《兴盛优选》专题
-
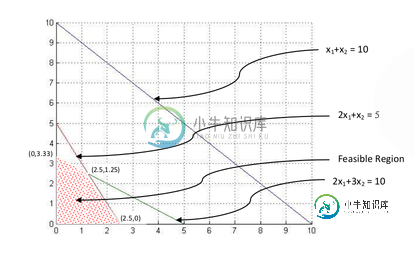 优化:种植小麦和水稻
优化:种植小麦和水稻这是问题陈述 一位印度农民有一片农田,比如说1平方公里长,他想种小麦或水稻,或者两者兼有。农民有有限的F公斤肥料和P公斤杀虫剂。 每平方公里的小麦需要F1公斤化肥和P1公斤杀虫剂。每平方公里的水稻种植需要F2公斤化肥和P2公斤杀虫剂。假设S1是出售从一平方公里收获的小麦获得的价格,S2是出售从一平方公里收获的水稻获得的价格。 你必须通过选择种植小麦和/或水稻的地区来找到农民可以获得的最大总利润。
-
是否允许此浮点优化?
我试图检查在哪里失去了准确表示大整数的能力。所以我写了这个小片段: 这段代码似乎适用于所有编译器,除了clang。Clang生成一个简单的无限循环。戈德博尔特。 这是允许的吗?如果是,这是QoI问题吗?
-
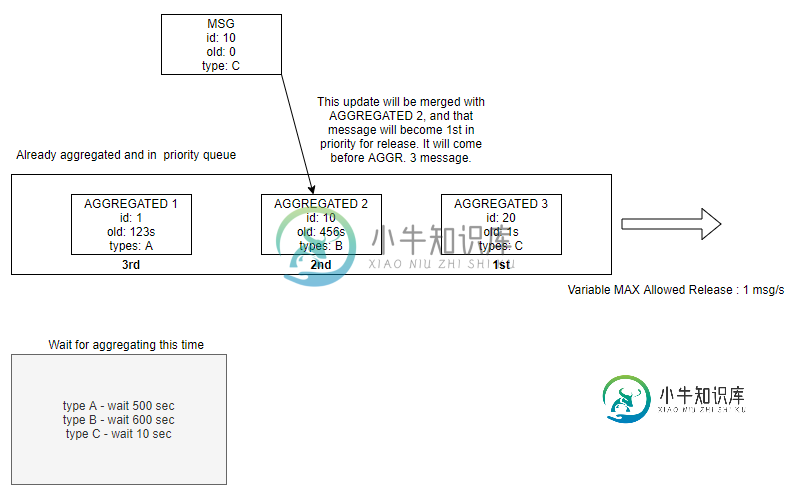 Spring集成-优先级聚合器
Spring集成-优先级聚合器我有以下应用程序要求: 从RabbitMq接收消息,然后根据一些更复杂的规则进行聚合,例如基于属性(具有预先给定的类型时间映射)和基于消息在队列中等待的现有时间(属性) 正如您在图中看到的一个用例:三条消息已经聚合并等待下一秒发布(因为当前速率为),但就在那时,以到达,并更新了,使其成为优先级最高的第一条消息。因此,在下一个选项中,我们不再发布聚合3,而是发布聚合2,因为它现在具有更高的优先级。
-
Java优先级队列比较器
假设我实现了一个HashMap,其中字符被分配了一个值的ArrayList。 我已经在HashMap中创建了这些字符的PriorityQueue,但我希望能够根据此优先级删除这些字符: {a,b,c} {a,b}删除c,因为它的ArrayList中包含一个值,该值决定必须首先删除它。 对此最好的方法是什么?
-
哪个优先:logback.xml还是logback-test.xml?
我是一个很新的登录。如果我的Spring启动项目包含这两个文件- :位于*src/main/resources/下 :位于*src/test/resources/下 哪一个装货?还是?
-
氢汽车加油模型优化
我目前正在尝试确定使用GEKKO的氢气(H2)车辆加油过程的最佳流入条件。下面是耦合的常微分方程,用于控制H2和燃油箱壁的温度如何随加油时间变化。 哪里 这里,是储罐中H2的初始质量,是H2进入储罐的质量流量,是H2的比热比,是H2的流入温度,其他变量是中间变量/储罐参数。通过加油过程,被认为是恒定的(但未知),因此储罐中H2随时间的质量定义为: 此外,罐内H2的压力可以用真实的气体状态方程来计算
-
Dijkstra算法的优先级队列
我正在为Dikjstra算法做一个优先级队列。我目前在插入方法上有麻烦。我包含了整个类的代码,以防你需要更好地了解我想完成的事情。我将堆索引放在一个数组列表(heapIndex)中,堆放在另一个数组列表中。 那是我运行程序后的输出(值,优先级,堆索引)。*(-1)表示heapIndex中的空单元格。
-
可以跳过Stream.peek()进行优化
我在声纳中发现了一条规则,它说: 与其他中间流操作的一个关键区别是,为了优化目的,流实现可以跳过对< code>peek()的调用。这可能会导致< code>peek()仅针对流中的某些元素或不针对流中的任何元素被意外调用。 另外,Javadoc中提到了它,它说: 此方法主要用于支持调试,您希望在元素流经管道中的某个点时看到这些元素 这种情况下可以跳过吗?和调试有关吗?
-
Git 与 TFS 的优势 [已关闭]
< b >想改进这个问题?通过编辑此帖子更新问题,使其只关注一个问题。 我注意到一个流行词“我们应该将Git用于TFS”。我的理解是,Git 只是 DVCS。 TFS 支持从分支、标记、合并、签入、签出、上架等所有内容。 有人可以帮助我了解团队应该在什么情况下使用Git或TFS吗? 除了本地存储库和分布式之外,它还能为团队提供什么好处? 它对分支和合并有更好的支持吗?据我所知,开发人员可以在他/她
-
广度优先搜索:有向图
我正在尝试在有向图上实现BFS。我完全确定我的算法是正确的,但是,下面的代码段返回错误: 图表。CPP文件: 以及在以下方面的实际BFS实施: 因此,除了源节点之外,队列中的其他节点都给出了错误的邻接列表。虽然队列顺序运行良好,但队列中的节点给出了错误的邻接。 我不确定为什么会发生这种情况,虽然我怀疑这是由于按值复制节点而不是引用。 这是我在很长一段时间后的CPP计划,所以如果我错过了什么,请启发
-
非递归深度优先搜索:
在这篇文章中,biziclop为非递归深度优先搜索算法插入了伪代码。 如果我们想使用递归DFS算法来检查节点的适当性,我们可以利用两个变体:pre-order(当一个节点在其子节点之前检查时)和post-order(当子节点在节点之前检查时),加上仅针对二叉树的第三个变体(顺序:左子树,然后节点,然后右子树)。 如果可能的话,我对这三个变体都很感兴趣,所以我试图修改biziclop的伪代码,以便获
-
Python是否优化尾部递归?
我有以下代码失败,错误如下: RuntimeError:超出最大递归深度 我试图重写它以允许尾部递归优化(TCO)。我相信,如果发生了TCO,那么这段代码应该是成功的。 我应该得出结论,Python不做任何类型的TCO,还是我只需要以不同的方式定义它?
-
如何在javascript中优化代码
我认为代码(如下)已经优化(只需使用比相同逻辑的初始版本更少的变量) > 在优化过程中,我应该考虑哪些因素? 这是代码(也在jsfiddle上) 这是代码的解释。“处理”函数在数组中查找相同的值,对于每个相同的值,它通过将一个数字挂起到该值来更改值,“数字”表示它在数组中找到的值的计数。 例如arr=["x","x","y","z"]将返回["x(1)","x(2)","y","z"]"y"和"z
-
Java中的高优先级线程
我目前正在研究分布式应用程序的性能。我的目标是网络组件。目前,每个连接都有一个专用线程,在阻塞模式下处理套接字。我的目标是减少线程数量(不降低性能),如果可能的话,提高性能。 我重新设计了网络组件以使用异步通信,并尝试使用1到2个线程来处理整个网络。我做了一个简单的测试,我从一个节点在一个循环中写入,然后在另一个节点上读取,这是为了测试最大nw线程能力,我发现我的繁忙循环实现消耗了100%的cpu
-
使用AI技术优化参数
我知道我的问题很笼统,但我对人工智能领域还不熟悉。我用一些参数做了一个实验(几乎6个参数)。每一个都是独立的,我想找到输出函数最大或最小的最优解。然而,如果我想用传统的编程技术来实现,这将需要很多时间,因为我将使用六个嵌套循环。 我只是想知道用哪种人工智能技术来解决这个问题?遗传算法?神经网络?机器学习? 实际上,这个问题可能有不止一个评估函数。它将有一个功能,我们应该最小化它(成本)和另一个功能