《兴盛优选》专题
-
哪个优先级更高:|| 或&&或==
问题内容: 我有这个表达: 这些元素的(,,)有优先权? 您能用方括号显示操作顺序吗? 问题答案: 首先,然后,然后。 您的表情将被评估为。 https://docs.oracle.com/javase/tutorial/java/nutsandbolts/operators.html
-
如何做 MySQL 的性能优化?
本文向大家介绍如何做 MySQL 的性能优化?相关面试题,主要包含被问及如何做 MySQL 的性能优化?时的应答技巧和注意事项,需要的朋友参考一下 为搜索字段创建索引。 避免使用 select *,列出需要查询的字段。 垂直分割分表。 选择正确的存储引擎。
-
如何优化ListView(偶尔会问)
本文向大家介绍如何优化ListView(偶尔会问)相关面试题,主要包含被问及如何优化ListView(偶尔会问)时的应答技巧和注意事项,需要的朋友参考一下 ①Item布局,层级越少越好,使用hierarchyview工具查看优化。 ②复用convertView ③使用ViewHolder ④item中有图片时,异步加载 ⑤快速滑动时,不加载图片 ⑥item中有图片时,应对图片进行适当压缩 ⑦实现数
-
使用 Spring Cloud 有什么优势?
本文向大家介绍使用 Spring Cloud 有什么优势?相关面试题,主要包含被问及使用 Spring Cloud 有什么优势?时的应答技巧和注意事项,需要的朋友参考一下 使用 Spring Boot 开发分布式微服务时,我们面临以下问题 与分布式系统相关的复杂性-这种开销包括网络问题,延迟开销,带宽问题,安全问题。 服务发现-服务发现工具管理群集中的流程和服务如何查找和互相交谈。它涉及一个服务目
-
YAML 配置的优势在哪里 ?
本文向大家介绍YAML 配置的优势在哪里 ?相关面试题,主要包含被问及YAML 配置的优势在哪里 ?时的应答技巧和注意事项,需要的朋友参考一下 YAML 现在可以算是非常流行的一种配置文件格式了,无论是前端还是后端,都可以见到 YAML 配置。那么 YAML 配置和传统的 properties 配置相比到底有哪些优势呢? 配置有序,在一些特殊的场景下,配置有序很关键 支持数组,数组中的元素可以是基
-
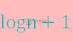 快速排序的最优情况?
快速排序的最优情况?本文向大家介绍快速排序的最优情况?相关面试题,主要包含被问及快速排序的最优情况?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 快速排序的最优情况是Partition每次划分的都很均匀,当排序的元素为n个,则递归树的深度为。在第一次做Partition的时候需对所有元素扫描一遍,获得的枢纽元将所有元素一分为二,不断的划分下去直到排序结束,而在此情况下快速排序的最优时间复杂度为。
-
说一下 JVM 调优的工具?
本文向大家介绍说一下 JVM 调优的工具?相关面试题,主要包含被问及说一下 JVM 调优的工具?时的应答技巧和注意事项,需要的朋友参考一下 JDK 自带了很多监控工具,都位于 JDK 的 bin 目录下,其中最常用的是 jconsole 和 jvisualvm 这两款视图监控工具。 jconsole:用于对 JVM 中的内存、线程和类等进行监控; jvisualvm:JDK 自带的全能分析工具,可
-
Java中的运算符优先级
问题内容: 在来自http://leepoint.net/notes- java/data/expressions/precedence.html的 一个示例中 以下表达式 被评估为 然后我从http://www.roseindia.net/java/master-java/operator- precedence.shtml 看到了另一个示例 以下表达式 被评估为 我对如何确定在涉及*和/时将首
-
优化使用between子句的SQL
问题内容: 考虑以下两个表: 表A中的每条记录都精确映射到表B中的1条记录。这意味着表B没有重叠的时间段。表A中的许多记录可以映射到表B中的同一记录。 我需要一个返回所有A.id,B.id对的查询。就像是: 我正在使用MySQL,但无法优化此查询。表A中有约980条记录,表B中有130.000条记录,这是永远的事。我知道必须执行980个查询,但是在功能强大的计算机上花费超过15分钟的时间却很奇怪。
-
优化休眠序列ID生成
问题内容: 尝试将Hibernate与SAP HANA内存数据库连接时遇到一些性能问题,该数据库不支持AUTO_INCREMENT(http://scn.sap.com/thread/3238906)。 因此,我将Hibernate设置为使用序列进行ID生成。 但是,当我插入大量记录(例如40000)时,Hibernate首先会生成ID。看起来像: 并且只有在生成所有ID之后,它才开始实际插入。
-
SQLite 性能优化实例分享
本文向大家介绍SQLite 性能优化实例分享,包括了SQLite 性能优化实例分享的使用技巧和注意事项,需要的朋友参考一下 最早接触 iOS 开发了解到的第一个缓存数据库就是 SQLite,后面一直也以 SQLite 作为中坚力量使用,以前没有接触到比较大量数据的读写,所以在性能优化方面关注不多,这次对一个特定场景的较多数据批量读写做了一个性能优化,使性能提高了十倍。 大致应用场景是这样: 每次程
-
ANTLR 4中的优先模糊性
我有一个巨大的ANTLR语法,我面临着一个小问题。语法有两个规则expr和set,定义如下: 这里的问题是,对于一组形式*s1*s2,应该减少如下: 然后RHS中的每一组应减少到: 但相反,它们正在减少: 因为forn的集合被解析为,而不是。 set的规则之一,将其简化为exr。语法中还有许多其他类似的规则也简化为exr。这里出现的问题是因为set和exr中的一些规则是相似的。但是因为有些规则不同
-
Java界面松耦合的优点?
有人能帮我吗,我读了一些Java紧耦合和松耦合的文章。我看了好几段YouTube视频和文章,对松散耦合有一定的怀疑,但仍然无法理解某些要点。我会解释我所理解的和让我困惑的。 在松散耦合中,我们限制类之间的直接耦合。但在紧密耦合中,我们注定要去上课。让我们举个例子。我有一个主类和另一个名为Apple的不同类。我在Main类中创建了这个类的一个实例 让我们看看松耦合 如果我将松散耦合中的方法签名从“喝
-
优化Postgres删除孤立记录
以以下两个表格为例: 和 主键和。 我需要删除任何没有相关的。大约有3MM和25MM记录。 我正在尝试以下两个问题: 正如您所看到的,即使不删除任何记录,两个查询都会在大约3分钟内显示类似的性能。 服务器磁盘I/O峰值达到100%,因此我假设数据正在溢出到磁盘,因为对和都进行了顺序扫描。 服务器是EC2r3.large(15GB RAM)。 我能做些什么来优化这个查询呢? 在为两个表运行并确保设置
-
通过反射打破JIT优化
在处理高度并发的单例类的单元测试时,我偶然发现了以下奇怪的行为(在JDK 1.8.0\U 162上测试): main()方法的最后两行在INSTANCE的值上不一致-我猜JIT完全摆脱了该方法,因为该字段是静态final。删除final关键字可以使代码输出正确的值。 撇开你对单例的同情(或缺乏同情)不谈,暂时忘记像这样使用反射是在自找麻烦——我的假设是正确的吗?JIT优化是罪魁祸首?如果是这样的话