《go语言》专题
-
Go语言并发通信
通过上一节《 Go语言goroutine》的学习,关键字 go 的引入使得在Go语言中并发编程变得简单而优雅,但我们同时也应该意识到并发编程的原生复杂性,并时刻对并发中容易出现的问题保持警惕。 事实上,不管是什么平台,什么编程语言,不管在哪,并发都是一个大话题。并发编程的难度在于协调,而协调就要通过交流,从这个角度看来,并发单元间的通信是最大的问题。 在工程上,有两种最常见的并发通信模型:共享数据
-
Go语言并发简述
主要内容:Goroutine 介绍,channel有人把Go语言比作 21 世纪的C语言,第一是因为Go语言设计简单,第二则是因为 21 世纪最重要的就是并发程序设计,而 Go 从语言层面就支持并发。同时实现了自动垃圾回收机制。 Go语言的并发机制运用起来非常简便,在启动并发的方式上直接添加了语言级的关键字就可以实现,和其他编程语言相比更加轻量。 下面来介绍几个概念: 进程/线程 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个
-
Go语言sync包与锁
主要内容:为什么需要锁,互斥锁 Mutex,读写锁Go语言中 sync 包里提供了互斥锁 Mutex 和读写锁 RWMutex 用于处理并发过程中可能出现同时两个或多个协程(或线程)读或写同一个变量的情况。 为什么需要锁 锁是 sync 包中的核心,它主要有两个方法,分别是加锁(Lock)和解锁(Unlock)。 在并发的情况下,多个线程或协程同时其修改一个变量,使用锁能保证在某一时间内,只有一个协程或线程修改这一变量。 不使用锁时,在并发的情况
-
Go语言import导入包
主要内容:默认导入的写法,导入包后自定义引用的包名,匿名导入包——只导入包但不使用包内类型和数值,包在程序启动前的初始化入口:init,理解包导入后的init()函数初始化顺序可以在一个 Go语言源文件包声明语句之后,其它非导入声明语句之前,包含零到多个导入包声明语句。每个导入声明可以单独指定一个导入路径,也可以通过圆括号同时导入多个导入路径。要引用其他包的标识符,可以使用 import 关键字,导入的包名使用双引号包围,包名是从 GOPATH 开始计算的路径,使用 进行路径分隔。 默认导入的写
-
 Go语言自定义包
Go语言自定义包包是Go语言中代码组成和代码编译的主要方式。关于包的基本信息我们已经在前面介绍过了,本节我们主要来介绍一下如何自定义一个包并使用它。 到目前为止,我们所使用的例子都是以一个包的形式存在的,比如 main 包。在Go语言里,允许我们将同一个包的代码分隔成多个独立的源码文件来单独保存,只需要将这些文件放在同一个目录下即可。 我们创建的自定义的包需要将其放在 GOPATH 的 src 目录下(也可以是
-
Go语言类型分支
主要内容:类型断言的书写格式,使用类型分支判断基本类型,使用类型分支判断接口类型type-switch 流程控制的语法或许是Go语言中最古怪的语法。 它可以被看作是类型断言的增强版。它和 switch-case 流程控制代码块有些相似。 一个 type-switch 流程控制代码块的语法如下所示: 输出结构如下: Type Square *main.Square with value &{5} 变量 t 得到了 areaIntf 的值和类型, 所有 case 语句中列举的类型
-
Go语言类型断言
类型断言(Type Assertion)是一个使用在接口值上的操作,用于检查接口类型变量所持有的值是否实现了期望的接口或者具体的类型。 在Go语言中类型断言的语法格式如下: value, ok := x.(T) 其中,x 表示一个接口的类型,T 表示一个具体的类型(也可为接口类型)。 该断言表达式会返回 x 的值(也就是 value)和一个布尔值(也就是 ok),可根据该布尔值判断 x 是否为 T
-
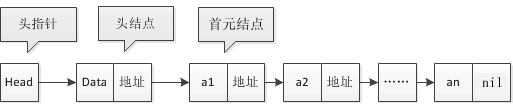 Go语言链表操作
Go语言链表操作主要内容:单向链表,循环链表,双向链表链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。 链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 使用链表结构可以避免在使用数组时需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去
-
Go语言构造函数
主要内容:多种方式创建和初始化结构体——模拟构造函数重载,带有父子关系的结构体的构造和初始化——模拟父级构造调用Go语言的类型或结构体没有构造函数的功能,但是我们可以使用结构体初始化的过程来模拟实现构造函数。 其他编程语言构造函数的一些常见功能及特性如下: 每个类可以添加构造函数,多个构造函数使用函数重载实现。 构造函数一般与类名同名,且没有返回值。 构造函数有一个静态构造函数,一般用这个特性来调用父类的构造函数。 对于 C++ 来说,还有默认构造函数、拷贝构造函数等。 多种方式创建和初始化结构
-
Go语言递归函数
主要内容:斐波那契数列,数字阶乘,多个函数组成递归很对编程语言都支持递归函数,Go语言也不例外,所谓递归函数指的是在函数内部调用函数自身的函数,从数学解题思路来说,递归就是把一个大问题拆分成多个小问题,再各个击破,在实际开发过程中,递归函数可以解决许多数学问题,如计算给定数字阶乘、产生斐波系列等。 构成递归需要具备以下条件: 一个问题可以被拆分成多个子问题; 拆分前的原问题与拆分后的子问题除了数据规模不同,但处理问题的思路是一样的; 不能无限制的
-
Go语言可变参数
主要内容:可变参数类型,任意类型的可变参数,遍历可变参数列表——获取每一个参数的值,获得可变参数类型——获得每一个参数的类型,在多个可变参数函数中传递参数在C语言时代大家一般都用过 printf() 函数,从那个时候开始其实已经在感受可变参数的魅力和价值,如同C语言中的 printf() 函数,Go语言标准库中的 fmt.Println() 等函数的实现也依赖于语言的可变参数功能。 本节我们将介绍可变参数的用法。合适地使用可变参数,可以让代码简单易用,尤其是输入输出类函数,比如日志函数等。 可变
-
Go语言匿名函数
主要内容:定义一个匿名函数,匿名函数用作回调函数,使用匿名函数实现操作封装Go语言支持匿名函数,即在需要使用函数时再定义函数,匿名函数没有函数名只有函数体,函数可以作为一种类型被赋值给函数类型的变量,匿名函数也往往以变量方式传递,这与C语言的回调函数比较类似,不同的是,Go语言支持随时在代码里定义匿名函数。 匿名函数是指不需要定义函数名的一种函数实现方式,由一个不带函数名的函数声明和函数体组成,下面来具体介绍一下匿名函数的定义及使用。 定义一个匿名函数 匿名函数的定义格
-
Go语言函数变量
在Go语言中,函数也是一种类型,可以和其他类型一样保存在变量中,下面的代码定义了一个函数变量 f,并将一个函数名为 fire() 的函数赋给函数变量 f,这样调用函数变量 f 时,实际调用的就是 fire() 函数,代码如下: 代码输出结果: fire 代码说明: 第 7 行,定义了一个 fire() 函数。 第 13 行,将变量 f 声明为 func() 类型,此时 f 就被俗称为“回调函数”,
-
Go语言函数声明
主要内容:普通函数声明(定义),函数的返回值,调用函数函数构成了代码执行的逻辑结构,在Go语言中,函数的基本组成为:关键字 func、函数名、参数列表、返回值、函数体和返回语句,每一个程序都包含很多的函数,函数是基本的代码块。 因为Go语言是编译型语言,所以函数编写的顺序是无关紧要的,鉴于可读性的需求,最好把 main() 函数写在文件的前面,其他函数按照一定逻辑顺序进行编写(例如函数被调用的顺序)。 编写多个函数的主要目的是将一个需要很多行代码的复
-
Go语言键值循环
主要内容:遍历数组、切片——获得索引和值,遍历字符串——获得字符,遍历 map——获得 map 的键和值,遍历通道(channel)——接收通道数据,在遍历中选择希望获得的变量for range 结构是Go语言特有的一种的迭代结构,在许多情况下都非常有用,for range 可以遍历数组、切片、字符串、map 及通道(channel),for range 语法上类似于其它语言中的 foreach 语句,一般形式为: for key, val := range coll { ... } 需