《2022毕业即失业取暖地》专题
-
从Spring集成启动Spring批处理作业
我需要从远程SFTP服务器下载一个文件,并使用spring batch处理它们。我已经实现了使用Spring集成下载文件的代码。但我无法从Spring集成组件启动Spring批处理作业。我有以下代码: 但这不起作用(上一个方法中的错误),因为找不到文件类型的bean。我不能把这两部分连在一起。如何连接集成和批处理?
-
Jenkins-在从机中只运行单个作业
我有一个詹金斯服务器50多个工作。我添加了一个新的要求与特定用户执行。因此,我创建了slave节点(具有特定配置的相同主机),并将其限制为slave。但我以前的工作都开始用主+从了。所以他们开始失败了(因为我使用了另一个用户)。 问候。
-
带有扫描器输入Java作业问题
我努力解决问题,我真的很接近,但我很困惑为什么我的程序似乎跳过,没有读取输入学生姓名部分我的输入。当学生数为1时,似乎也有这个问题。任何帮助都将不胜感激!:]
-
带Spring Boot的Google app engine中的Cron作业
还有关于如何在App Engine中创建Cron作业的链接 我正在使用Spring Boot for Google App Engine,那么我如何使用Spring Boot进行Cron作业呢?
-
Apache Flink作业中的多数据流支持
其他流式框架(如Apache Samza、Storm或Nifi)是否可以实现这一点? 我们非常期待得到答复。
-
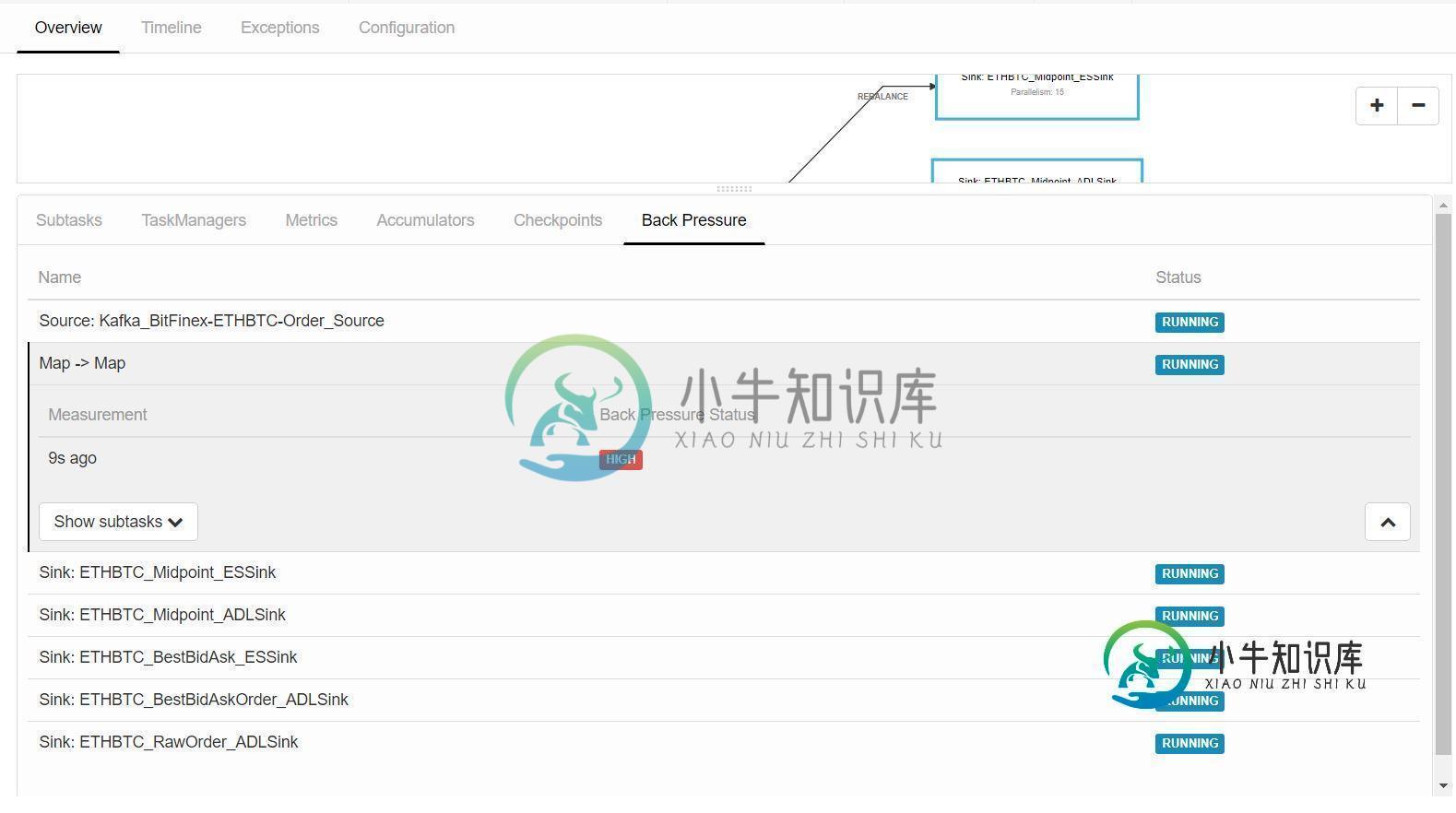 如何处理flink流作业中的背压?
如何处理flink流作业中的背压?我正在运行一个流式flink作业,它消耗来自kafka的流式数据,在flink映射函数中对数据进行一些处理,并将数据写入Azure数据湖和弹性搜索。对于map函数,我使用了1的并行性,因为我需要在作为全局变量维护的数据列表上逐个处理传入的数据。现在,当我运行该作业时,当flink开始从kafka获取流数据时,它的背压在map函数中变得很高。有什么设置或配置我可以做以避免背压在闪烁?
-
 oracle 11g企业数据库SID错误ORA-12505
oracle 11g企业数据库SID错误ORA-12505我已经安装了oracle Enterprice 11g数据库(桌面模式)。当我使用sqlplus作为sysdba连接的sqlplus停止我的数据库并使用shutdown立即启动它时,它没有连接到SID下面是屏幕快照 甚至我在企业管理器上使用了启动按钮 当我尝试使用sqlplus/as SYSDBA连接时,它会说ORA-01031-权限不足
-
部署IBM worklight企业服务器时的BeanCreationException
我们试图通过Tomcat在Ubuntu服务器上部署Worklight Enterprise edition 虽然我们成功地完成了几个步骤,但在启动Tomcat并运行War文件时遇到了一个错误。我们使用MySQL作为数据库。 我们面临的具体错误是“.BeanCreationException:错误创建名为'Deploy Service'的bean。 严重:FWLST0003E:==========启
-
Quartz Scheduler:如何将作业分组在一起?
我想问是否有人有同样的问题与石英调度器。我使用Trigger和JobKeys创建了作业,在这些作业中设置了groupnames。但当我打印出已设置的组时,它总是默认的。 如何设置此groupname以最终能够将作业分组在一起,最重要的是只取消指定的组?使用类似于下面这样的代码: 输出:
-
在Slurm群集上运行批处理作业
所以我现在花了几个小时试图解决这个问题,并希望得到任何帮助。
-
Spark作业长时间运行,数据太少
我在Master上运行了一个如下所示的spark代码: 我的集群配置:独立/客户机模式下的3个节点(1个主+2个从) 我尝试添加一个新的集群,因为上面搜索的关于资源不足的错误,但是这个错误在伸缩时仍然存在。 是因为节点中的内存较少吗??这里有什么建议吗??
-
如何加快cron作业/数据库更新
我有一个cron作业,每小时运行一次,用API的每小时数据更新本地数据库。 数据库按行存储每小时数据,API返回24个数据点,代表过去24小时。 有时数据点会丢失,所以当我拿回数据时,我不能只更新最近一个小时的数据——我还需要检查我以前是否有过这些数据,并填补发现的任何空白。 一切都在运行和工作,但cron作业每次至少需要30分钟才能完成,我想知道是否有任何方法可以使此运行更好/更快/更高效? 我
-
等待数据存储导出作业完成
null 如何调用API来验证作业是否已完成,并获取已保存导出的URL? 谢了。
-
Docker桌面没有运行Windows 11企业版
一旦启动 Docker 桌面 4.4.4 版本 ,Docker 服务停止并出现以下错误
-
 兴业数金数据开发面经(已offer)
兴业数金数据开发面经(已offer)两个面试官 一个负责问java一个负责大数据 自我介绍 1.为什么要使用线程池 2.说一下线程池创建时的核心参数 3.如何查看当前线程池最大线程数 4.说一下jvm内存区域 5.说一下有哪些垃圾回收 算法 6.linux通过什么命令查看日志 7.通过什么命令杀死进程 8.说一下spark shuffle 和mr shuffle区别 9.说一下hive有哪几种存储格式 哪种存储格式压缩率更高 10.