《数据人的面试交流地》专题
-
 记录人生第一次面试:腾讯游戏引擎实习面经,已OC
记录人生第一次面试:腾讯游戏引擎实习面经,已OC📅 oc时间线 12.05 初试 12.12 复试 12.19HR面 12.21 offer ⏳ 获得面试的机会 通过参加腾讯客户端开发公开课,得到实习面试的机会,12.02投递的游戏客户端开发的简历,12.04就有光子的面试官给我电话说考虑游戏引擎吗?(内心os:什么我还能去搞引擎?)赶紧回答考虑的😂然后就约了第二天下午的面试。 📝 实习无笔试 👥 一面 1h 个人介绍 1.自我介绍,硕
-
房间在线人数
6. 房间在线人数 6.1. 功能 获取直播房间在线观看人数 6.2. 地址 http://api.bokecs.com/liveService/{domain}/{appname}/{streamname}/{page}/{rows}/{time}/{sign}/members 请求方式:GET 6.3. 请求参数 domain 客户加速域名,必填 appname App名称,如果查询所有可用大
-
二进制搜索-有人能清除这个面试算法吗?
我最近接受了一次采访,采访者给了我以下场景,并问我将使用什么数据结构来实现它: 你有100个大理石,每个大理石是红色、蓝色或绿色。这些大理石被扔进一个袋子里,你需要有一些机制来取回一个随机的彩色大理石(带有替换品)。 好吧,很简单。在问了一些关于约束的问题后,我告诉他我会使用一个简单的数组,其中每个桶代表一个大理石。随机数函数可以用来索引数组,从而产生一个随机的彩色大理石。 这个解决方案很好,但他
-
配置Step - 面向块的流程
Spring Batch最通用的实现方式是使用“面向块”的处理风格。面向块处理是指在一个事务范围内,一次性读取数据,创建被输出的“块”。ItemReader读取一条项目,通过ItemProcessor处理,并整合。当处理完所有项目后,整个块将由ItemWriter输出,然后提交该事务。 下面一段代码展示上面提示的内容: List items = new Arraylist(); for(int i
-
交叉验证和测试性能的差异
-
如何验证被测试类中的交互?
斯波克规格 如何测试从“Specification下的方法(teamservices.deleteteam())”调用的“Specification下的类”teamservices.moveAssets())方法? https://github.com/spockframework/spock/discussions/1346
-
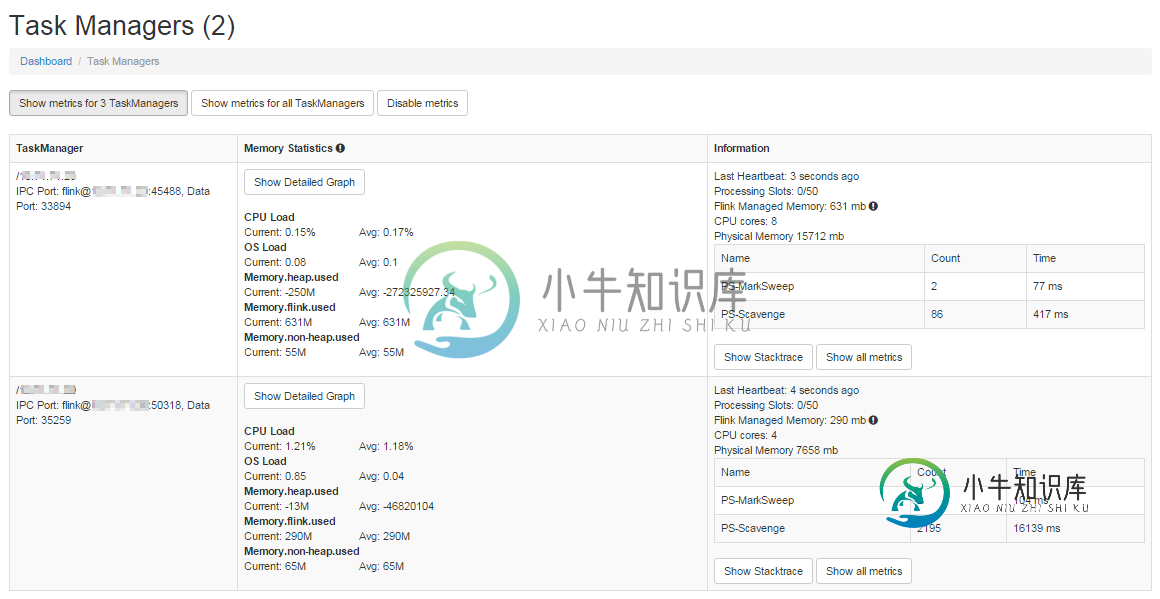 集群中的Apache Flink流不会与工人拆分作业
集群中的Apache Flink流不会与工人拆分作业我的目标是使用Kafka作为源设置一个高吞吐量集群 我在主服务器和辅助服务器上设置了一个2节点集群,配置如下。 flink-conf.yaml大师 Worker flink-conf.yaml 主节点上的文件如下所示: 两个节点上的 flink 设置位于具有相同名称的文件夹中。我通过运行 这将启动Worker节点上的任务管理器。 我的输入源是Kafka。以下是片段。 这是我的水槽功能 这是我的po
-
 令人敬畏的字体无法在流星反应解码
令人敬畏的字体无法在流星反应解码在流星 React 中实现 的过程中,我能够获取日期时间对象。但是不知何故,字体大小未正确加载,因此 datetime 对象现在如下所示: 控制台给我以下警告: 无法解码下载的字体:http://localhost:3000/fonts/rw-widgets.ttf?v=4.1.0 OTS分析错误:无效的版本标记 当前实施 我在main.js中导入了所需的css文件: 在我的应用程序中,我导入了日
-
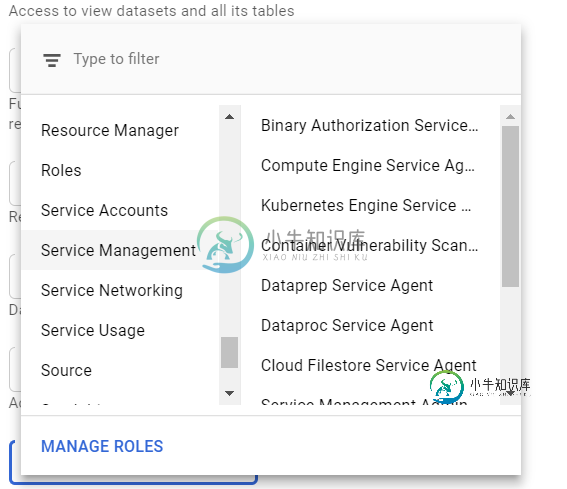 Dataprep不起作用-云数据流服务代理
Dataprep不起作用-云数据流服务代理我在删除服务帐户中的用户时出错,我应该删除另一个用户。之后,Dataprep停止运行作业。 我已经检查了关于dataflow和DataPrep的所有准则:如果API是启用的(是的,它是启用的)。如果有一个适当的服务帐户(是)。但我不知道给这些账户分配什么规则。 我尝试为该帐户分配“云数据流服务代理”角色,但它不适合我 附:我的英语正在进步,有些错误很抱歉。
-
在Python数据流/ Apache Beam上启动CloudSQL代理
问题内容: 我目前正在从事ETL Dataflow作业(使用Apache Beam Python SDK),该作业从CloudSQL查询数据(带有和自定义)并将其写入BigQuery。我的目标是创建一个数据流模板,该模板可以使用Cron作业从AppEngine开始。 我有一个使用DirectRunner在本地工作的版本。为此,我使用CloudSQL(Postgres)代理客户端,以便可以连接到12
-
在物流模型中上载时间数据集
我想上传一个类似的时间数据集 所以现在我正在Anylogic中构建一个物流模型。我设定了三个目的地:城市1、2和3。我想安排三种类型的卡车(卡车A、B和C)将货物运到这些城市。不同的卡车到达不同的城市需要不同的装卸时间,如上表所示。 所以,问题是我正在使用流程建模库,使用“延迟”块来设置定制的等待时间。但是,我如何根据卡车类型及其目的地准确设置时间?我是否应该使用“功能”或“状态图”来达到这个目标
-
如何转换两个不可观测数据流
我有两个可观察的
-
Google云数据流-Apache Beam-管道关闭挂钩
想知道是否有某种“钩子”来放置apache beam管道关闭时将执行的一段代码(无论出于何种原因-崩溃、取消) 每次数据流停止时,我都需要删除pubsub主题的订阅。
-
数据源用完时如何停止火花流
我有一个spark流媒体作业,它每5秒钟读取一次Kafka,对传入的数据进行一些转换,然后写入文件系统。 这实际上不需要是一个流式作业,实际上,我只想每天运行一次,将消息排入文件系统。但我不知道如何停止这项工作。 如果我向streamingContext传递超时。等待终止,它不会停止进程,它所做的只是导致进程在流上迭代时产生错误(请参见下面的错误) 实现我所要做的事情的最佳方式是什么 这是Pyth
-
 AVPlayer HLS实时流电平计(显示FFT数据)
AVPlayer HLS实时流电平计(显示FFT数据)我正在使用作为使用HTTP实时流的无线电应用程序。现在我想为该音频流实现一个电平表。最好是一个显示不同频率的电平表,但是一个简单的左/右解决方案将是一个很好的起点。 我发现了几个使用AVAudioPlayer的示例。但是我无法找到从AVPlayer获取所需信息的解决方案。 有人能想出解决我问题的办法吗? 编辑我想创建这样的东西(但更好) 编辑二 一个建议是使用MTAudioProcessingTa