《储存卡》专题
-
创建一个连接,将字符串存储为键,字节数组存储为值
我有一个Spring boot应用程序,可以连接到AWS上的Redis集群。我正在尝试莴苣,想创建一个,用于将键存储为字符串,而将值存储为字节数组。我尝试使用内置的,但它将键和值都作为字节数组。 我刚接触莴苣,所以我不确定是否需要编写自定义编解码器。如果是,我该怎么写?是否会出现性能问题?还是我走错了路?
-
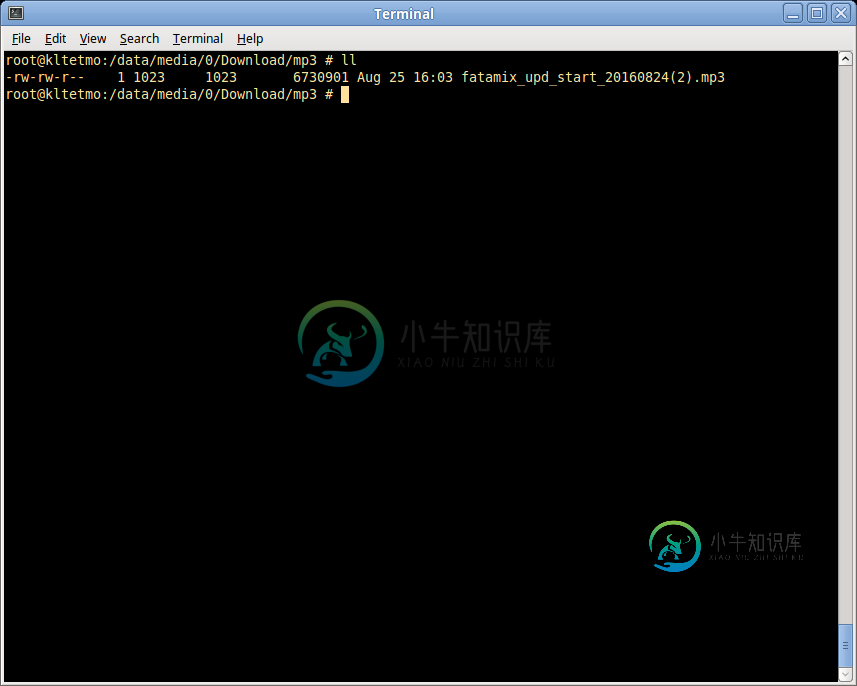 移动mp3文件从内部存储到外部存储。文件不再被识别
移动mp3文件从内部存储到外部存储。文件不再被识别为了清理一些磁盘空间,我将我的mp3收藏从内部存储移到外部存储。我的设备是根的,当时我是。 文件可以看到(和播放)从文件管理器,但我的音乐播放器没有看到他们。 看起来有趣的是移动后的文件权限。这是一个文件仍然在内部存储,但没有移动。 下面是几个被移到外部存储的文件: 将它们移动到外部存储似乎更改了权限。不幸的是,不会影响实际的文件权限: 我尝试将文件移回内部存储以更改那里的权限。直到我将文件移回外
-
相互认证的密钥存储库/信任存储库中必须包含什么?
我正在尝试用Java执行相互身份验证。我试图实现的结构是:具有自签名证书的服务器充当CA,对客户端证书进行签名。因此,这就是我在每个密钥库/信任库中保存的内容: 客户: 密钥库: 客户端的SSL密钥对。 由服务器签署的证书(与密钥对相关)。 信任库: 服务器的自签名证书 服务器 密钥库: 服务器的SSL密钥对。 自签名证书(与密钥对相关)。 信任库: 服务器的自签名证书 我能够执行服务器的身份验证
-
将JRE设置为使用Windows信任存储,特别是用户的信任存储
摘要:Java选项允许Java使用计算机帐户的Windows信任存储。什么选项允许它对用户帐户使用Windows信任存储? 我们有一个在Windows客户端上运行的Java应用程序。应用程序从各种来源获取数据,其中一些来源使用的证书不在默认的文件中。 当用户选择访问外部数据的项目时,系统会提示他们下载外部站点的证书。由于我们的安全设置,文件对用户是只读的。由于JRE无法将证书导入,因此无法下载外部
-
 上载后Azure存储zip文件损坏(使用Azure存储Blob客户端库Java)
上载后Azure存储zip文件损坏(使用Azure存储Blob客户端库Java)问题:从数据生成的包含csv文件的zip文件在上传到Azure Blob存储后似乎已损坏。 上传前的zip文件如下所示: 在上传过程中,我使用了Azure Storage Blob client library for Java(12.7.0版,但我也尝试了以前的版本)。这是我使用的代码(类似于SDK自述文件中提供的示例): 我得到了上传的文件: 当我直接从storage explorer下载文件
-
尝试将映像从firebase数据库获取到存储时出现存储异常
我正在尝试将一个图像存储到FireBase数据库中,我很确定所有的代码都可以很好地获取imagelink,因为它不再像以前那样显示错误。然而现在,当我上传图片时,出现了一个新问题。这与存储异常有关,我猜它在实际从存储中提取imagelink并将其插入数据库时遇到了问题。下面是我认为出现问题的代码: 如果需要,这是我的整个代码: } 错误消息: 2020-06-02 13:54:22.594 346
-
通过ARM向现有密钥存储库添加密钥存储库访问策略
我试图在Azure Devops中进行ARM部署,从而在Azure中的现有密钥存储库中添加密钥存储库访问策略。
-
在Redis缓存中存储多个版本的数据
问题内容: 我有一些产品数据需要在Redis缓存中存储多个版本。数据是JSON序列化的。获取纯(基本)数据的过程非常昂贵,将其自定义为不同版本的过程也很昂贵,因此我想缓存所有版本以尽可能进行优化。假设自定义基于单个参数,我可以将该参数用作缓存键的一部分。 我计划用来检索产品数据的过程是这样的: 一切都很好,但是我现在正在尝试找出在基础数据源发生更改时使缓存数据无效的最佳方法。如果基本产品信息发生变
-
PHP基于文件存储实现缓存的方法
本文向大家介绍PHP基于文件存储实现缓存的方法,包括了PHP基于文件存储实现缓存的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP基于文件存储实现缓存的方法。分享给大家供大家参考。具体如下: 在一些数据库数据记录较大,但是服务器有限的时候,可能一条MySQL查询就会好几百毫秒,一个简单的页面一般也有十几条查询,这个时候也个页面加载下来基本要好几秒了,如果并发量高的话服务器基本就瘫
-
MIPS中是否存在执行存储数据危险?
在具有管道和转发功能的MIPS体系结构上: add指令将在步骤3(执行操作)准备好结果,但我假设sw指令希望在步骤2(指令解码)得到结果 David A. Patterson的《计算机组织与设计》一书中有一个已解决的练习:在以下代码段中找到危险并重新排序指令以避免任何管道停滞: 解决方案: 在解决方案中,它正确识别加载使用危险并相应地重新排列代码,但是否也存在执行存储危险?
-
在Redis缓存中存储多个版本的数据
我有一些需要在Redis缓存中存储多个版本的产品数据。数据是JSON序列化的。获取普通(基本)数据的过程是昂贵的,将其定制成不同版本的过程也是昂贵的,因此我希望缓存所有版本以尽可能优化。假设定制是基于一个参数的,我可以使用该参数作为缓存键的一部分。 我计划用于检索产品数据的过程如下所示: 所有这些工作都很好,但我现在正在尝试找出当底层数据源更改时使缓存数据无效的最佳方法。如果基本产品信息发生变化,
-
将 EhCache 磁盘存储内容加载到内存中
如EhCache留档所述: 实际上,这意味着持久性内存中缓存将启动,其所有元素都将在磁盘上。[...]因此,Ehcache设计不会在启动时将它们全部加载到内存中,而是根据需要懒惰地加载它们。 我希望内存缓存启动时将所有元素都存储在内存中,我该如何实现? 这是因为我们的网站对缓存执行了大量的访问,所以我们第一次访问网站时,它的响应时间非常长。
-
Spring网关Redis会话存储类型-保存问题
我有一个微服务架构中的spring网关。 当请求到达网关时,它必须以下面提到的方式进行操作 创建会话并设置属性 在redis中保存会话 将请求路由到Microservice B Microservice B接收会话ID并从会话获取属性 在尝试实现这一点时,(第2点)保存会话ID的操作发生在调用microservices B并返回其响应(第4点)之后。(即第2点发生在第4点之后)。 但是,在请求被路
-
Database ricks将Rdata文件保存到AWS S3存储桶
我使用数据砖在R中开发了一个模型。我想将输出数据文件保存在 AWS S3 存储桶上,但当我保存文件如下时,它不会保存到挂载的驱动器。 使用R将数据挂载到S3的最佳方法是什么? 我已经尝试了下面的示例代码,它可以工作,所以我知道我在AWS和Database ricks之间的连接可以工作。
-
基元数组存储在 JVM 内存中的位置
JVM内存分为:1.方法区2.堆区3.堆栈4.PC寄存器5.本机堆栈 > 现在假设我有一个属性为“int[]dealCodes”(int基元数组)的类。根据内存管理,一旦处理代码初始化,内存中就会有连续内存分配(total_elements*4字节)。所以,如果数组大小为10,则JVM内存中有40字节的分配。 我的问题是,这40个字节将分配到哪个区域(堆还是堆栈)? 我对数组的理解是:它就像任何其