《储存卡》专题
-
 模拟存储库JUnit时的NullPointerException
模拟存储库JUnit时的NullPointerException我已经创建了一个包含控制器、服务和存储库层的基本Rest API。我现在正在尝试为通过产品ID查找产品的服务层方法编写一个单元测试。但是,当我运行测试时,它会在我试图模拟存储库findById()方法的行中抛出一个NullPointerException。 服务层中的getProductById()方法如下所示: 我的服务层测试类:
-
自定义存储库基类+QueryDslPredicateExecutor
我发现对于减少样板非常有用,但它似乎给工作带来了麻烦。我现在试图用自定义的基类存储库扩展,而在启动时,Spring在正确实例化存储库方面遇到了问题。 我已经尝试了几个关于这个主题的变体,但是没有运气让事情成功地连线起来。我在Spring的问题跟踪器https://jira.spring.io/browse/datajpa-674上遇到了一个类似的问题,但没有关于修复的解释,只是对代码进行了重构,使
-
将MemoryStream文件存储到Azure Blob
我有一个通过System.Drawing动态生成的图像。然后,我将生成的图像输出到以存储到我的Azure blob中。 但我似乎无法将我的文件存储在我选择的blob中。没有发生错误,并且我的图像成功地保存到。不出所料,我的blob是空的。 到 但我会标记“Gaurav Mantri”的回应是正确的。如果不是他的洞察力,我的图像就不会上传到Blob上。
-
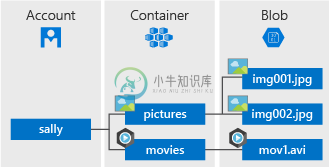 了解Azure Block Blob存储限制
了解Azure Block Blob存储限制我对block blob存储是如何工作的有点困惑,所以我对这些限制是如何工作的有点困惑(从我读到的内容来看,大多数人甚至不会接近这些限制,但我仍然想知道它是如何应用的)。我一直在读这篇文章 限制似乎是这样的 块BLOB存储文本和二进制数据,最多约4.7TB。块BLOB由可以单独管理的数据块组成。 或者block blob是否意味着如果我有img001并且它是1GB,它将被分离成块,并且限制为50,
-
Delphi XE5 Android-存储路径问题
我开始在Delphi XE5中为android开发应用程序,遇到了一些问题。 我真的不懂怎么找路。在我设置了写入和读取外部存储的权限后,我尝试获取路径,以便查看我将创建的文件保存在何处,我得到的结果如下: 对于系统。尤蒂尔斯。第四- 据我从其他主题了解,GetDocumentsPath应该是默认的sdcard路径,下载应该是sdcard/Downloads,但它使用/Android/data/ap
-
机房数据库存储结构
Room存储数据库的位置以及如何强制重新生成数据库?我尝试在以下位置查找DB: 我想使用SQLLite看看数据库中到底有什么数据,所以我按照“Access database in Android Studio”的方向操作,但我只看到一个缓存和codecache目录存储在那里。没有数据库目录。 想要查看DB的原因是我更改了模型以添加几个字段,但我想不出如何强制使用Room来重新创建并用数据重新填充D
-
Netbeans Maven(更新中央存储库)
由于“需要HTTPS”错误,我最近在构建项目时遇到了问题。这个问题通过如下所述修改我的pom.xml得到了解决,添加了以下内容: 然而,为我的每个项目更新每个pom.xml是一件麻烦的事。 我尝试将相同的代码片段添加到我的settings.xml,但没有成功。 我知道更新版本的Maven解决了这个问题。然而,由于工作限制,我无法更新我的环境。 我目前已经安装了Java8和Maven,由Netbea
-
 分布式存储 春招面经
分布式存储 春招面经之前的秋招面经:深信服 Go 开发面经(已 offer) bg:专升本+ACM银牌+三个项目(一个毕设的KV分离LSM-Tree,一个6824的分布式KV,一个OJ) 某小厂,存储方向技术积累还不错,避免定位就不写具体名字了。自己也一直比较憧憬做 infra 吧,不想写 CRUD 业务,所以就投了。面试内容都是事后回忆,可能有遗漏或记错的 一面 50min 自我介绍 项目实现细节、设计考量、优化(
-
4.5 数据库的存储引擎
ZtbCMS数据库的存储引擎 ZtbCMS所有表的存储引擎(包括创建模型)默认是: InnoDB [从v3.2.0.0] 考虑到大部分情况下: 对事务需要不高,除了支付,余额统计,收益记录等 查询远大于插入 MyISAM 本身支持FULLTEXT索引,InnoDB直到My SQL 5.6.4才支持 若需要事务需求,请自行对该表的存储引擎改为 InnoDB 阅读参考 MySQL 5.5手册 - 存储
-
存储后端 - Amazon S3 下安装
Note: Seafile 服务器 5.0.0 之后,所有配置文件都移动到了统一的 conf 目录下。 了解详情. 准备工作 为了安装 Seafile 专业版服务器并使用亚马逊 S3,您需要: 按照 下载安装 Seafile 专业版服务器 指南安装基本的 Seafile 专业版服务器。 安装 python 的 boto 库。它可以用来访问 S3 服务。 sudo easy_install boto
-
打印和存储透明图稿
关于拼合 包含透明度的文档或作品进行输出时,通常需要进行 “拼合 ”处理。拼合将透明作品分割为基于矢量区域和光栅化的区域。作品比较复杂时(混合有图像、矢量、文字、专色、叠印等),拼合及其结果也会比较复杂。 当您打印或保存或导出为其它不支持透明的格式时,可能需要进行拼合。要在创建 PDF 文件时保留透明度而不进行拼合,请将文件保存为 Adobe PDF 1.4 (Acrobat 5.0) 或更高版本
-
第十八章:客户端存储
web应用允许使用浏览器提供的API实现将数据存储在用户电脑上。这种客户端存储相当于赋予了web浏览器记忆功能。比方说,web应用就可以用这些方式来“记住”用户的偏好甚至是用户的所有状态信息,以便准确地“回忆”起用户上一次访问的位置。客户端存储遵循“同源策略”,因此不同站点的页面是无法读取对于存储的数据。而同一站点的不同的页面之间是可以互相共享存储数据的,它为我们提供了一种通信机制,例如一个表单的
-
使用OpenEBS做持久化存储
本文将指导您如何在Kubernetes集群上安装OpenEBS作为持久化存储。 我们将使用Operator的方式来安装OpenEBS,安装之前需要先确认您的节点上已经安装了iSCSI。 先决条件 OpenEBS依赖与iSCSI做存储管理,因此需要先确保您的集群上已有安装openiscsi。 注意:如果您使用kubeadm,容器方式安装的kublet,那么其中会自带iSCSI,不需要再手动安装,如果
-
使用Ceph做持久化存储
本文中用到的 yaml 文件可以在 ../manifests/mariadb-cluster 目录下找到。 下面我们以部署一个高可用的 MySQL 集群为例,讲解如何使用 Ceph 做数据持久化,其中使用 StorageClass 动态创建 PV,Ceph 集群我们使用 kubernetes 集群外部的已有的集群,我们没有必要重新部署了。 在 1.4 以后,kubernetes 提供了一种更加方便
-
使用GlusterFS做持久化存储
我们复用kubernetes的三台主机做glusterfs存储。 以下步骤参考自:https://www.xf80.com/2017/04/21/kubernetes-glusterfs/(该网站已无法访问) 安装glusterfs 我们直接在物理机上使用yum安装,如果你选择在kubernetes上安装,请参考:https://github.com/gluster/gluster-kuberne