《2022毕业即失业取暖地》专题
-
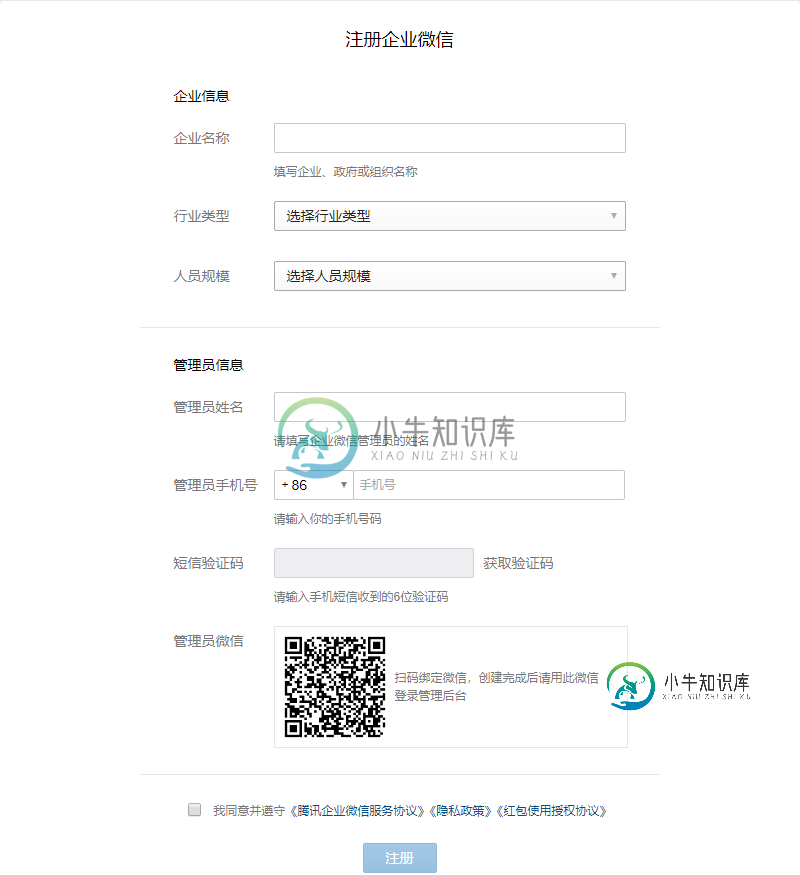 通过shell+python实现企业微信预警
通过shell+python实现企业微信预警本文向大家介绍通过shell+python实现企业微信预警,包括了通过shell+python实现企业微信预警的使用技巧和注意事项,需要的朋友参考一下 一 注册企业微信 本文所有内容是基于2018年12月26日时的企业微信版本所做的教程。后面可能由于企业微信界面规则更改导致部分流程不一致。(大家看文章时请注意这一点) 注册企业微信必备条件 微信号(实名认证了) 手机号 之前我有个误区,就是以为注册
-
无业游民,码头工人,木偶,厨师
问题内容: 我什至不理解标题中服务之间的基本区别。这些服务仅仅是提供软件来帮助您配置/组织/管理VM,还是为VM运行提供物理基础设施?换句话说,它们只是开发人员与AWS,Rackspace和Azure之间的便捷接口吗? 问题答案: 不完全是。 Chef / Puppet是“相同的”,它们是配置管理。尽管您可以使用它们来管理虚拟机或公共/私有云,但是大多数人并不倾向于那样使用它们。它们是配置管理。它
-
如何通过PHP脚本设置cron作业
问题内容: 如何通过PHP脚本设置cron作业。 问题答案: 这将添加一个每天上午9:30运行的脚本。 如果从Web服务器运行此脚本,可能会遇到权限问题。为了解决这个问题,我建议使用另一种方法。 这是一种可能的解决方案。创建需要运行的脚本列表。您可以将其保存在文本文件或数据库中。创建一个脚本来读取此列表,并每分钟或每5分钟(使用cronjob)运行它。您的脚本将需要足够聪明,以决定何时运行脚本列表
-
 python制作企业邮箱的爆破脚本
python制作企业邮箱的爆破脚本本文向大家介绍python制作企业邮箱的爆破脚本,包括了python制作企业邮箱的爆破脚本的使用技巧和注意事项,需要的朋友参考一下 按照师傅给的任务,写了一个企业邮箱的爆破脚本,后续还有FTP,SSH等一些爆破的脚本。 我先说下整体思路: 总体就是利用python的poplib模块来从pop3服务器上交互,根据获取的相关信息,产生结果。POP3协议并不复杂,它也是采用的一问一答式的方式,你向服务器
-
了解mesos上spark作业的资源分配
我在Spark上从事一个项目,最近从使用Spark Standalone切换到使用Mesos进行集群管理。现在,我发现自己对在新系统下提交作业时如何分配资源感到困惑。 在独立模式下,我使用的是这样的东西(以下是Cloudera博客文章中的一些建议: 这是一个集群,其中每台机器有16个内核和大约32 GB RAM。 这样做的好处是,我可以很好地控制运行的执行器的数量以及分配给每个执行器的资源。在上面
-
Java Bean和企业Java Bean之间的区别?
问题内容: 它们是不同的还是可以互换使用?如果它们不同,那么是什么使它们彼此不同? 问题答案: JavaBean只是一个普通的旧Java对象,它遵循某些约定,包括使用访问器函数(getFoo / setFoo)进行成员访问,提供默认构造函数以及类似的一些其他事情。 Enterprise JavaBean是Java EE应用程序服务器中的一个组件,它具有多种风味,具体细节因您所谈论的Java EE版
-
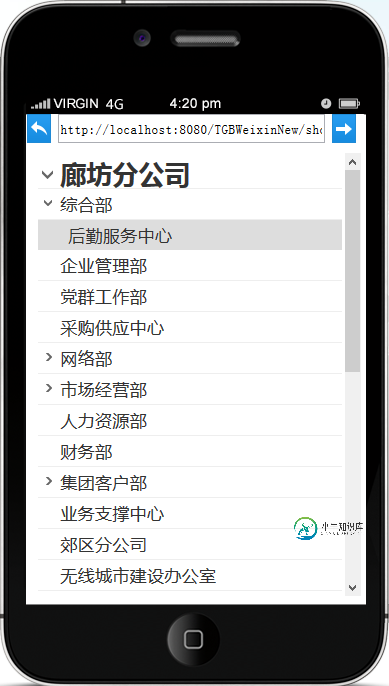 java微信企业号开发之通讯录
java微信企业号开发之通讯录本文向大家介绍java微信企业号开发之通讯录,包括了java微信企业号开发之通讯录的使用技巧和注意事项,需要的朋友参考一下 上篇文章中介绍了聊天功能,这里介绍通讯录是如何实现的。首先要加载公司的所有部门,树形结构,然后点击进入部门的人员列表,点击人员能查看详细信息。 一、界面 公司部门的树形结构: 部门成员列表: 个人详细信息: 二、代码实现 1.controller 2.serviceI
-
通过cron作业的python代码未运行
我正在尝试运行一个python3脚本,每天在特定的时间检查电子邮件的特定条件。 我可以看到crontab调用了这些命令,但脚本没有给出我需要的结果,即似乎没有运行。我可以在syslog中看到cron的执行: 8月3日16:25:01 raspberrypi/USR/SBIN/CRON[4597]:(pi)CMD(cd/home/pi/pythonscripts) 8月3日16:25:01 rasp
-
Kubernetes-在预安装作业上使用机密
在我的helm chart中,我有一个钩子的工作,在这个钩子上我需要使用我的secrets中的一个属性。但是,当我尝试安装舵机图时,我的作业出现以下错误: 错误:未找到机密“SecretsFileName” null 我的机密文件:
-
根据状态停止spring批处理作业
我在我的JAVA应用程序中配置了Spring批处理作业,该应用程序在集群中运行。因此,相同的作业被执行两次,这是我不想要的。 所以我想在作业中配置一个步骤,它将检查CREATE_DATE是否在BATCH_JOB_EXECUTION表中存在,并将继续或故障转移。 如何在spring批处理步骤中进行配置?
-
Spring批处理集成作业-启动-网关
布尔沙赫布尔
-
spring批处理在10秒后停止作业
我正在尝试在后台运行作业,允许我根据某种条件或在超时发生后停止它。 我有这两块代码:
-
kubernetes中的Flink部署无法启动作业
我按照以下指南在kubernetes创建了一个flink集群:https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/native_kubernetes.html 作业管理器正在运行。当作业提交给作业管理器时,它生成了一个任务管理器pod,但任务管理器无法连接到作业管理器。
-
Flink作业群集Kubernetes从保存点恢复
我们目前正在kubernetes上运行flink,作为使用这个helm模板的作业集群:https://github.com/docker-flink/examples/tree/master/helm/flink(带有一些添加的配置)。 如果我想关闭集群,重新部署新映像(由于应用程序代码更新)并重新启动,我将如何从保存点进行恢复? jobManager命令严格设置在standalone-job.s
-
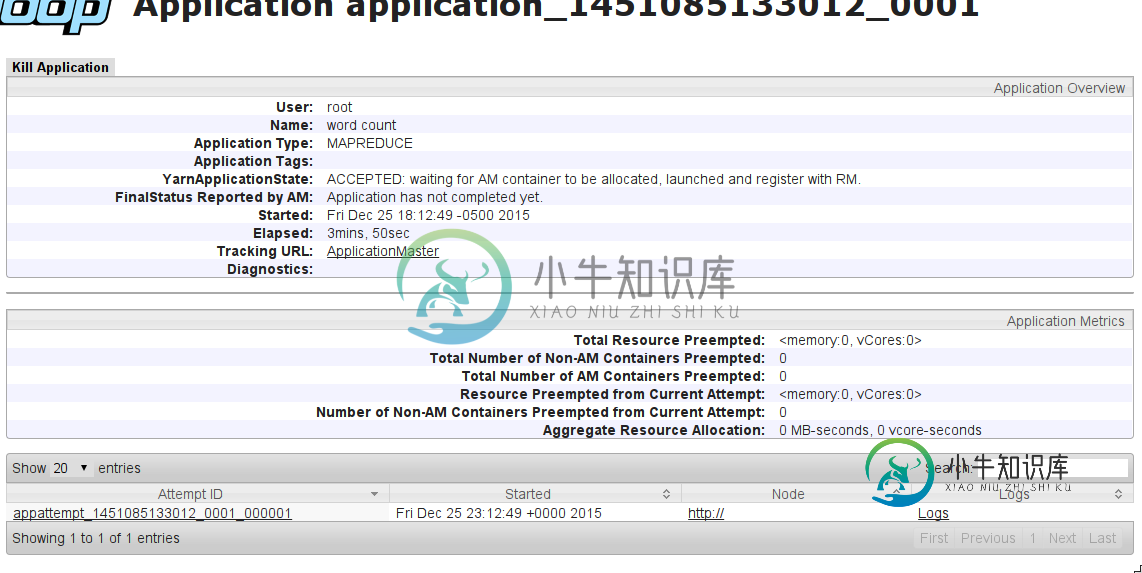 MapReduce作业挂起,等待分配AM容器
MapReduce作业挂起,等待分配AM容器我尝试将简单单词计数作为MapReduce作业运行。在本地运行时,一切工作都很好(所有工作都在Name节点上完成)。但是,当我尝试使用YARN在集群上运行它时(将=添加到mapred-site.conf),作业会挂起。 我在这里遇到了一个类似的问题:MapReduce作业陷入接受状态 作业输出: 会有什么问题? 编辑: 我在机器上尝试了这个配置(评论):NameNode(8GB RAM)+2x D