
MapReduce作业挂起,等待分配AM容器

我尝试将简单单词计数作为MapReduce作业运行。在本地运行时,一切工作都很好(所有工作都在Name节点上完成)。但是,当我尝试使用YARN在集群上运行它时(将mapreduce.framework.name=YARN添加到mapred-site.conf),作业会挂起。
我在这里遇到了一个类似的问题:MapReduce作业陷入接受状态
作业输出:
*** START ***
15/12/25 17:52:50 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
15/12/25 17:52:51 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
15/12/25 17:52:51 INFO input.FileInputFormat: Total input paths to process : 5
15/12/25 17:52:52 INFO mapreduce.JobSubmitter: number of splits:5
15/12/25 17:52:52 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1451083949804_0001
15/12/25 17:52:53 INFO impl.YarnClientImpl: Submitted application application_1451083949804_0001
15/12/25 17:52:53 INFO mapreduce.Job: The url to track the job: http://hadoop-droplet:8088/proxy/application_1451083949804_0001/
15/12/25 17:52:53 INFO mapreduce.Job: Running job: job_1451083949804_0001
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.tracker</name>
<value>localhost:54311</value>
</property>
<!--
<property>
<name>mapreduce.job.tracker.reserved.physicalmemory.mb</name>
<value></value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>3000</value>
<source>mapred-site.xml</source>
</property> -->
</configuration>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3000</value>
<source>yarn-site.xml</source>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>500</value>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>3000</value>
</property>
-->
</configuration>
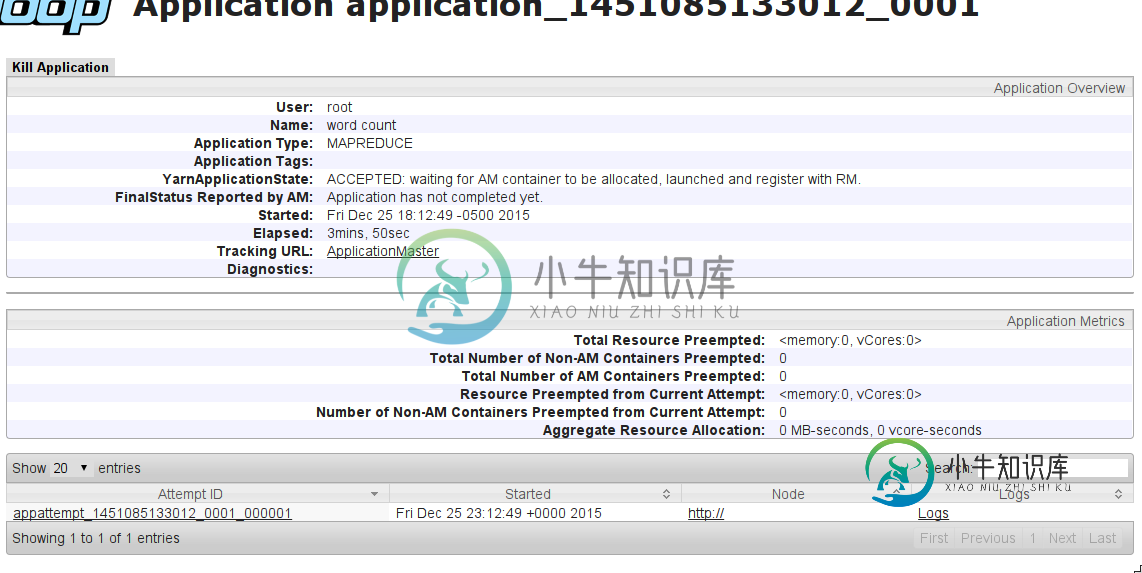
会有什么问题?
编辑:
我在机器上尝试了这个配置(评论):NameNode(8GB RAM)+2x DataNode(4GB RAM)。我得到了同样的效果:作业挂起接受状态。
编辑2:更改配置(谢谢@Manjunath Ballur)为:
yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-droplet</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-droplet:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-droplet:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-droplet:8030</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-droplet:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-droplet:8088</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,
$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,
$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,
$YARN_HOME/*,$YARN_HOME/lib/*
</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/1/yarn/local,/data/2/yarn/local,/data/3/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/1/yarn/logs,/data/2/yarn/logs,/data/3/yarn/logs</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/var/log/hadoop-yarn/apps</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>390</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>390</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>50</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx40m</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>50</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>50</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx40m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx40m</value>
</property>
</configuration>
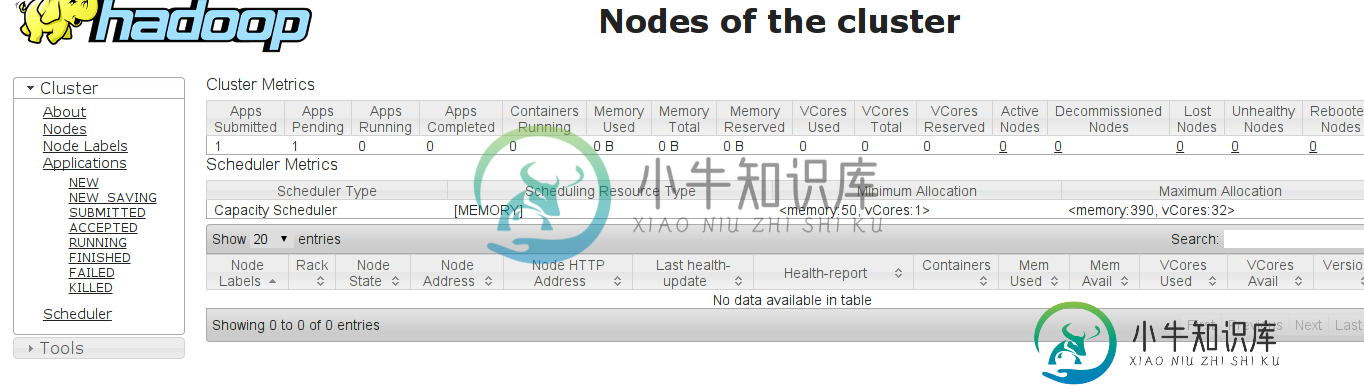
共有1个答案

您应该检查群集中节点管理器的状态。如果NM节点的磁盘空间不足,那么RM会将它们标记为“不健康”,并且这些NM无法分配新的容器。
1)检查不健康的节点:http://
如果“health report”选项卡显示“local-dirs are bad”,则意味着您需要从这些节点中清理一些磁盘空间。
2)检查hdfs-site.xml中的DFSDFS.data.dir属性。它指向本地文件系统中存储hdfs数据的位置。
3)登录到这些机器,并使用df-h&Hadoop fs-du-h命令来测量占用的空间。
4)验证hadoop trash并删除它,如果它阻止了您。hadoop fs-du-h/user/user_name/.trash和hadoop fs-rm-r/user/user_name/.trash/*
-
我是Hadoop的MapReduce的新手。我已经编写了一个map-reduce任务,我正在尝试在本地计算机上运行它。但这项工作在地图绘制完成后就悬而未决了。 下面是代码,我不明白我错过了什么。 我有一个自定义密钥类 使用自定义键的映射器和缩减器类如下。 我还在main中创建了一个作业和配置。不知道我错过了什么。我在本地环境下运行这一切。
-
詹金斯不会执行任何工作。查看了这个问题后,我禁用了所有从属节点,但一个简单的作业甚至不会在主节点上运行。 怎么了?
-
我有以下四个测试,最后一个测试在运行时挂起。为什么会发生这种情况: 我使用这个扩展方法的restSharp RestClient: 为什么最后一个测试挂起?
-
有时,在我用Selenium2.41完成的测试中,在Firefox28测试中,执行挂起等待页面加载。 还要设置以下属性:
-
我试图理解为什么这段代码返回“Promise{pending}”。 当我通过reduceDirections()函数时,我可以看到我得到了想要的结果。但是当我(一行之后)时,我会改为“Promise pending” 很抱歉,我不理解promise和异步等待。我曾尝试在mdn上阅读和观看视频,但我不知道如何将它们显示的内容转移到这个问题上。提前感谢您的帮助!
-
问题内容: 我有在执行过程中挂起的控制台应用程序。这是我的配置: 这是我的堆栈跟踪: 我只打开了一个锥形杯,但似乎没有泄漏。而且我也使用一个线程。除了内存使用率,我没有调整任何mysql设置。Mysql从控制台正常工作。为什么会发生这种情况?这是c3p0错误吗? 问题答案: 立即发生还是在一段时间后发生?也就是说,结帐最初是否成功,但随后却像这样挂起?如果是这样,它看起来像是连接泄漏。请尝试将c3