号直接输出 最后没时间了只过了2/3的测试用例
-
选择器div + p(加号)和div〜p(波浪号)之间的差异
问题内容: 选择所有紧随元素之后的元素 选择元素前面的每个元素 如果一个元素紧接在一个元素之后,那是否不意味着该元素前面有一个元素? 无论如何,我正在寻找一个选择器,可以在其中选择紧接 在 给定元素 之前 的元素。 问题答案: 相邻的兄弟选择器X + Y 相邻的同级选择器具有以下语法:E1 + E2,其中E2是选择器的主题。如果E1和E2在文档树中共享相同的父项,并且E1紧随E2而不考虑非元素节点
-
流浪者同步的文件夹无法在VirtualBox上实时工作
问题内容: 我的已同步文件夹无法正常工作,它们在启动时已被一次性同步,但是当我在主机上进行更改时,vagrant无法实时进行同步。 首先,我的系统上有一些细节: OS: Linux Mint 18 Sarah Virtualbox version: 5.0.24-dfsg-0ubuntu1.16.04.1 Vagrant version: 1.9.0 vagrant-hostmanager (1.
-
如何查找所有文件名以波浪号结尾的文件
问题内容: 我使用Emacs,有时会备份已编辑的文件。几天后,我会有很多备份文件,它们的名称以波浪号结尾。 有没有办法找到这些文件并立即将其删除? 我尝试了这个: 但这是行不通的。我希望命令可以递归工作-类似于。 问题答案: 您需要从外壳中脱身。而且您需要指定搜索路径,而不是 删除文件:
-
数据库索引:是好事还是坏事还是浪费时间?
问题内容: 此处通常建议添加索引,以解决性能问题。 (我只在说阅读和查询,我们都知道索引会使写入变慢)。 多年来,我已经在DB2和MSSQL上尝试了很多方法,结果总是令人失望。 我的发现是,无论索引有多“明显”,它都会使事情变得更好。事实证明,查询优化器更智能,而我的明智选择的索引几乎总是使事情变得更糟。 我应该指出,我的经验主要与小型表(<100‘000行)有关。 谁能提供一些切实可行的索引选择
-
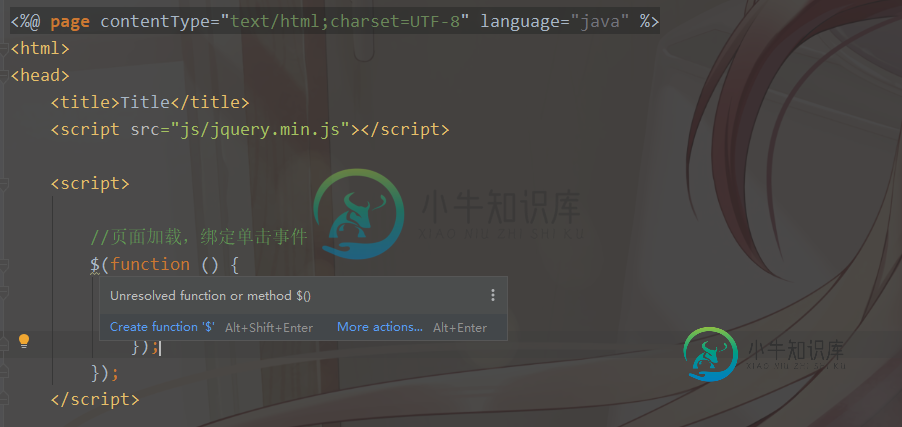 IDEA配置jQuery, $符号不再显示黄色波浪线的问题
IDEA配置jQuery, $符号不再显示黄色波浪线的问题本文向大家介绍IDEA配置jQuery, $符号不再显示黄色波浪线的问题,包括了IDEA配置jQuery, $符号不再显示黄色波浪线的问题的使用技巧和注意事项,需要的朋友参考一下 在使用IDEA搭建Maven的Web环境时,编写的JQuery入口函数时,遇到了未知符号的提示,并且在前端页面js的console里报错。 以下是错误信息: 解决方案: 继续看图: 配置成功生效: 到此这篇关于IDEA配
-
RVM安装,但没有与厨师索洛和流浪汉红宝石?
我正在使用Chef solo、Berkshelf和Vagrant来尝试构建一个开发环境。我还有其他的菜谱,但是“chef rvm”菜谱给我安装ruby版本带来了麻烦。 要明确的是,RVM正在安装,但当我在vbox中输入“vagrant ssh”并键入“RVM list”时,它表示没有安装rubies。我可以输入“rvm install 2.1.1”,它可以工作,所以我不确定Chef为什么不安装它。
-
不浪费一个条目或使用计数器的循环队列
2.它指向将要插入下一个元素的地方 在这两种情况下,如果我们没有浪费数组的至少一个条目,或者如果我们没有保持计数器计数,我们就无法区分full和empty队列
-
如何将字符串从 JSON 返回到 C 调用方(高浪 CGO)?
我正在尝试在Go中开发一个将由C程序调用的例程。Go如下所示: 如果我用一些硬编码的值替换return k.Key语句,则一切正常,C或C可以调用导出的GetKey函数。当我尝试从k.Key返回解码的JSON字符串,甚至只是从名为body的变量返回字符串时,我收到一个错误: 运行时错误:cgo结果具有go指针Go routine 17[正在运行,锁定到线程] 我按如下方式构建它: 去构建 -构建模
-
虚拟盒子流浪汉 centos8 盒子 (无头) 从互联网访问
我成功地用centos8. yum package manger、openssl-server、openssl-client设置了流浪汉虚拟盒子,所有这些都更新了。 sshd服务正在运行。 盒子启动没有任何问题,我能够使用提示输入密码并能够登录。 从部署阶段的gitlag-ci.yml文件中,我试图使用访问centos8框,但它在22端口上超时。 我厌倦了和没有任何效果。 但是我能够使用我的命令W
-
何时使用集合与集合?
问题内容: 除了a 和Java 可以两次包含相同的元素外,a 和Java 之间在实践上还有什么区别吗?它们具有相同的方法。 (例如,是否给我更多选择来使用接受s但不接受s的库?) 编辑: 我可以认为至少有5种不同的情况来判断这个问题。其他人还能提出更多建议吗?我想确保我了解这里的微妙之处。 设计接受或参数的方法。更通用,并接受更多输入可能性。(如果我正在设计特定的类或接口,那么对我的消费者会更好,
-
Java中ArrayList的交集和并集
问题内容: 有什么方法可以这样做吗?我一直在寻找,但找不到任何东西。 另一个问题:我需要这些方法,以便可以过滤文件。有些是AND过滤器,有些是OR过滤器(类似于集合论),因此我需要根据所有文件以及保存这些文件的unite / intersects ArrayLists进行过滤。 我是否应该使用其他数据结构来保存文件?还有其他什么可以提供更好的运行时间吗? 问题答案: 这是不使用任何第三方库的简单实
-
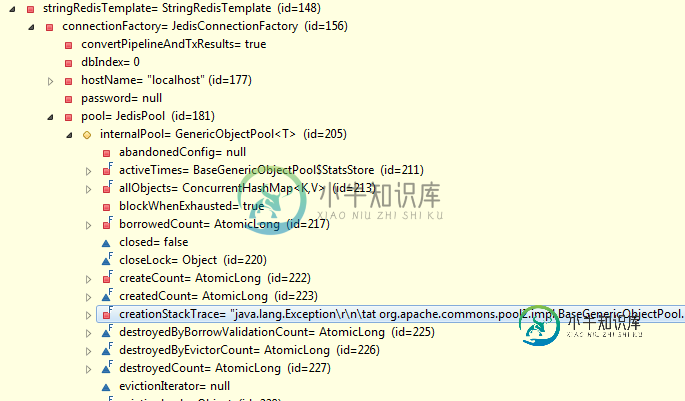 Redis集群与Spring boot的集成
Redis集群与Spring boot的集成我有一个redis集群,有主服务器、从服务器和3个哨兵服务器。主从映射到dns名称node1-redis-dev.com、node2-redis-dev.com。redis服务器版本为2.8 我在application.properties文件中包含以下内容。 但是,当我检查StringRedisTemplate时,在JedisConnectionFactory的hostName属性下,我看到的是