《吐槽面试》专题
-
如何在jmeter中为多个采样器使用吞吐量控制器?
如果采样器的数量非常高,接近100个,如何在jmeta中使用吞吐量控制器?我希望所有的采样器都以相同的数量通过jmetm发送。 我的测试配置:终极线程组:50个线程,10分钟,斜坡上升10秒,斜坡下降10秒 采样器1, 采样器2, ... 取样器100。 未使用吞吐量控制器。 执行测试时,总请求数如下: Sampler1:150, 样本2:145,, Sampler50:5, Sampler100
-
一文读懂吞吐量(TPS)、QPS、并发数、响应时间(RT)概念
本文向大家介绍一文读懂吞吐量(TPS)、QPS、并发数、响应时间(RT)概念,包括了一文读懂吞吐量(TPS)、QPS、并发数、响应时间(RT)概念的使用技巧和注意事项,需要的朋友参考一下 QPS 原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。 公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS) 。 机器:峰值时间每秒QPS
-
如何在Android中为swipe tab中的每个tab显示吐司消息?
当我运行这段代码时,两个不同片段中的toast显示在一个选项卡上。当我滑动到下一个选项卡时,什么也不显示。 这是我的主要选项卡活动: 这是适配器类: 这是我的第一个片段: 如有任何建议,我们将不胜感激。我被困在这了。
-
使用Jedis如何写入Redis集群中的特定插槽/节点
问题内容: 我正在尝试提高将数据写入Redis集群的性能。我们正计划从redi-sentinel转换为集群模式以实现可伸缩性。 但是,与redis-sentinel相比,写操作的性能要差得多。我们在redis-sentinel中利用了管道,但是集群模式不支持管道。 因此,我正在考虑将所有进入同一节点的密钥归为一组,然后使用管道将批次发送到该特定节点。 因此,我想知道如何(在写入集群之前)将特定密钥
-
运行水槽下载twitter数据时出现未处理java.lang.错误
当我运行这个命令时 水槽正在启动,但过了一段时间,它向我抛出了不允许水槽下载的异常。我收到以下错误: 出现此错误后,它尝试进行检查,但未能下载数据。 我是Hadoop和Flume的新手。
-
如何使用阿帕奇水槽从txt文件中读取日志
我有阅读持续增长的问题。txt文件。我知道我可以从网上读到一些东西,比如说 但是如何用文本文件做呢?我应该传递什么而不是netcat?
-
使用水槽将数据从kafka主题导入到hdfs文件夹
我正在使用水槽从kafka主题HDFS文件夹加载消息。所以, 我创建了一个主题 TT 我通过Kafka控制台制作人向 TT 发送了消息 我配置了水槽代理 FF 运行 flume agent flume-ng agent -n FF -c conf -f flume.conf - Dflume.root.logger=INFO,console 代码执行停止,没有错误,并且不会向 HDFS 写入任何内
-
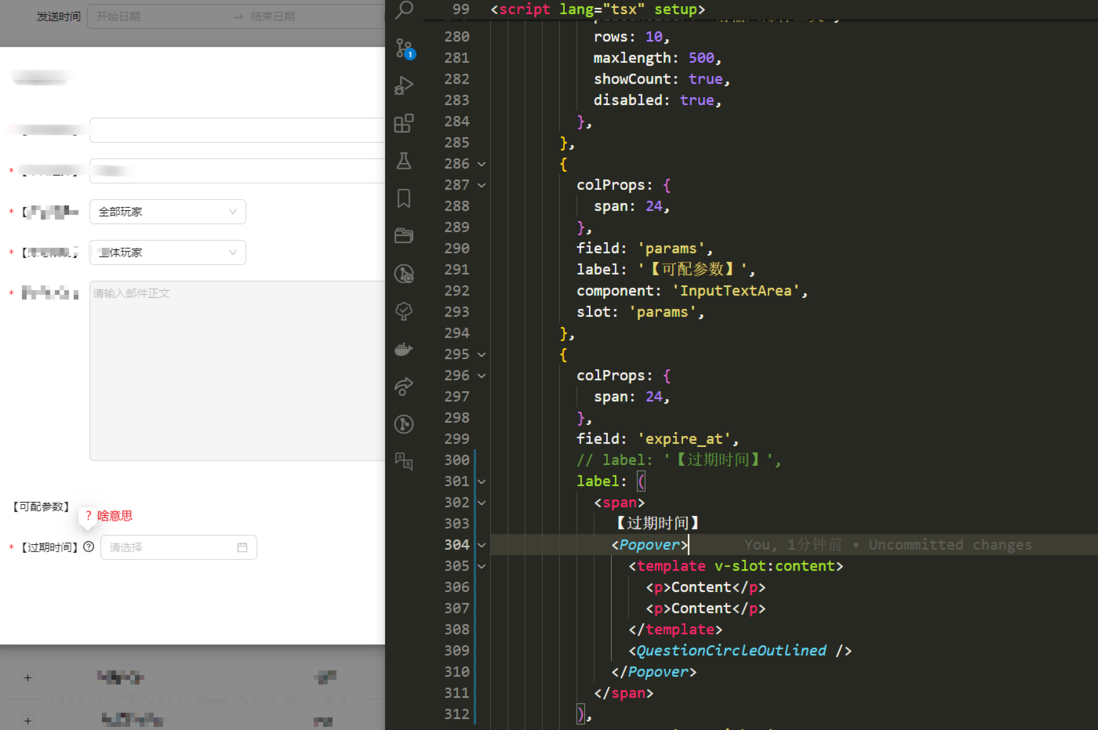 vue3 - ant-designv-vue的Popover组件的具名插槽为何没生效?
vue3 - ant-designv-vue的Popover组件的具名插槽为何没生效?如题,基本的框架是vben。这里面的具名插槽为何没效果, 搞不明白 那个jsx里面是不能写简写#content的,会影响代码高亮和格式。这为啥popover没有按预期的工作?
-
尝试使用jvmti访问异常和线程对象的值时出现无效插槽错误
代理代码如下:
-
Jmeter-吞吐量控制器下“每用户”复选框的功能是什么?
我需要用一些百分比来划分我的应用程序的负载。登录模块-60%,账户-10%,其他模块-30%。经过很少的研究,我发现了一个选项下的吞吐量控制器部分,我可以使用它来控制这些百分比。我在那里找到一个名为“每个用户”的复选框。现在我没有得到这个复选框。 根据blazemeter博客,我尝试了一个场景,如下所示,选中了“每个用户”复选框。 从下拉列表中选择“总执行” 标记吞吐量为40 使用的线程数-10,
-
通过JMeter中的CLI忽略誓言请求吞吐量和响应时间
在进行测试时,我需要从宣誓API中获取令牌,并在另一个成功完成的后续API中使用它。但是,当通过CLI生成HTML报告时,还会计算誓言API的响应时间和吞吐量,有没有一种方法可以忽略该请求?
-
FP和integer division是否在x86 CPU上竞争相同的吞吐量资源?
我们知道,Intel CPU在端口0上的非完全流水线除法执行单元上执行整数除法和FP div/sqrt。我们从IACA输出、其他已发表的资料和实验测试中了解到这一点。(例如。https://agner.org/optimize/) 但是FP和integer是否有独立的分隔符(仅竞争通过端口0的调度),或者如果一个是integer,另一个是FP,交错两个div吞吐量受限的工作负载是否会使其成本几乎呈
-
汇编-如何通过延迟和吞吐量对CPU指令进行评分
我正在寻找一种公式/方法来衡量一条指令的速度,或者更具体地说,按CPU周期给每条指令一个“分数”。 以下面的汇编程序为例, 以及以下Intel Skylake信息: mov r,m:吞吐量=0.5延迟=2 Mov m, r:吞吐量=1延迟=2 nop:吞吐量=0.25延迟=非 inc:吞吐量=0.25延迟=1 我知道程序中的指令顺序在这里很重要,但我希望创建一些不需要“精确到单个周期”的通用指令
-
第0行第0列的IllegalStateExceptionget字段插槽失败,即使moveToFirst()为true
这是一段相关的代码: 我得到以下例外情况: 第81行第0列第0列的IllegalStateExceptionget字段插槽失败。 如果查询没有返回任何结果(即moveToFirst()为什么为true),有人能解释为什么到达第81行吗?或者有没有其他的解释来解释这个例外? 编辑添加:Android留档在Cursor.moveToFirst()(http://developer.android.co
-
 Postgresql|剩余的连接槽保留给非复制超级用户连接
Postgresql|剩余的连接槽保留给非复制超级用户连接我在一个PostgreSQL实例上收到一个错误“剩余的连接插槽保留给非复制超级用户连接”。 然而,当我从超级用户运行下面的查询来检查可用的连接时,我发现有足够的连接可用。但仍然得到同样的错误。 输出 我搜索了这个错误,每个人都建议增加最大连接数,如下面的链接。Heroku“psql:FATAL:剩余的连接插槽保留给非复制超级用户连接” 编辑 我重新启动了服务器,一段时间后使用的连接数接近210,但