《数据人的面试交流地》专题
-
 ui设计面试必问‼️根据真实大厂面试改编‼️
ui设计面试必问‼️根据真实大厂面试改编‼️1、如何看待流行趋势 我觉得设计趋势是设计师必须要时刻关注的,比如最近的VR技术、3D的设计手法以及多彩的设计语言,但是我们设计师不能盲目的去追求所谓的流行趋势,我们需要根据我们产品自己内在的属性,去打造差异化的设计方案 2. 如何看待加班 觉得项目上的需要,设计师是一定需要去积极的加班配合,与此同时我也需要去提高自己的工作效率,尽量做到少加班 3. 你的缺点是什么 我的缺点就是我的收回能力有些不
-
 交互面试|反问环节难道就可以摆烂了?
交互面试|反问环节难道就可以摆烂了?答题技巧 每个面试的结尾面试官都会说“你有什么要问我的问题“,千万不要放弃这个唯一掌握主动权好的机会。 如果你觉得自己胜券在握,抓住这个机会深挖你所要加入的团队。记住不光是公司在选你,你也在选公司,所以面试前准备好你想要了解的公司信息。 如果你觉得自己没有机会也不要放弃,这个环节你可以被用作“了解你想应聘的公司/岗位对于设计师有什么要求”,总结经验准备下一次面试。 如果你对自己的表现没有准确的判断
-
 设计求职|网易交互设计面试经验分享
设计求职|网易交互设计面试经验分享具体来说,游戏交互的设计实习可能对于爱打游戏的人来说非常友好,对于我这样的几乎不玩游戏的人,可能理解不会那么深刻。但是我也过了面试,说明面试的时候,面试官更加看重的是你这个人以及你的专业素养和可培养性。 总共就是两面,一面为专业面试,二面为HR面。 一面: 有两位面试官,电话面试,大概45分钟。 网易游戏的一面是我经历过的七八次面试之中最让我慌了神的top1。并没有讲作品集,也没有问你作品集的问题
-
 腾讯交互设计暑期实习面试经验分享
腾讯交互设计暑期实习面试经验分享【背景】本科,0实习经验,23年毕业 【岗位】光子工作室交互设计暑期实习 【笔试】 一周时间,一共两题,一题偏交互设计产出,一题偏分析优化。第一题是设计游戏中的某个系统,第二题是分析现有游戏的问题,提出优化方案。 【面试】 只有一次远程专业面试,时长大概在40min。问题大致如下: 1. 自我介绍 2. 之前是技术背景,为什么转交互 3. 玩过什么游戏(手机、主机、pc) 4. 在校期间做的一个项
-
列数据到Spark结构化流中的嵌套json对象
问题内容: 在我们的应用程序中,我们使用Spark sql获取字段值作为列。我正在尝试弄清楚如何将列值放入嵌套的json对象并推送到Elasticsearch。还有一种方法可以参数化值以传递给正则表达式? 我们目前正在使用Spark Java API。 实际输出: 我们需要在节点“ txn_summary”下的上述列,例如以下json: 预期产量: 问题答案: 将所有列添加到顶层结构应提供预期的输
-
如何处理需要子组件状态的流星数据?
问题内容: 将Meteor 1.3中的某些代码切换为ES6 + React语法。组件需要获取流星数据,因此我正在使用createComponent替换getMeteorData()。问题是,旧的getMeteorData使用了组件中的状态,createContainer组件未访问该状态。 旧代码: 到目前为止的新规范 由于尝试访问状态,因此出现错误“无法获取undefined的currentMon
-
如何将CSV转换为Apache Beam数据流中的字典
问题内容: 我想读取一个csv文件,并使用apache beam数据流将其写入BigQuery。为此,我需要以字典的形式将数据呈现给BigQuery。我该如何使用apache beam转换数据来做到这一点? 我的输入csv文件有两列,我想在BigQuery中创建随后的两列表。我知道如何在BigQuery中创建数据,这很简单,我不知道如何将csv转换为字典。下面的代码是不正确的,但应该给出我要做什么
-
C#通过流写入一行数据到文件的方法
本文向大家介绍C#通过流写入一行数据到文件的方法,包括了C#通过流写入一行数据到文件的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#通过流写入一行数据到文件的方法。分享给大家供大家参考。具体如下: 希望本文所述对大家的C#程序设计有所帮助。
-
用于非连续数据的Flink和Kinesis流应用程序
我们已经构建了一个Flink应用程序来处理来自动觉流的数据。应用程序的执行流程包含基于注册类型过滤数据、基于事件时间戳分配水印的基本操作,以及应用于5分钟数据窗口的映射、处理和聚合功能,如下所示: 我的水印分配程序的参考代码: 现在,这个应用程序的性能很好(在几秒钟内的延迟方面),早就有了。然而,最近在上游系统post中发生了变化,其中Kinesis流中的数据以突发方式发布到流中(每天仅2-3小时
-
Apache flink中数据流/运算符与线程的相关性
问题: 在运行时,引擎会为每个数据流创建一个线程吗?还是每个操作员一个线程? 是否可以在作业启动时在运行时动态创建数据流?(即,如果作业启动时从文件中读取N,并且需要创建相应的N个流) 当创建大量流(N~10000个)时,与在单个流中创建N个分区相比,是否有任何特定的性能影响?
-
如何在Flink Java API中获取keyBy()后的数据流键
我如何获得我之前指定的密钥?我没有在累加器中注入输入事件的键,因为我觉得我不会很好。
-
使用Apache Beam的数据流sdk写入BigTable时捕获NullPointerException
我正在使用sdk version并尝试使用运行器将数据拉至bigtable。不幸的是,当我使用作为我的接收器时,我在执行我的数据流管道时得到了。已经检查了我的并且参数很好,根据我的需要。 基本上,我创建并在我的管道的某个点上完成了编写 ,但我甚至无法设置断点来调试正好是null的地方。对于如何解决这个问题,有什么建议吗? 谢谢。
-
Flink 1.14中的全局排序,带有表和数据流API
我一直在关注Flink 1.14中针对有界数据的不同全局数据排序选项。我发现Stackoverflow和其他网站上关于这个的很多问题都是好几年前的问题了,关于不推荐使用的API或者没有完全回答这个问题。由于Flink正在快速发展,我想问一下最新稳定的Flink (1.14)中的可用选项。 以下是我如何理解当前的情况(这可能是错误的)。我的问题也附上。Flink 有两个 API —— 和 , 它们可
-
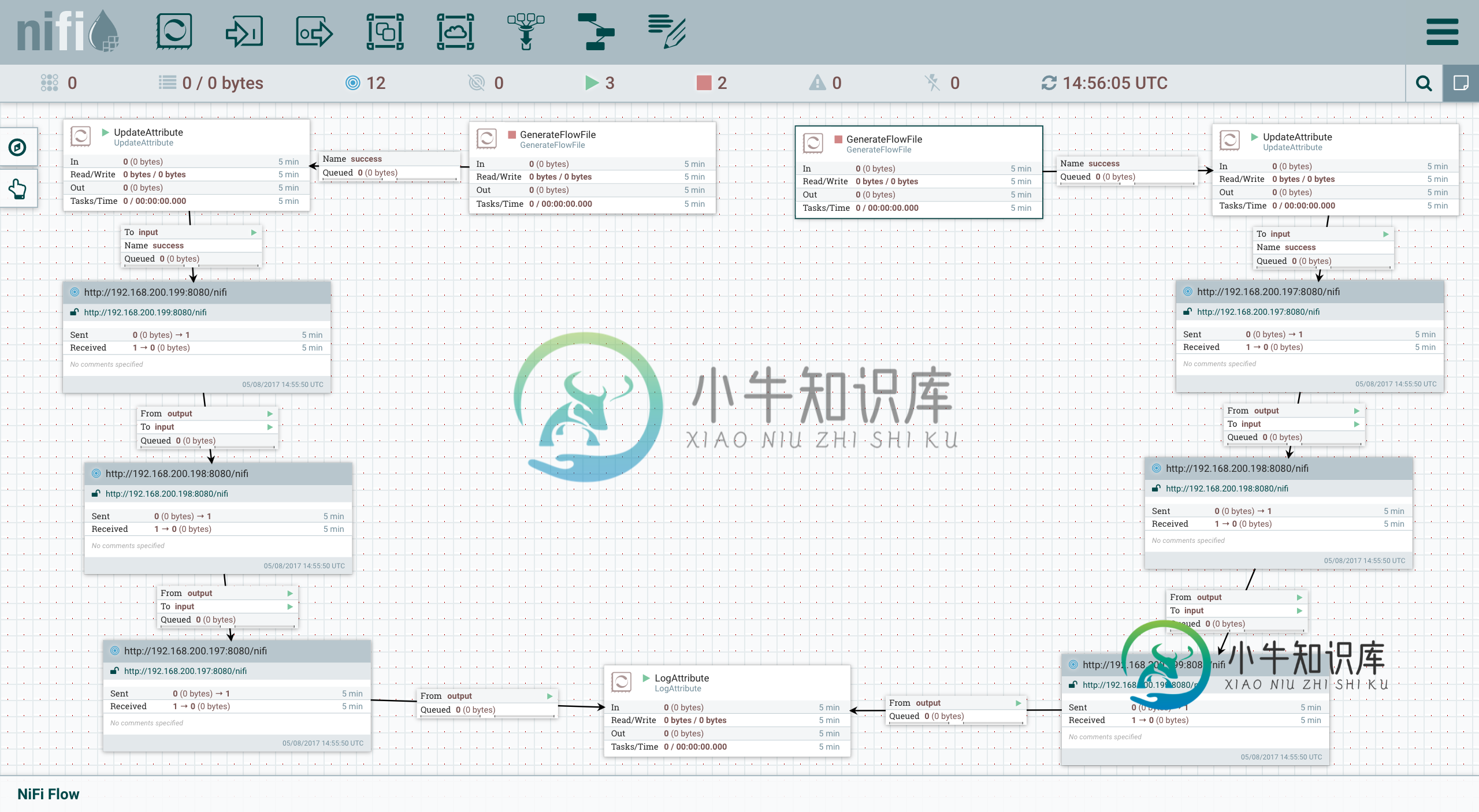 Apache NiFi通过远程进程组的不规则数据流
Apache NiFi通过远程进程组的不规则数据流我正在评估Apache NiFi在一个项目中的使用。我有四个运行在Ubuntu14系统上的云中的NifiV1.1.2实例。其中三个实例用作远程进程组(、和),其余实例()用于管理RPG之间的流。生成一个流文件,将该流文件通过由三个RPG组成的管道,并在最后记录该流文件。每个RPG只需将附加到FlowFile中的ProcessedBy属性,这样就可以很容易地看到数据的处理顺序。 我有的问题是订单不是
-
架构帮助-ETL数据流和处理的替代方案
null 云存储->云函数(触发器)->云数据流->大查询->数据工作室 我还可以使用哪些其他替代架构来实现这一点?云pub/sub是批处理的一种选择吗?使用Apache Kafka进行管道处理怎么样?