《兴盛优选》专题
-
SQLite select语句优化建议
问题内容: 我有一个结构的SQLite表“ Details”: 我想随机选择一行,然后从三个不同的行中选择三个名称(同样最好随机选择)。我希望所有这些都可以从一个SQLite语句返回。例如 我的尝试可以从下面看到,但是有两个问题: 这三个额外的名称不一定总是不同的-我似乎无法排除先前选择的名称,因为变量b / c / d不在其自身的COALESCE函数范围内。 由于每个嵌套选择都使用Random(
-
MongoDB性能优化及监控
本文向大家介绍MongoDB性能优化及监控,包括了MongoDB性能优化及监控的使用技巧和注意事项,需要的朋友参考一下 MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。 MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。 一、索引 MongoDB 提供了多样性
-
c++ 网络库asio的优势
本文向大家介绍c++ 网络库asio的优势,包括了c++ 网络库asio的优势的使用技巧和注意事项,需要的朋友参考一下 如果说答案是性能,那么肯定有人会满不在乎。觉得性能不够的话, 只要加机器就可以了。 然而更少的机器,意味着更低的能耗,更少的硬件投入,更少的人力资源投入去维护机器。总而言之,更低的成本。 肯定会有人说,C++的开发速度太慢了。然而这并不是绝对的。C++也可以做到非常快速的开发。有
-
 webpack优化的深入理解
webpack优化的深入理解本文向大家介绍webpack优化的深入理解,包括了webpack优化的深入理解的使用技巧和注意事项,需要的朋友参考一下 前言 由于前端的快速发展,相关工具的发展速度也是相当迅猛,各大框架例如vue,react都有自己优秀的脚手架工具来帮助我们快速启动一个新项目,也正式因为这个原因,我们对于脚手架中最关键的一环webpack相关的优化知之甚少,脚手架基本上已经为我们做好了相关的开发准备,但是当我们想
-
Java优先级队列排序
我有一个,名为,其中包含类型的对象。 您可以在所有车辆上调用该方法。 我要做的是排序,这样车辆被赋予更高的优先级,并被放在队列的前面。 我假设我必须在这里使用一个比较器,但不知道怎么做。
-
进行微优化值得吗?
问题内容: 我是PHP开发人员,我一直认为微优化不值得。如果您确实需要这种额外的性能,则可以编写软件以使其在结构上更快,或者编写C ++扩展来处理缓慢的任务(或者更好的方法是使用HipHop编译代码)。但是今天有个同事告诉我 和 而且我就像“嗯,那确实是没有意义的比较”,但是他不同意我的看法。.他是我们公司中最好的开发人员,并且负责一个每天执行约5000万次SQL查询的网站- - 例如。因此,我在
-
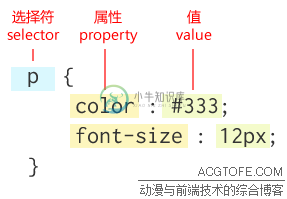 新手学习css优先级
新手学习css优先级本文向大家介绍新手学习css优先级,包括了新手学习css优先级的使用技巧和注意事项,需要的朋友参考一下 css不是一种程序语言,而是一种描述语言。因此,可以说,css理解起来是非常容易的,大部分人通过简单的学习就可以懂得如何写css代码来定义网页的样式。但是,大部分人同样也会在写css的过程中产生很多困惑,比如为什么自己写的某段css没有生效,或者呈现出的样式和预计的不同,但又不知道要如何解决。
-
加权随机n次优化
一个数组中有10个加权元素。我想随机选择一个元素N次,然后计算每个元素出现的次数。是否有一种算法可以在不需要选择N次的情况下为我提供元素计数<代码>N可能是一个很大的数字,在这种情况下,必须生成N个样本是低效的。 例如:一个盒子里有2个红色的球和8个白色的球。从盒子里随机挑选一个球,然后放回去,重复100次。计算拾取红色球或白色球的总次数。 我想知道是否有可能在不进行100次采样的情况下获得计数。
-
为什么index.html优先于index.php?
问题内容: 我在服务器上有一个网站。主页为example.com/index.php。 好的,我将一个index.html命名文件上传到服务器(根目录),当我在浏览器的URL栏中键入站点的域时,感到很惊讶,因为index.html页面已加载。 (example.com-> example.com/index.html)所以不是我想要的。 我的问题:为什么会这样?为什么index.html比inde
-
过时的Java优化技巧
问题内容: Java编译器(尤其是Profile-guided优化)已淘汰了许多性能技巧。例如,这些平台提供的优化可以大大地(根据源代码)降低虚拟函数调用的成本。VM还能够进行方法内联,循环展开等。 您还采用了哪些其他性能优化技术,但是实际上在更现代的JVM中发现的优化机制已使这些技术过时了吗? 问题答案: 方法和方法参数上的最终修饰符根本无法改善性能。 另外,Java HotSpot Wiki
-
Java中的尾调用优化
问题内容: 从Java 8开始,Java不提供尾叫优化(TCO)。经过研究,我知道原因是: 在JDK类中,有许多对安全性敏感的方法,它们依赖于对JDK库代码和调用代码之间的堆栈帧进行计数,以确定谁在调用它们。 但是,基于JVM的Scala支持尾叫优化。Scala在编译时进行尾递归优化。Java为什么不能使用相同的方法? PS:不确定Java的最新版本(截至现在的Java 11)是否具有TCO。如果
-
优化此ArrayList连接方法
问题内容: 我已编写此代码来加入ArrayList元素:是否可以对其进行更多优化?还是有其他更好的方法? 问题答案: 这就是著名的java.util.Collection团队的工作方式,所以我认为这应该很好;) 另外,这就是用达菲(Duffymo)的答案得到逗号分隔符的方法;)
-
唯一键,带EF码优先
问题内容: 我的项目中有以下模型 并且我试图Title作为唯一键,我用谷歌搜索了解决方案,但找不到任何解决方案。请问有什么建议我可以做的吗? 问题答案: 不幸的是,您不能首先将其定义为代码中的唯一键,因为EF根本不支持唯一键(希望在下一个主要版本中计划使用)。您可以做的是创建自定义数据库初始化器,并通过调用SQL命令手动添加唯一索引: 并且必须在应用程序的引导程序中设置此初始化程序。 编辑 现在(
-
xgboost,rf,lr优缺点场景?
本文向大家介绍xgboost,rf,lr优缺点场景?相关面试题,主要包含被问及xgboost,rf,lr优缺点场景?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: Xgboost: 优缺点:1)在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点
-
Redis 如何做内存优化?
本文向大家介绍Redis 如何做内存优化?相关面试题,主要包含被问及Redis 如何做内存优化?时的应答技巧和注意事项,需要的朋友参考一下 尽量使用 Redis 的散列表,把相关的信息放到散列表里面存储,而不是把每个字段单独存储,这样可以有效的减少内存使用。比如将 Web 系统的用户对象,应该放到散列表里面再整体存储到 Redis,而不是把用户的姓名、年龄、密码、邮箱等字段分别设置 key 进行存