《吐槽面试》专题
-
Flume HDFS水槽没有从Kafka频道创建HDFS文件
我正在尝试实现一个简单的Flume HDFS接收器,它将从Kafka通道获取事件,并将它们作为文本文件写入HDFS。 建筑非常简单。这些事件从twitter流式传输到kafka主题,flume hdfs sink确实会将这些事件写入hdfs。这是Kafka-制片人斯塔科弗洛问题的第二部分。 当我执行这个命令时没有出现错误,看起来运行得很好,但是我看不到hdfs中的文本文件。我无法调试或调查,因为在
-
反序列化 Json 文件并使用水槽沉入 HDFS
我有一个假脱机目录,所有json文件都在其中,每秒钟都会有传入的文件被添加到这个目录中,我必须反序列化传入的json文件,获取requires字段并将其附加到HDFS目录中。 我所做的是我创建了一个 flume conf 文件,其中将假脱机目录中的文件作为源,并使用 1 个接收器将 json 文件直接放入 HDFS 中。 我必须在Sink之前将这个json转换成结构化格式,并将其放入HDFS。最重
-
Alexa技能-如何在Lambda函数中检索插槽值
我正在开发一个Alexa技能与一个意图,包括一个插槽与几个可能的值。 我的插槽定义为,,以及值 iqram 英格丽德 菲尔 克莱德 如何检索发出的插槽值在我的Lambda函数中使用?我想回答的是“从话语部分检索插槽值”。非常感谢。
-
为storm nimbus获取“拓扑没有可用插槽”错误
我是阿帕奇Storm的新手。我正试图建立一个局部Storm集群。我使用以下链接设置了zookeeper,当我启动zookeeper时,它运行良好。但是当我使用start nimbus命令启动nimbus时,我看到一个错误,在nimbus.log文件中没有可用于拓扑的插槽。 我的nimbus.log文件: null 解决方案: 运行以下命令:
-
javascript - 关于el-table二次封装插槽slot的问题?
先看下面我的el-table二次封装相关代码。 index.vue column.vue 然后在页面中使用: 但是这样使用中间会有很多插槽,而且插槽内还有一些过滤方法,感觉封装还是没有减少代码量,一时不知道该如何解决这种情况,希望大家帮我出出主意。
-
javascript - 如何在Vue中获取插槽内元素的Ref?
想要写一个Popover,计算元素位置使用的是floating-ui,需要获取触发元素的Ref和Popover内容的Ref来进行定位。 触发元素和内容通过插槽传入,遇到的问题是如何获取插槽内元素的Ref Popover 伪代码: 使用: 目前我能想到的办法就是在触发元素和内容外套一层div,然后用div的Ref 但是这样就多了一层节点,在想能不能有更好的解决方案?
-
javascript - 关于element-ui的表格组件,vue插槽问题?
上面是element组件的的基本用法 我想根据上面的用法自己写一个表格组件,也包含table组件和table-column组件两个组件, 请问我怎么在table组件的默认插槽里,把row传给插槽中的el-table-column组件 table组件部分: table-column组件部分:
-
Ivy桥上RDRAND指令的延迟和吞吐量是多少?
我找不到任何关于agner.orgRDRAND指令的延迟或吞吐量的信息。但是,这个处理器存在,所以信息必须在那里。 编辑:实际上,最新的优化手册中提到了此说明。记录如下:
-
Android KitKat在应用进入后台后不会显示吐司
我正在从我的Android测试应用程序运行一个服务,它需要显示在一个服务中不断增加的toast from计数器值。 它的开始很好,展示了祝酒词。但是,一旦我按下Back/Home键使应用程序保持在后台,烤面包片就会停止显示。当我再次将应用程序放到前台时,烤面包片又开始可见了。 这个问题发生在Kitkat。但在果冻和豆子下面,它的工作很好。 那么,如何让toast始终可见,甚至app在后台,服务在运
-
如何将文本发布到文本框而不是吐司?
嘿,有的人,我是Android和Kotlin的新手,你能帮我这个请。 在这里,结果发布到吐司,我希望它在输入框中,如何做到这一点?
-
 python GUI库图形界面开发之PyQt5信号与槽机制、自定义信号基础介绍
python GUI库图形界面开发之PyQt5信号与槽机制、自定义信号基础介绍本文向大家介绍python GUI库图形界面开发之PyQt5信号与槽机制、自定义信号基础介绍,包括了python GUI库图形界面开发之PyQt5信号与槽机制、自定义信号基础介绍的使用技巧和注意事项,需要的朋友参考一下 信号和槽机制是 QT 的核心机制,要精通 QT 编程就必须对信号和槽有所了解。信号和槽是一种高级接口,应用于对象之间的通信,它是 QT 的核心特性,也是 QT 区别于其它工具包的重
-
当我无故向水槽写信时,NIO Pipe会抛出“ Broken Pipe”!如何调试?
问题内容: 我相信我做的一切正确。我创建一个管道,将接收器传递到编写器线程,使用OP_READ在选择器上注册源,启动选择器。一切正常,但是一旦我向接收器写入内容,就会出现管道异常的情况。为什么!!! ??? 这里没有破损的管道。我烦了。我如何调试/了解这里发生了什么?有没有人有一个简单的管道示例,我可以运行它来测试是否正常。写在接收器上的线程,选择器读取它。 编辑: 我几乎遵循了这里的建议。很难在
-
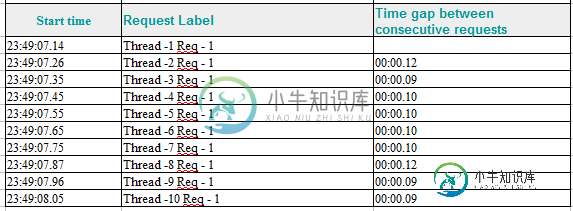 Jmeter中的恒定吞吐量计时器是如何工作的?
Jmeter中的恒定吞吐量计时器是如何工作的?如何计算请求之间的延迟。我有一个简单的Jmeter脚本,包含以下4个组件: > 线程组-线程数设置为10,重置其他字段有缺省值。 Http采样器-名为Thread-${uuuuThreadNum}Req-${uuuuu计数器(TRUE)}点击URL-google。公司 恒定吞吐量计时器:目标吞吐量-60,计算所有活动线程的吞吐量。 在表侦听器中查看结果。 请解释如何计算请求之间的延迟和要创建的请求
-
仅用于一个线程组的吞吐量成形计时器
我有一个JMeter测试计划,其中包含具有不同工作负载和吞吐量的多个线程组。我想使用吞吐量成形计时器,但只对一个线程组应用成形。如果我在线程组中有计时器,它似乎仍然作用于整个测试计划。 例如,如果我将其设置为每秒6个请求,并运行测试10分钟,则在“查看结果”树中会得到3600个条目(这是预期的)。不幸的是,这3600个条目包括来自其他线程组的请求。我希望只从这个线程组中获得3600个条目,然后从其
-
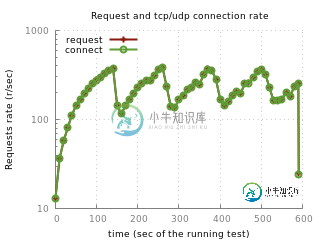 nginx反向代理吞吐量周期性下降,会是什么?
nginx反向代理吞吐量周期性下降,会是什么?这是使用的nginx配置。所有被评论的东西都被尝试过,没有任何影响。我还使用了worker_connections的值和相关的东西。这种周期性下降是由什么引发的?