《数据人的面试交流地》专题
-
如何解决twitter流数据时水槽中的404错误?
我正在尝试使用flume从Twitter API流传输一些数据。代码最初确实有效。但是现在我得到了404错误: 下面是我的conf文件代码。
-
Kafka流如何处理包含不完整数据的分区?
Kafka Streams引擎将一个分区映射到一个工作者(即Java应用程序),以便该分区中的所有消息都由该工作者处理。我有下面的场景,并试图了解它是否仍然可行。 我有一个主题A(有3个分区)。发送到它的消息由Kafka随机分区(即没有密钥)。我发送给它的消息有一个如下的模式 因为我有3个分区,消息在它们之间随机分区,所以相同型号的汽车可以写入不同的分区。举个例子 现在假设我想计算carModel
-
数据流WriteToParket失败,没有明确的消息:“Worflow失败”
我已经看过这些帖子: 谷歌云数据流 - 从Pub到镶木地板 谷歌数据流“工作流程失败”无缘无故 它们很有帮助,我最终为发布/订阅消息创建了类似的东西,比如:<code>{“id”:“1”}</code>(仅用于测试): 我只能看到错误“工作流失败”。但仅对于DataflowRunner,对于DirectRunner,我没有问题。这里是“运行”命令: 以下是此作业的日志(前几行是最后出现的): 现在
-
在Android上使用MediaCodec解码带有H264数据的RTP流
我目前正在尝试从RTP流解析H264数据,然后将其发送到MediaCodec以呈现在Android的SurfaceView上。 但是,我不确定如何: 根据RTP数据包正确构建H264切片 将H264切片组装成切片后发送到媒体编解码器
-
优化内存密集型数据流管道的GCP成本
我们希望提高在GCP数据流中运行特定Apache Beam管道(Python SDK)的成本。 我们已经构建了一个内存密集型Apache Beam管道,这需要在每个执行器上运行大约8.5 GB的内存。一个大型机器学习模型目前加载在转换方法中,因此我们可以为数百万用户预先计算建议。 现有的GCP计算引擎机器类型的内存/vCPU比率低于我们的要求(每个vCPU高达8GB RAM)或更高的比例(每个vC
-
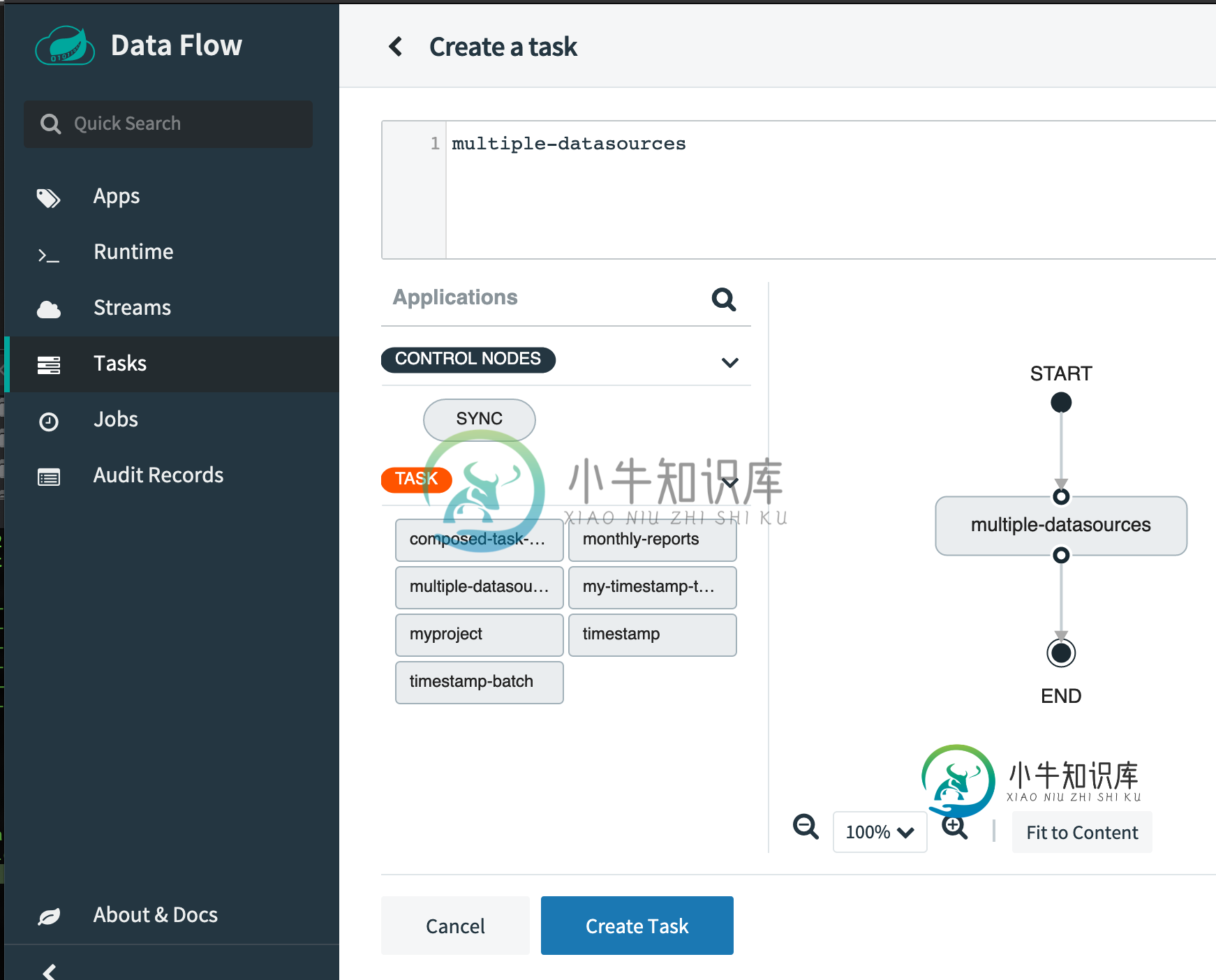 如何正确编译/打包Spring云数据流的任务
如何正确编译/打包Spring云数据流的任务鉴于我需要使用多个数据源,我在IntelliJ Idea 2020.1.3中根据Spring云任务示例编译了以下示例:https://github.com/mminella/spring-cloud-task/tree/master/spring-cloud-task-samples/multiple-datasources 然后,我使用将其打包在一个JAR中,将其复制到启动docker comp
-
Kafka流错误:SerializationException:LongDeserializer接收到的数据大小不是8
我正在尝试Kafka Streams。编写一个简单的应用程序,我在其中计算重复的消息。 消息: 等。 我正在尝试通过。用它作为钥匙。然后将其用作值。然后按键分组,查看在每个会话中复制了哪些消息。 这是代码: KTable 主题 常规生产者生成重复。但是,当我使用控制台使用者查看它时,它会崩溃并显示错误。然后,我在控制台使用者上使用 --跳过错误消息标志。现在我看到成千上万的这样的线条 谁能帮帮我这
-
有没有好的方法从Java8流中提取数据块?
我是一个ETL过程,我正在从Spring数据存储库中检索大量实体。然后使用并行流将实体映射到不同的实体。我可以使用一个使用者将这些新实体逐个存储在另一个存储库中,或者将它们收集到一个列表中,并将其存储在单个批量操作中。第一种方法代价很高,而后者可能会超出可用的内存。
-
我正在尝试将docker笔记本电脑上运行的本地人工制品连接到ELB后面AWS上的远程人工制品
我已经在ELB后面的AWS实例上设置了艺术工厂OSS版本6.9.1,并且已经从GitLab CI/CD成功地将构建部署到它。我现在正试图在我的笔记本电脑上设置一个本地艺术工厂OSS版本6.10.0,这样我就可以在与团队共享之前在本地开发构建。 我的本地工件完全连接到JCentre,我可以浏览该存储库。 我的gradle构建将很高兴地连接到位于http://{URL}/artifactory的AWS
-
绑定到页面的数据上下文
我发现需要绑定到的,设置如下: 在设计时。但是,我需要从具有不同数据上下文的子控件绑定到它: 由于 是为 设置的,因此我的 的数据设置为收款人集合中的各个对象。我的视图有一个属性,我需要从转换器中的引用该属性来确定项目的可见性。 我可以根据对象的属性设置可见性,如下所示: 但是我真正需要绑定到的是的的属性。有没有办法从子控件中获取该上下文?我使用的是WinRT,所以我没有绑定源的好处。 编辑 正如
-
面向AWS RDS数据库的Heroku应用
我需要将我的Heroku应用程序指向我的AWS RDS数据库。我的RDS数据库已经启动并运行,并且拥有一个具有0.0.0.0/0访问权限的安全组。 db实例:mydb dbname:mydb user:wcronyn pass:password 我试过了: heroku配置:set database_url=postgres://wcronyn:password@mydb.xxxxxx.us-ea
-
 2023秋招—数据开发面经—美的
2023秋招—数据开发面经—美的线下群面: 五分钟读题,然后每人简单自我介绍+说出对题目的答案,然后讨论20分钟,最后5分钟派一个人总结。 题目:(2选1) 1、如何构建数据中台? 2、设计一个智能家居,应该有哪些功能?用什么技术实现这些功能? 测评: 性格测试+图形推理+资料分析 二面: 1、自我介绍 2、详细介绍一下项目 3、实习的数据框架和项目的数据框架有什么区别吗? 4、数据采集还了解其他工具或架构吗? 5、数据加工处理
-
 数据开发 - 面经 - 来未来(医疗大数据)
数据开发 - 面经 - 来未来(医疗大数据)2024.1.9 面试 Boss直聘沟通 公司要求驻场开发,接受加班,接受出差 你是25届是吧?能在六个月左右是吗?目前在校吗? 后续有什么规划? 你怎么理解数据开发这个岗位的? 讲讲简历上这两个项目?是你在学校做的是吧? 项目你是全程参与是吧? 聊天这个项目的数据源是哪里来的呀? 项目整体是落在HDFS上是吧? 单一架构,嗷,然后可视化,是哇? 下一个电商项目介绍一下? 数据来源讲讲? 那意思是
-
测试表单提交时,redux表单的酶测试失败
我有一个使用redux表单的注册React组件,我的onSubmit基本上发送一个异步操作。我正在尝试使用Ezyme和Jest测试我的组件,方法是向我的分派添加一个间谍,并检查是否在模拟表单提交时调用分派。然而,我的测试失败了。 这是我的注册redux表单组件: 这是我的测试: 我的测试失败,出现以下错误:expect(jest.fn())。ToHaveBeenCall()预期已调用模拟函数。 请
-
d3.js - 基于d3的数据可视化库有交互好用的吗?
目前想要的效果是根据数据绘制散点图,鼠标框选得到选中的数据 纯d3的案例: https://observablehq.com/@d3/brushable-scatterplot-matrix 但d3太复杂了,看了几个库: vega-lite,Observable Plot,没找到交互方面的介绍,有推荐吗? 谢谢