《猫眼娱乐》专题
-
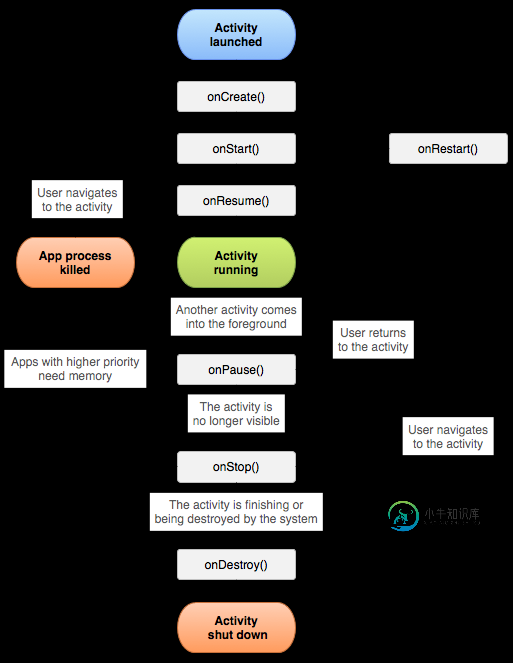 故事讲解Activity生命周期(猫的一生)
故事讲解Activity生命周期(猫的一生)本文向大家介绍故事讲解Activity生命周期(猫的一生),包括了故事讲解Activity生命周期(猫的一生)的使用技巧和注意事项,需要的朋友参考一下 大家好,关于Android中Activity的生命周期,网上大多数文章基本都是直接贴图、翻译API,比较笼统含糊不清。 我就用故事来说一说: 有个人叫User,TA养了几只猫,有只猫叫Activity。User见证了Activity猫的一生。 Us
-
通过包含str过滤熊猫数据框行
问题内容: 我有很多行的python pandas数据框。从这些行中,我想切出并且仅使用“ body”列中包含单词“ ball”的行。为此,我可以这样做: 问题是,我希望它不区分大小写,这意味着如果出现Ball或bAll一词,我也希望它们。进行不区分大小写的搜索的一种方法是将字符串转换为小写,然后以这种方式搜索。我想知道如何去做。我试过了 但这是行不通的。我不确定是否应该在此等性质上使用lambd
-
熊猫在布尔索引中使用行标签
问题内容: 所以我有一个像这样的DataFrame: 我们可以像这样对它进行布尔索引 我们还可以通过行标签将其切片,如下所示: 我想同时执行这两个操作(因此,避免只做行标签过滤器而不必要地复制)。我将如何去做? 我要寻找的伪代码: 问题答案: 您几乎拥有它:
-
蟒蛇熊猫平均值和加权平均值
我是新来的。任何帮助都将不胜感激 这是我的原始数据: 我想得到的是: 1创建一个新的列调用平均值,以计算每个提要的平均市值。 2求加权平均数。 这是我当前的代码,我得到NaN: 对于加权平均代码: 我得到了一个错误: AttributeError:“Series”对象没有属性“value”
-
所有熊猫列显示为字符串[重复]
我正在从数据库中获取数据,我怀疑其中的所有数据都被简单地设置为string,而不是float、int等。当我将数据导入到pandas dataframe中时,所有数据都显示为字符串。 或 我试过str.isNumeric,但所有内容都显示为非数字。 我能做些什么来检测数值吗?
-
str和对象类型之间的熊猫区别
问题内容: Numpy似乎在和类型之间进行了区分。例如我可以做:: 其中dtype(’S’)和dtype(’O’)分别对应于和。 但是熊猫似乎就缺少了区分,并要挟到。:: 强制类型也无济于事。:: 此行为有任何解释吗? 问题答案: Numpy的字符串dtypes不是python字符串。 因此,故意使用本机python字符串,这需要对象dtype。 首先,让我演示一下numpy的字符串与众不同的含义
-
熊猫离开加入并更新现有专栏
问题内容: 我是熊猫的新手,似乎无法将此功能与merge函数配合使用: 在列a左连接时,我想通过JOINED KEYS更新公共列。请注意,c列中的最后一个值来自LEFT表,因为没有匹配项。 如何使用Pandas合并功能执行此操作?谢谢。 问题答案: 一种方法是将a列设置为索引和: 注意:仅执行左联接(不合并),因此,除了set_index之外,还需要包括中不存在的其他列。
-
猫鼬模式引用和未定义类型“ ObjectID”
问题内容: 我正在尝试在架构之间建立某种关系,而解决方案存在一些问题。这是我的设备架构: 这里是房间模式: 猫鼬抛出错误 类型错误:未定义的类型,在 你尝试筑巢的架构?您只能使用引用或数组进行嵌套。 如果我更改为一切正常。您能解释一下为什么会这样吗? 问题答案: 是构造函数,要在模式定义中使用的是(或)。 所以应该看起来像这样:
-
猫鼬-RangeError:超出最大调用堆栈大小
问题内容: 我试图将文档批量插入MongoDB中(因此绕过Mongoose并使用本机驱动程序,因为Mongoose不支持批量插入文档数组)。我这样做的原因是为了提高写作速度。 我在以下代码中的console.log(err)处收到错误“ RangeError:超出最大调用堆栈大小”: 也许与Mongoose返回的响应数组的格式有关,这意味着我不能直接使用MongoDB进行本机插入吗?我已经在每个响
-
我如何安装模块,如(熊猫/openpyxl)[复制]
好的,我刚刚开始学习python。我使用py魅力当前写的代码。我只是不明白我是如何安装模块的。例如,我希望加载excel文件。我已经看到可以使用熊猫或openpyxl,但我不知道如何访问这些模块。我在网上看到的所有视频只需键入安装openpyxl或pip安装熊猫。“安装”在我的窗口上不是一个有效的功能。其他功能出现突出显示之前,我完成它们和安装似乎是不认识,一旦执行我得到一个语法错误的安装。安装前
-
将熊猫系列转换为numpy数组[重复]
我不熟悉熊猫和蟒蛇。我的输入数据如下 这里Y是panda系列对象,我想将其转换为numpy数组。所以我试过了,就像矩阵一样 但是我得到的输出是[1,1](这是错误的,因为我只有一个列类别和两行)。我希望结果是2x1矩阵。
-
熊猫创建只有列名的空数据框
我有一个运行良好的动态数据帧,但是当没有数据添加到数据帧中时,我会得到一个错误。因此,我需要一个解决方案来创建一个只有列名的空数据帧。 现在我有这样的东西: PS:列名仍然出现在数据帧中是很重要的。 但当我这样使用它时,我得到的结果是: “空数据帧”部分不错!但是我仍然需要显示列,而不是索引。 编辑: 我发现了一件重要的事情:我正在使用Jinja2将此数据帧转换为PDF,因此我调用了一个方法,首先
-
更好的方法来减少熊猫的繁殖
我自己找到了一种从熊猫数据帧中删除nan行的方法。给定一个包含nan值的列为的数据帧,是否有更优雅的方法来删除列中包含nan值的每一行?
-
从不同的数据帧更新/替换熊猫
我有两个数据帧:df1和df2。df1有列['UserId'、'company'、'deg'],有100个观察值。df2有列['UserId','deg',],有10个观察值。df1和df2中的索引与“userId”完全匹配。 我想用df2中的更新df1。df2中的“UserId”列是df1中“UserId”列的子集……因此,没有任何附加内容。仅基于“userId”(和/或普通索引)。 df1 d
-
熊猫:子索引数据帧:副本与视图
假设我有一个数据帧 我从我的数据子集创建另一个数据帧: 是否保存了中这些元素的副本?有没有办法创建该数据的?如果是这样,如果我尝试修改此视图中的数据会发生什么情况?Pandas是否提供任何类型的写时拷贝机制?