
数据流错误-“源太大。限制为5.00ti”

BigQuery->ParDo->BigQuery
该表有~2B行,不到1TB。
运行了8个多小时后,作业失败,出现以下错误:
May 19, 2015, 10:09:15 PM
S09: (f5a951d84007ef89): Workflow failed. Causes: (f5a951d84007e064): BigQuery job "dataflow_job_17701769799585490748" in project "gdfp-xxxx" finished with error(s): job error: Sources are too large. Limit is 5.00Ti., error: Sources are too large. Limit is 5.00Ti.
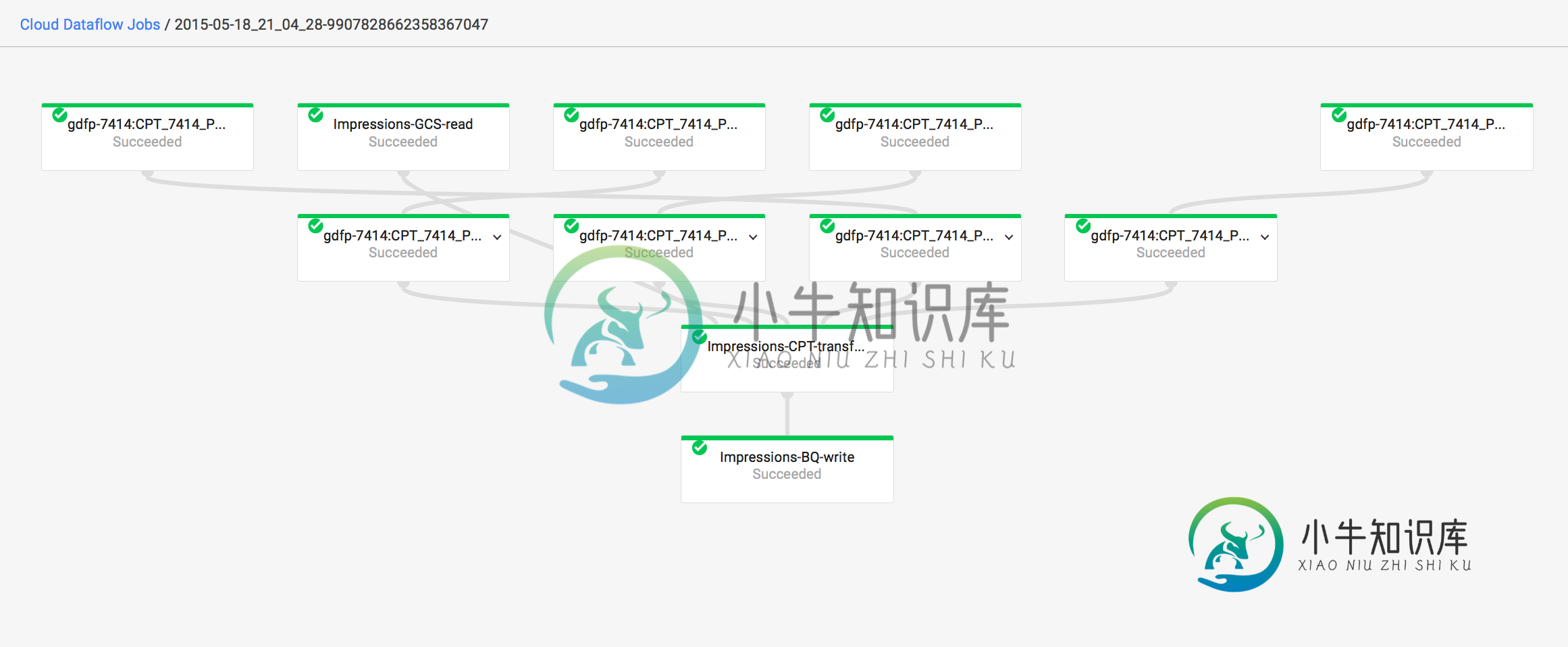
作业id为:2015-05-18_21_04_28-9907828662358367047
此外,即使作业失败,它仍然在图表上显示为成功。为什么?
共有1个答案

我认为该错误意味着您试图写入BigQuery的数据超过了BigQuery为单个导入作业设置的5TB限制。
绕过这个限制的一种方法可能是通过使用多个写转换将BigQuery写操作拆分为多个作业,这样写转换的接收量就不会超过5TB。
在写转换之前,可以有一个具有N个输出的DoFn。对于每条记录,将其随机分配给其中一个输出。然后,N个输出中的每一个都可以有自己的BigQuery.Write转换。写转换可以将所有数据追加到同一个表中,以便所有数据最终都在同一个表中。
-
Sphinx/Coreseek索引的源数据有一些限制,其中最重要的一条是: 所有文档的ID必须是唯一的无符号非零整数(根据Sphinx构造时的选项,可能是32位或64位) 如果不满足这个要求,各种糟糕的情况都可能发生。例如,Sphinx/Coreseek建立索引时可能在突然崩溃,或者由于冲突的文档ID而在索引结果中产生奇怪的结果。也可能,一只重达1000磅的大猩猩最后跳出你的电脑,向你扔臭蛋。我告
-
问题内容: 在HighChart中,我需要针对x和y轴绘制一系列数据。HighChart希望数据为json格式。即[[x,y],[x,y]……[x,y]]。其中x和y是时间(1392345000-Unix纪元格式)和值(49.322)。因此,我正在进行ajax调用以获取数据,并成功将json返回的数据渲染为highchart。在大多数情况下,即,如果data([x,y])的计数低于87500行,则
-
问题内容: 我打开kibana并进行搜索,但出现碎片失败的错误。我查看了elasticsearch.log文件,然后看到此错误: 有什么办法可以增加593.9mb的限制? 问题答案: 您可以尝试在配置文件中将fielddata断路器的限制提高到75%(默认值为60%),然后重新启动集群: 或者,如果您不想重启群集,则可以使用以下方法动态更改设置: 试试看。
-
我正在使用在我的客户端应用程序中执行以及 最大数据包大小限制也存在于中,即?但是我可以使用中的发送大于最大数据包大小的数据块 这是怎么运作的?这是因为是基于流的,负责在较低层创建数据包吗?有什么方法可以增加UDP中的最大数据包大小吗? 当我在客户端读取时,我从服务器端发送的UDP数据包的一些字节是否可能丢失?如果是,那么有没有办法只检测UDP客户端的损失?
-
从我的应用程序注册表单中,我试图将复选框值插入到mysql表中,但它抛出错误1406 Data对于列来说太长了。复选框的值为 0 或 1。而我的表结构是,创建表测试(checkbox_response位(1))... 我经历了一些事情,找到了解决这个问题的方法。解决方案是,我刚刚更改了sql模式SET@@global。sql_mode=“”…正确插入后。 虽然“我的数据类型大小”适合复选框值,但为
-
我在运行我的spring boot项目时遇到了一个问题: 我使用Vaadin来实现UI,使用Maven来实现Dependecies。该数据库是一个MySQL数据库,我严格按照(https://spring.io/guides/gs/accessing-data-mysql/)的说明进行了操作。 说明: 行动: 考虑重新考虑上面的条件,或者在配置中定义一个类型为'javax.sql.DataSour