《数据人的面试交流地》专题
-
 大数据实时实习面试
大数据实时实习面试1.自我介绍 2.你对redis宕机后的方法 我:...... 3.你说到算法。你有刷过letcode算法? 我:很少刷letcode,一般都是刷sql的 3.kafka的副本同步 我:忘了 4.谈谈你对数仓的理解 我:..... 5.谈谈你对hbase和clickhouse的理解 我:.... 6.你说你对hive中的ads层数据导入到MySQL,为什么不是直接从hive的ads层中访问 我:不
-
 5.9荣耀面试数据开发
5.9荣耀面试数据开发一个小姐姐打电话告诉我会议号的。 进去之后,先自我介绍,然后让我讲项目。 hdfs的读写机制 雪花模型星型模型的区别和适用场景 小文件的弊端 又在问项目 20分钟结束了,反问环节都没有。。。
-
5.1.61 61.数据流中的中位数
一、题目 如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有值排序之后位于中间的数值。如果数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。 二、解题思路 如果能够保证数据容器左边的数据都小于右边的数据,这样即使左、右两边内部的数据没有排序,也可以根据左边最大的数及右边最小的数得到中位数。如何快速从一个容器中找出最大数?用最大堆实现这个数据容器,
-
Spring Cloud数据流:版本化流
我正在用Spring Cloud数据流实现一个流管道。 我的问题是,我手动配置了服务器中的管道(例如),如果我重置该服务器,它将丢失(以Amazon EC2实例为例,该实例可以硬重置)。
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
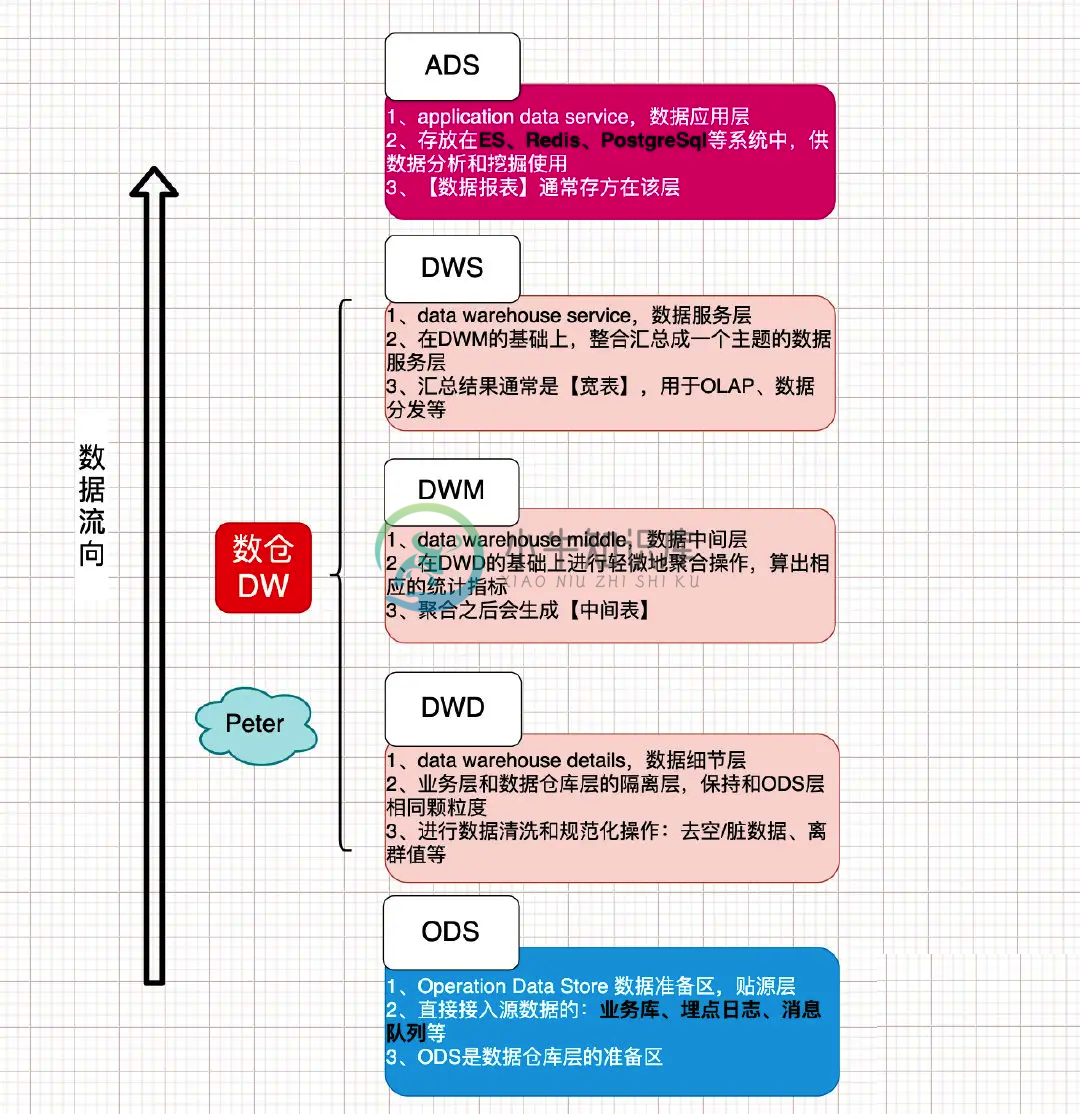 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
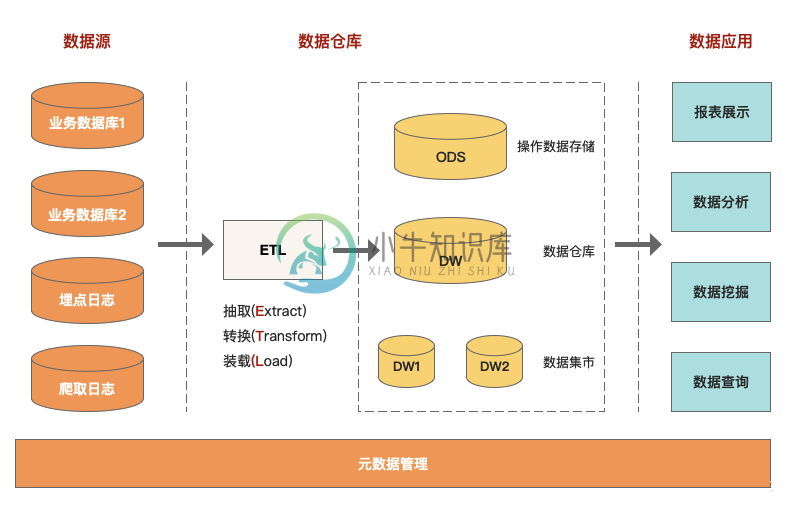 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
vue.js前后端数据交互之提交数据操作详解
本文向大家介绍vue.js前后端数据交互之提交数据操作详解,包括了vue.js前后端数据交互之提交数据操作详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了vue.js前后端数据交互之提交数据操作。分享给大家供大家参考,具体如下: 前端小白刚开始做页面的时候,我们的前端页面中经常会用到表单,所以学会提交表单也是一个基本技能,其实用ajax就能实现,但他的原始语法有点。。。额 。。。复杂,
-
RabbitMQ,话题交流
我的RabbitMQ上有一个主题交换。发送消息时出错。 接收部分: 发送部分: 第行出错:< code > channel . EXCHANGE declare(EXCHANGE _ NAME," topic ");异常:无法使用不同的类型、持久性、内部或自动删除值、class-id=40、method-id=10在vhost“/”中重新声明exchange“EX _ TEST” 如何解决这个问题
-
Spring Cloud数据流将参数传递给数据流服务器
-
 人大金仓 测试一面(30min)
人大金仓 测试一面(30min)1.自我介绍 2.提到了对测试感兴趣,具体对测试的哪个点感兴趣 3.怎么看待加班,如果确实任务比较重怎么办 4.项目负责哪些模块 5.项目开发流程 6.如何保证测试点尽量全覆盖 7.如何测试一个秒杀模块 8.Linux熟悉程度 9.介绍一下OSI七层模型 10.TCP三次握手的过程 11.情景题:一台电脑网线连接都是正常的,就是连不上网,怎么排查 12.python中函数是值传递还是引用传递 13
-
 最右秋招面试-攒人品
最右秋招面试-攒人品1,自我介绍 2,实习项目从不同维度,或者说你的整个参与的一些流程,或者是角色,或者是有什么感悟什么的,给再具体讲讲。 3,有针对现在的这个 系统,它整个的一个系统逻辑有进行过探索,或者是其他就是你了解到的一些不是聚焦在你现在的这个需求场景下的一些系统策略等等。(从产品的角度思考产品发展和策略) 4,系统设计框架,和几个关键路径。(考察对产品的了解,个人感觉产品经理对产品流程上的了解是基础,但是面
-
 23提前批——巨人网络数据分析一面面经
23提前批——巨人网络数据分析一面面经巨人网络数据开发部门(数据分析和数据开发为一个部门) 1. 自我介绍 2. 详细介绍一个参与度较高的经历,并问项目细节 3. 如何搭建的指标体系,用了什么样的逻辑? 4. 介绍AB实验前因后果,最后上线了吗? 5. 机器学习用了什么模型,特征维度多少,最后用了什么评估指标?为什么? 6. 考虑过过拟合的问题吗?如何解决过拟合问题? 7. 简单介绍一下随机森林 8. 用过什么样的数据库? 9. 说一
-
Apache Beam数据流BigQuery
如何使用带有DataflowRunner的apache光束从Google BigQuery数据集获取表列表? 我找不到如何从指定的数据集中获取表。我想使用数据流的并行处理编程模型将表从位于美国的数据集迁移到位于欧盟的数据集。