《兴盛优选》专题
-
 我如何优化这个布局?
我如何优化这个布局?我试图通过扁平化视图层次结构来优化Android应用程序中的布局。这里有一个特别难的问题! 此布局有一个主线布局,用于容纳顶行和底行(它们本身就是水平的子线布局)。中间的四个项目中的每一个都是使用LayOut权重来展开的垂直相对性(以适应图像视图和文本视图)。包含两个项目的每一行也是一个水平线性布局。 不用说,这种布局效率非常低,在绘制时会导致许多“编排者跳过了帧”的消息。我想删除这些嵌套的布局,
-
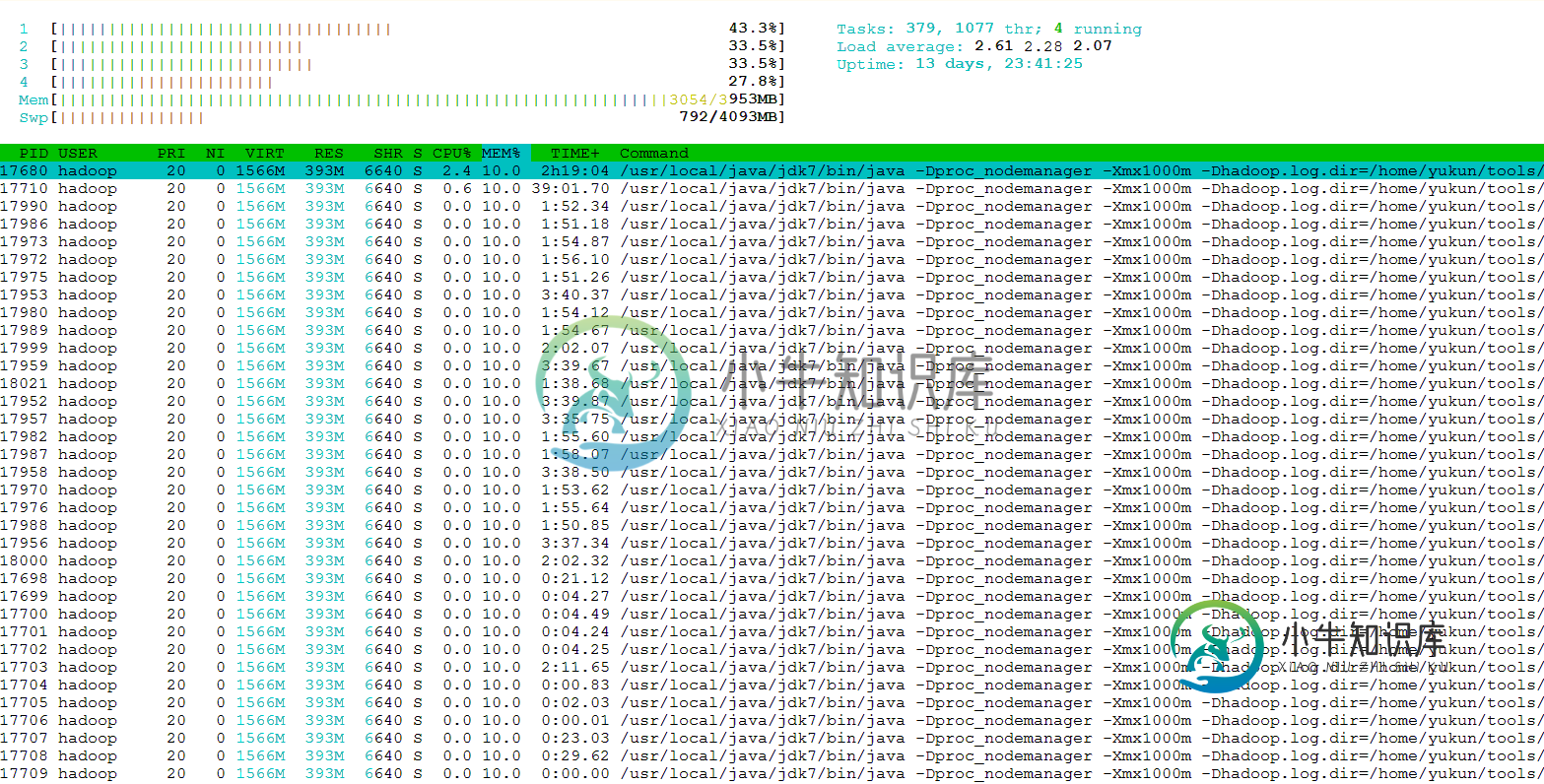 hadoop纱单节点性能调优
hadoop纱单节点性能调优我在我的Ubuntu VM上有hadoop 2.5.2单模式安装,它是:4核,每个核3GHz;4G内存。这个VM不是用于生产的,只用于演示和学习。 然后,我使用python编写了一个vey简单的map-reduce应用程序,并使用该应用程序处理49个XML。所有这些xml文件都很小,每个文件都有数百行。所以,我期待一个快速的过程。但是,big22令我惊讶的是,它花了20多分钟才完成这项工作(该工作
-
spring-boot 2优雅关机腹板
null 我正在尝试做一个优雅的关闭Rest应用程序和SCS(Kafka消费者和生产者)应用程序
-
gcc优化标志中断代码
存在与循环有关的问题。为什么?也许是虫子? 我使用的是最新的4.8.0,经过测试的x64、x86以及其他版本。都是同样的行为。
-
不可见的GCC优化标志?
我正在使用GCC4.4.2构建一些大型项目。因为我想构建它以供发布,所以我使用了GCC优化标志,但不幸的是,它在某种程度上弄乱了我的代码,最终的二进制文件没有按照预期工作,当使用标志(或没有优化)构建时,一切都很好。我之前的项目也有类似的问题,当时是标志在优化级别上造成了问题,我通过搜索本文档中提到的所有标志,就优化级别而言,设法发现它是由该特定标志引起的: http://gcc.gnu.org/
-
构造函数重载的优点
-
Repast Simphony调度方法优先级
我有一个模型,大约有10种调度方法。现在我对控制它们的执行有点困惑。我希望这些调度方法按照一定的顺序执行。 我怎么能有ScheduleParameters。第一优先级,计划参数。第二优先级,调度参数。第三优先权。。。,和调度参数。最后一个优先事项。
-
大型表的MySQL查询优化
我有一个需要50秒的查询 security_tasks中的记录=841321 relations中的记录=234254 我能做些什么让它快一点,比如快1秒或2秒 有什么想法吗?
-
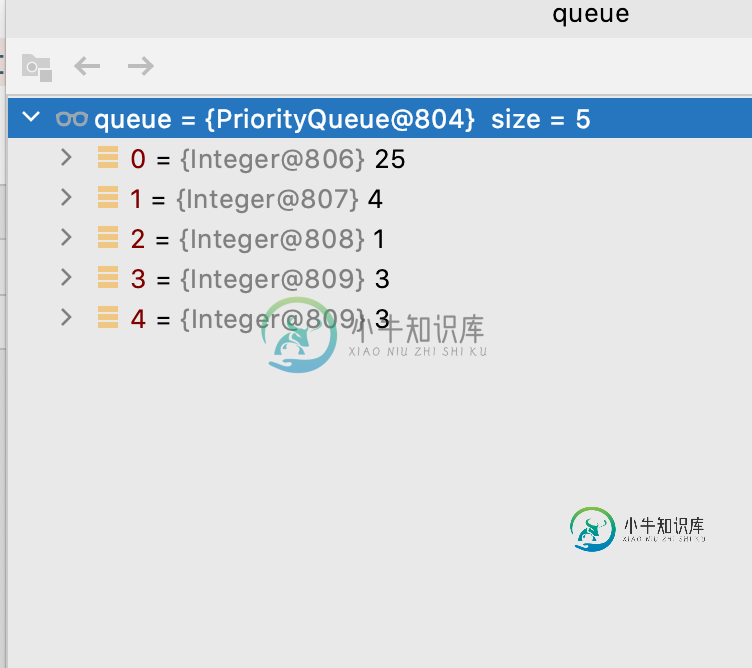 最大优先级队列函数
最大优先级队列函数我定义最大优先级队列如下: 我需要理解这是如何工作的,特别是当1只得到2的索引(而不是4)时? 多谢了。
-
如何优化列表操作?(CodeFights)
所以我有一个函数,在小列表上执行得很好。它的功能是检查从序列中删除一个元素是否会使该序列成为严格的递增序列: 但我需要它来处理长达10万个元素的列表。我可以做什么样的优化来更快地工作?现在,在10万个元素的列表中,它的速度非常慢,一秒钟要处理几千个元素。
-
如何优化查找相似性?
我有一组由浮点向量表示的30000个文档。所有向量都有100个元素。我可以通过使用向量之间的余弦度量来比较两个文档来找到相似性。问题是找到最相似的文档需要很多时间。有什么算法可以帮助我加快速度吗? 编辑 现在,我的代码只计算第一个向量和所有其他向量之间的余弦相似度。大约需要3秒钟。我想加快速度;)算法不一定要精确,但应该给出与全搜索相似的结果。 每个向量的元素之和等于1。
-
优化这个组合学算法
假设给你一个数字,N,这是你的目标数字。然后给你一系列p个数,你必须找到这些数中大于N的最小和,也就是说,它最小地超过了N(或者等于N)。 你可以取任意元素组合的任意和。p可以大到100。 我目前的算法:在扫描所有信息后,我创建了一个100位长的位集,并通过使用循环将从0到(2^p)-1的所有整数转换为它,有效地结束了000…000和111…111之间的所有二进制数。 如您所知,这些向量可以被解释
-
主键的优化不起作用
如果您在一个表上的非空列上使用计数,而没有任何where部分,则优化器只需返回该表中的行数。 如果您要求对一个唯一的非空列(如主键)进行非重复计数,答案应该是相同的,但是这次mariadb代替了。 如果您在其他表上留下了联接,但仍然没有 where 部分,则结果仍应为该表中的行数。 Mariadb 不使用千次优化是有原因的吗?是否存在未过滤主键的 DISTINCT 计数可以给出任何其他结果,然后该
-
在IntentService中优先考虑意图
我现在是这样做的: > 我有一个在后台运行并读取用户位置的服务。每次读取一个有效的位置(有一些参数,如距离和时间),一个IntentService开始将该位置发送到网络服务器 使用追踪服务的应用程序也有一些网络通话,具体取决于用户按下的选项。现在,应用程序只是在异步任务中调用web服务。 一些代码:位置服务会在每次收到好位置时启动IntentService,如下所示: intentservice处
-
Java优先级队列heapify[重复]
一般来说,如果我理解正确的话,在给定列表和添加每个元素之间的“heapizing;o(n)”运行时是有区别的;o(lg n)。java遵循这种行为吗?如果不是,下面的问题可能无效。 下面的示例似乎创建了一个"min-heap"。 然而,假设我想构建一个“最大堆”,但是构造函数不允许我同时传入集合和比较器。在这种情况下,构建最大堆的唯一方法是创建一个实现可比的包装器类吗? 注意:我知道可以用比较器创