《吐槽面试》专题
-
为什么kafka producer(perf测试)会有如此低的吞吐量/高的延迟?
我是Kafka的新手,正在运行一些性能测试。我正在运行一个由我的笔记本电脑和一个raspberry pi zero W(1 GHz、单核CPU、512 MB RAM、802.11n无线局域网)组成的2台机器集群。最终,pi将运行一个单独的生成器(java),该生成器将二进制传感器数据(理想情况下是更小的记录,例如,10 kb,以最快的速度)发送给kafka,然后由消费者在我的笔记本电脑或另一个pi
-
举例说明React的插槽有哪些运用场景?
本文向大家介绍举例说明React的插槽有哪些运用场景?相关面试题,主要包含被问及举例说明React的插槽有哪些运用场景?时的应答技巧和注意事项,需要的朋友参考一下 对于 portal 的一个典型用例是当父组件有 overflow: hidden 或 z-index 样式,但你需要子组件能够在视觉上 “跳出(break out)” 其容器。例如,对话框、hovercards以及提示框。所以一般rea
-
提交槽Ajax时如何获取nicEdit表单的内容?
问题内容: 所以我要做的是使用jQuery的AJAX函数提交表单。我选择的路线是使用$(’#form’)。serialize(); 然后将其作为GET请求传递。在我添加要在网站上使用的编辑器NicEdit之前,它可以解决所有花花公子的问题。 我已经研究了这个问题,情况是这样的,例如,一旦NicEdit接管了一个文本区域,它将对用户隐藏该文本区域,而是将其写入。然后,将这些数据放回普通提交按钮触发的
-
如何处理Kafka连接水槽中的背压?[关闭]
这个问题似乎不是关于特定的编程问题、软件算法或主要由程序员使用的软件工具。如果您认为这个问题在另一个Stack Exchange网站上是主题,您可以留下评论来解释这个问题在哪里可以得到回答。 我们构建了一个定制的Kafka Connect sink,它反过来调用一个远程REST API。我如何将背压传播到Kafka Connect基础设施,以便在远程系统比内部使用者向put()传递消息慢的情况下,
-
AWS EC2将HTTP重定向到HTTPS槽负载均衡器
问题是,我还想将HTTP访问重定向到HTTPS,然后我试图添加一个规则将80重定向到443,因此它将落入第一个规则(443到8080)并使用证书,但它不起作用。在网上研究,我发现我应该在我的。htacess文件中添加一些行,但也不起作用。我认为这不是我的解决方案,因为所有HTTPS的东西都在AWS端,有没有一种方法可以只通过AWS将HTTP重定向到HTTPS而不改变服务器?
-
PyQt在连接信号时将参数发送到插槽
问题内容: 我有一个任务栏菜单,单击该任务栏菜单将其连接到获取触发事件的插槽。现在的问题是,我想知道单击了哪个菜单项,但是我不知道如何将该信息发送到连接的功能。这是用于将操作连接到功能的代码: 我知道有些事件会返回一个值,但是Trigger()不会。那么我该如何实现呢?我必须发出自己的信号吗? 问题答案: 用一个 这是PyQt书中的一个示例: 顺便说一句,您也可以使用,但是我发现该方法更加简单明了
-
Linux 查看内存插槽数、最大容量的方法
本文向大家介绍Linux 查看内存插槽数、最大容量的方法,包括了Linux 查看内存插槽数、最大容量的方法的使用技巧和注意事项,需要的朋友参考一下 查看内存插槽数: dmidecode|grep -P -A5 "Memory\s+Device"|grep Size|grep -v Range 查看最大容量: dmidecode | grep -P 'Maximum\s+Capacity' 以上这篇
-
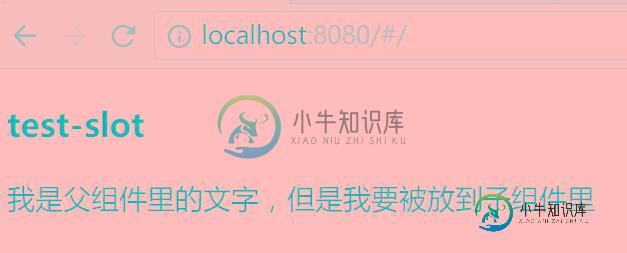 详解vue使用插槽分发内容slot的用法
详解vue使用插槽分发内容slot的用法本文向大家介绍详解vue使用插槽分发内容slot的用法,包括了详解vue使用插槽分发内容slot的用法的使用技巧和注意事项,需要的朋友参考一下 将父组件的内容放到子组件指定的位置叫做内容分发 单个插槽 父组件app.vue 子组件testSlot.vue 效果图: 多个插槽也叫具名插槽 具名插槽就是将某个名字的内容插到子组件对应名字里面去 父组件app.vue 子组件testSlot.vue 作用
-
vue学习笔记之slot插槽用法实例分析
本文向大家介绍vue学习笔记之slot插槽用法实例分析,包括了vue学习笔记之slot插槽用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了vue slot插槽用法。分享给大家供大家参考,具体如下: 不使用插槽,在template中用v-html解析父组件传来的带有标签的content 使用插槽,如果父组件为空,就会显示slot中定义的默认内容 使用插槽添加header和foot
-
为什么分支延迟插槽已弃用或过时?
当我阅读RISC-V用户级ISA手册时,我注意到它说“OpenRISC有条件代码和分支延迟槽,这使更高性能的实现变得复杂。”所以RISC-V没有分支延迟槽RISC-V用户级ISA手动链接。此外,维基百科说,大多数较新的RISC设计都省略了分支延迟槽。为什么大多数较新的RISC架构逐渐省略了分支延迟槽?
-
Apache Flink-是否可以均匀分布插槽共享组?
我们有一个带有操作的管道,分成两个工作负载-在第一组中,是CPU密集型的工作负载,它们被放入同一个插槽共享组,比方说。和,因为它使用大容量上载并在内存中保存大量数据。它被发送到插槽共享组。 此外,工作负载和工作负载的并行度级别不同,因为第一个工作负载受源并行度的限制。例如,我们的并行度为50,同时并行度等于78。我们有8个TMs,每个有16个内核(因此也有插槽)。 在这种情况下,理想的插槽分配策略
-
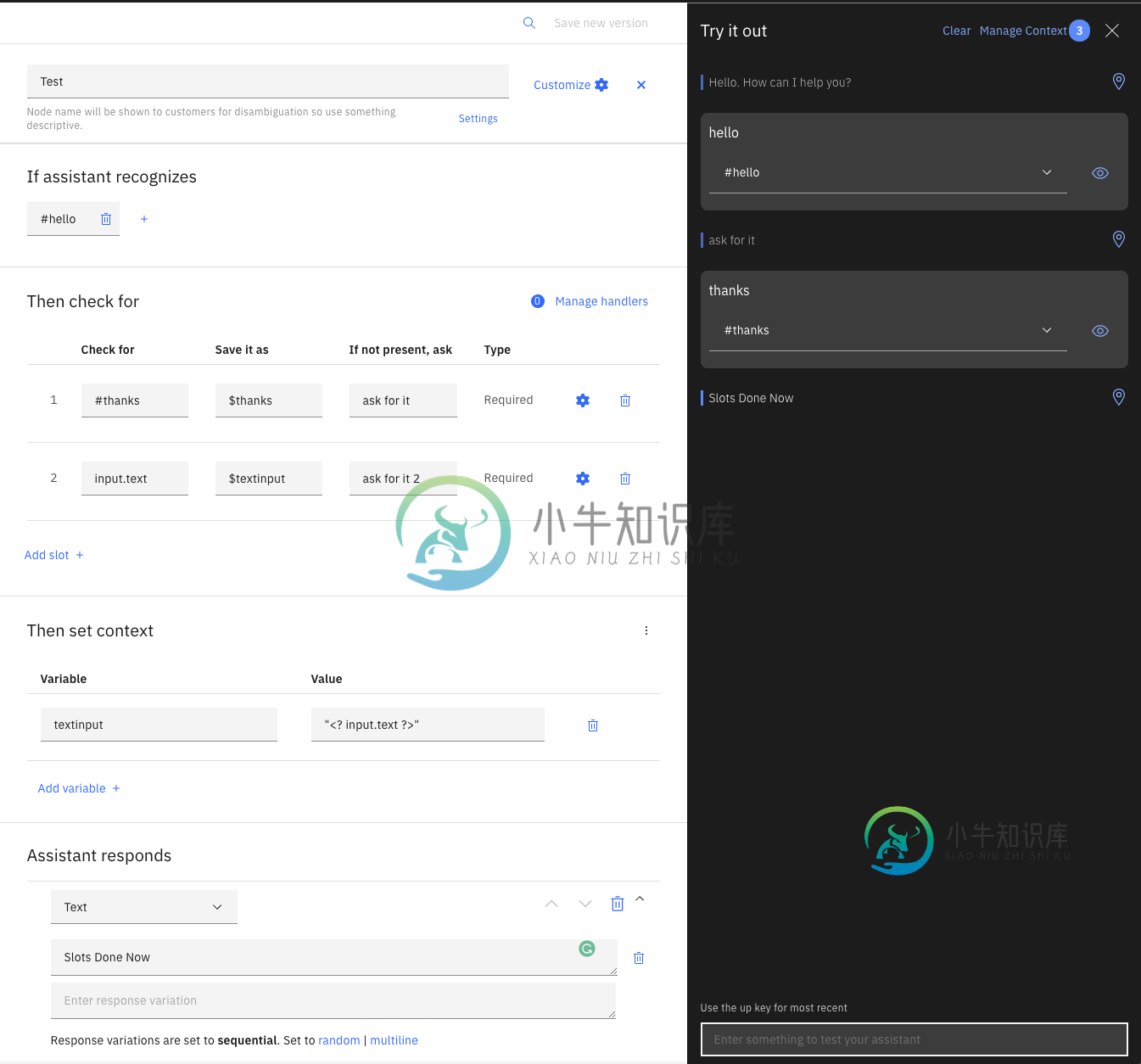 IBM Watson Assistant-如何使用输入。插槽中的文本
IBM Watson Assistant-如何使用输入。插槽中的文本我使用IBM沃森助手聊天机器人。我有一个有两个插槽的对话节点。第一个插槽工作正常。节点被触发,机器人要求第一个插槽,因为它不存在。 然后我想让机器人请求第二个插槽。给出的答案应该存储在$variable中。我试图通过,因为我想存储那里给出的各种输入。 但是机器人没有询问第二个插槽,而是跳过它,并将插槽1中给出的答案存储在插槽2$变量中。我猜这是因为机器人也会检查输入。文本出现在插槽1中。为了明确起
-
在hdfsKafka、水槽中的不同目录中登陆文件
我想将csv文件从一台服务器(Unix服务器A)发送到hdfs目录。根据哪些csv文件,我想将它们放在hdfs中的不同目录中。 我有一个11个csv文件,将由unix服务器A上的kafka制作人发送到kafka。csv文件的第一个元素将包含一个键。我想取第一个元素并使其成为kafka消息的键。此外,我想将数据的值作为kafka中的消息发送。 当它到达kafka集群时,将有一个水槽代理获取数据,并拦
-
使用水槽将本地文件源到 HDFS 接收器
我正在使用flume将本地文件源到HDFS接收器,下面是我的conf: 我使用用户“flume”来执行这个conf文件。 但它显示我找不到本地文件,权限被拒绝 如何解决这个问题?
-
水槽在一行2048个字符后添加换行符
我有一个在 Ubuntu 工作站上运行的 Flume 1.5 代理,它从各种设备收集日志并将日志重新格式化为具有很长行的逗号分隔文件。在收集和重新格式化日志后,它们被放入假脱机目录中,Flume 代理将日志文件发送到运行 Flume 代理的 Hadoop 服务器,以接受日志文件并将它们放在 HDFS 目录中。 除了当Flume将文件发送到HDFS目录时,每行每2048个字符后有换行符之外,一切都正