《数据人的面试交流地》专题
-
 交行一面凉经
交行一面凉经应该是java软开 投递的研发中心 8月份面的 面试前有ai面 一分钟自我介绍 java类加载的方式 除了new哪些创建对象方式 linux系统变量配置 mysql锁级别 #23届秋招笔面经#
-
设计交互界面
扩展的交互界面应该是有目的且最简单的。 就像扩展本身一样,界面 UI 应该是自定义或能增强浏览体验,而不会分散用户注意力。 本指南探讨了必需的和可选的用户界面功能,了解如何以及何时在扩展中实现不同的 UI 元素。 在所有页面上激活扩展 当扩展程序的功能在大多数情况下都可以使用时,请使用 browser_action 。 注册 browser_action browser_action 在 mani
-
 交通银行一面
交通银行一面交行一面,营运岗 无领导+结构化 一、无领导 材料:年轻人的朋克养生行为,一边熬夜一边和所谓的养生饮料 题目1:阐述朋克养生的利与弊,各说3点 题目2:年轻人该怎么平衡养生与工作的关系 阅读题目3分钟+每人1分钟回答+15分钟小组讨论+推选一个人3分钟汇报 (我们小组在讨论最后推选了一个人汇报,但是面试官说从另外两个他指定的人里选一个汇报) 二、结构化 每人一题,问到的问题有: 为什么选择交通银行
-
 交行软开面经
交行软开面经🕒 岗位/面试时间 11.24 首先问我想留在哪里,还问我问什么来交,交去年赚了多少钱??为什么学前端 👥 面试题目 前端 20min 1.手撕反转字符串 2.Ajax预检请求 3.vue通讯方法 4.浏览器请求静态资源有无上限 5.项目性能优化怎么做的 6.nginx的作用 7.post get区别 反问 流程两到三周 #交通银行#
-
Spring Cloud数据流:自定义应用程序流和预构建应用程序流之间的通信
问题: 我完成了tuto:https://docs.spring.io/spring-cloud-dataflow/docs/current/reference/htmlsingle/#_custom_processor_application 然后注册了一个名为transformer(处理器类型)的自定义应用程序。 picture 创建一个流,并使用自定义应用程序部署它。 -问题1:自定义应用程
-
 Azure DevOps的客户端凭据流
Azure DevOps的客户端凭据流我已经考虑这个问题好几天了,从经验中我知道我通常会解决这些问题,但这次我遇到了砖墙。 我有一个在Azure DevOps YAML管道中实例化的python应用程序。该应用程序调用Azure DevOps REST API来创建存储库 该应用程序使用PAT(个人访问令牌)进行身份验证 我在Azure DevOps中创建了一个应用程序: 我的计划是让这一切都在Postman中工作,然后将我的发现移植
-
Spring Cloud数据流错误通道不工作
我正在尝试为我的SpringCloudDataflow流创建一个自定义异常处理程序,以路由一些要重新排队的错误和其他要DLQ的错误。 为此,我使用了全局Spring集成“errorChannel”和基于异常类型的路由。 这是Spring集成错误路由器的代码: 错误路由器由每个流应用程序通过Spring Boot应用程序上的包扫描获取: 当它与本地 Spring Cloud Dataflow 服务器
-
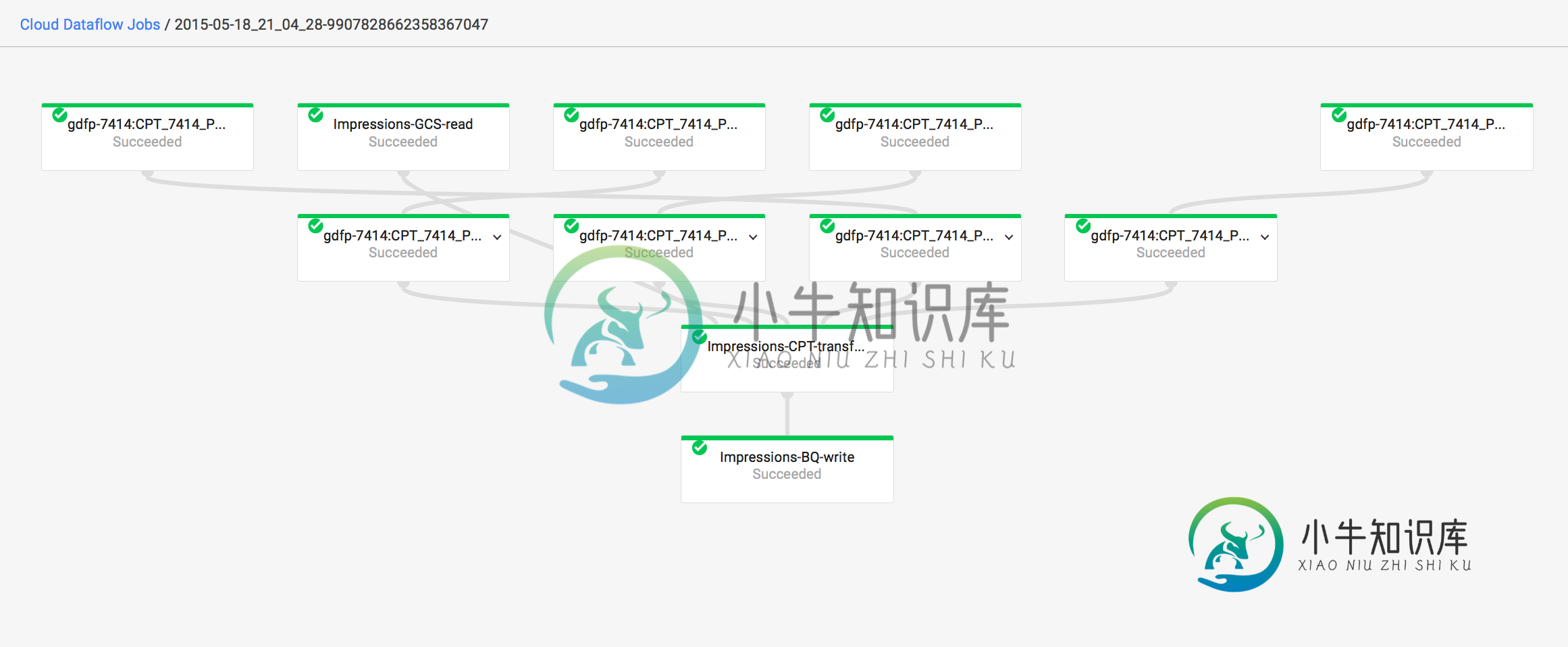 数据流错误-“源太大。限制为5.00ti”
数据流错误-“源太大。限制为5.00ti”BigQuery->ParDo->BigQuery 该表有~2B行,不到1TB。 运行了8个多小时后,作业失败,出现以下错误: 作业id为:2015-05-18_21_04_28-9907828662358367047 此外,即使作业失败,它仍然在图表上显示为成功。为什么?
-
CAST vs ssis数据流隐式转换差异
问题内容: 我有一个SSIS包,可以将一些数据从Oracle传输到SQL Server。 在Oracle中,日期以浮点数存储,例如-用Delphi编写使用数据库的应用程序。 而 在Management Studio导致,相同的值(42824)插入由封装成在SQL Server表显示日期时间列。 注意:此数字的源数据类型为,在数据转换组件中将类型更改为不会更改任何内容 谁能解释一下? 问题答案: 存
-
无法从google云数据流连接Oracle server
我正在尝试从运行在“CST”时区的Oracle server读取数据。我的google数据流正在“us-central1”地区运行。我使用的是Apache Beam-2.3.0 JDBCIO。read()从Oracle server读取数据的方法。我能够使用“DirectRunner”从服务器连接和读取数据,但使用ojdbc8驱动程序jar在“DataflowRunner”中出现以下错误 注意:在
-
_.使用RXJS可观测数据实现节流
我是Rxjs可观测对象的新手,我需要使用Rxjs实现节流。 在下划线中,我们使用下面的行来实现这一点- 请协助如何使用可观察到的数据。
-
Google数据流:导入自定义Python模块
我尝试在Google Cloud数据流中运行Apache Beam管道(Python),由Google Cloud Coomposer中的DAG触发。 我的dags文件夹在各自的GCS桶中的结构如下: setup.py是非常基本的,但是根据Apache Beam文档和SO上的答案: 在DAG文件(dataflow.py)中,我设置了选项并将其传递给Dataflow: 在管道文件(pipeline.
-
如何构建GCP/Apache Beam数据流模板?
好吧,我肯定是遗漏了什么。我需要什么来作为模板准备管道?当我试图通过这些说明将模板暂存时,它会运行模块,但不会暂存任何内容。,它看起来像预期的那样工作,没有出现错误,但是我没有看到任何文件实际添加到bucket位置,在我的--template_位置中侦听。我的python代码应该出现在那里吗?我想是这样吧?我已经确保安装了所有的beam和google cloud SDK,但也许我遗漏了什么?要准备
-
Apache Beam on Cloud数据流-无法查询Cadvisor
我有一个云数据流,它从发布/订阅中读取数据并将数据推送到BQ。最近,数据流正在报告下面的错误,并且没有向BQ写入任何数据。 有什么想法吗,我能帮上什么忙吗?以前有没有人遇到过类似的问题?
-
使用docker解决google云数据流依赖
我对使用谷歌云数据流并行处理视频感兴趣。我的工作同时使用OpenCV和tensorflow。是否可以只在docker实例中运行worker,而不按照以下说明从源安装所有依赖项: https://cloud.google.com/dataflow/pipelines/dependencies-python 我本以为docker容器会有一个标志,它已经位于google容器引擎中。