《神策数据》专题
-
 吉比特雷霆游戏策划实习生笔经
吉比特雷霆游戏策划实习生笔经好快的面试通知。本来摆了的还是给吉比特写一下笔经吧 4.2 19.00-20.30 题型单选、多选、填空、问答 单多选基本行测题,很多概率题 填空题概率。有一题是六类五种装备,小明每天打三次副本,每次掉落随机一件装备。小明想要两件不同的特定装备,一天能获得的概率是多少? 问答题 1.五个洞,狐狸每天从一个洞移动到相邻的洞,怎么在每天只看一个洞的情况下必定抓住狐狸 2.ABC比武。A先手胜率0.3,
-
 多益网络游戏策划业务一面经验
多益网络游戏策划业务一面经验之前过了HR面,刚刚业务一面。 整体感受:每个人都不开心 面试官都很不爽的样子,戴个b口罩,讲话不清楚,背景昏暗,一副爱听不听的样子 答的很流畅的时候,叫你不用说了,然后问下一个问题 自我介绍(我是xxx,干了xxx,现在xxx) 玩过什么游戏(xxx) 聊项目(塔防游戏) 与一般塔防有什么区别(xxx) 为什么做这些设计(xxx) *回答到一半,她叫我别说,说她知道,让我“直接”说原因 做过美术
-
 微信支付产策群面+初面凉经分享
微信支付产策群面+初面凉经分享#非技术2023笔面经# 群面过了,但初试挂了我即将集齐腾讯所有事业群的面试凉经 【群面】60min 参与的这场群面是4个人,人数不多,本来看会议名称写8个人以为会比较乱,没想到还挺有秩序的...... 1.无自我介绍,面试官直接给题目,读题,题目是作为创业团队摆摊,然后给了大概10分钟时间解题 2.每个人依次说了各自的想法 3.30分钟讨论时间,整合方案 4. 3分钟report+面试官提问 【
-
 美团打车 策略运营实习 一面面经
美团打车 策略运营实习 一面面经楼主是2.7通过内推投递的美团打车策略运营岗日常实习 2.8日就有了回复(官网显示面试中,HR当天联系了我商量一面时间) 2.11日上午11点在腾讯会议进行了一面,差不多是半个小时 整体而言面试氛围非常轻松,面试官小姐姐非常温柔(可能自己面试经验太少显得有点紧张,不过后面慢慢地也还好) 首先就是简单的自我介绍(院校、专业、项目经历、获奖经历、掌握技能) 然后面试官小姐姐简单介绍了策略运营实习需要完
-
 美团打车 策略运营实习 二面面经
美团打车 策略运营实习 二面面经刚刚面试完,趁着自己还记得面试官提的一些问题赶来写一下自己的踩雷过程 下午面试的是一个小哥哥,感觉他不咋笑(面试过程气压较低) 最开始仍然是熟悉的自我介绍,然后针对简历上的一个项目进行提问(由于我没有好好准备这一个怎么讲加之时间过去了很久导致发挥得极其不好)【魔鬼十分钟】 后面小哥哥可能看出来我很菜了决定丢我一个概率论问题(T检验与Z检验的区别是什么) 我内心:不是该问sql和一些策略运营场景的问
-
如果让你策划设计一个影片评论功能的运营策略,你会如何进行竞品分析呢。
本文向大家介绍如果让你策划设计一个影片评论功能的运营策略,你会如何进行竞品分析呢。相关面试题,主要包含被问及如果让你策划设计一个影片评论功能的运营策略,你会如何进行竞品分析呢。时的应答技巧和注意事项,需要的朋友参考一下 一、选定3个与本产品同类的其他产品为竞品进行分析; 二、先整体从战略层、范围层、结构层、框架层和表现层进行分析; 三、重点分析其他产品的影片评论功能; 四、接着分析评论功能的运营策
-
 UITableView自动调整大小的行约束在iPhone 6Plus上神秘地打破
UITableView自动调整大小的行约束在iPhone 6Plus上神秘地打破问题内容: 我有一个自定义UITableViewCell,其中包含缩略图和一堆文本。行高配置为使用以下方式自动计算 行高应精确计算为 138 点。在iPhone 5上,一切看起来都很不错。但是,在iPhone 6 Plus上,对于具有以下日志的随机行,自动行高度会间歇性地失败。 日志的最后一行似乎说,由于某种原因,行高被计算为 138.333 而不是138 。我已经打了一段时间,但我无法弄清楚为什
-
从Spring Boot 1.2.8切换到1.3.2后,应用程序神奇地停止工作
问题内容: 从Spring Boot 1.2.8升级到1.3.2后,我的应用程序突然停止工作。 在应用程序启动时,出现以下异常。 似乎有问题,但我不知道为什么。在1.2.8版中,所有内容都像魅力一样。 这是我的 问题答案: 听起来您有一个或多个文件,但没有文件。从1.3.2发布公告: 如果从1.3.1升级,则可能会有一项重大更改;我们现在仅搜索(而不是)以启用消息源的自动配置。如果您以前有一个格式
-
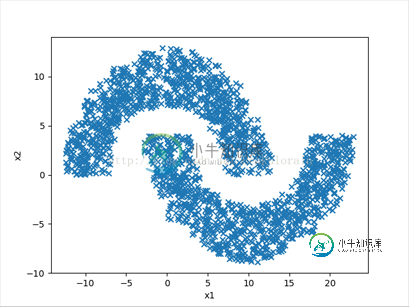 利用TensorFlow训练简单的二分类神经网络模型的方法
利用TensorFlow训练简单的二分类神经网络模型的方法本文向大家介绍利用TensorFlow训练简单的二分类神经网络模型的方法,包括了利用TensorFlow训练简单的二分类神经网络模型的方法的使用技巧和注意事项,需要的朋友参考一下 利用TensorFlow实现《神经网络与机器学习》一书中4.7模式分类练习 具体问题是将如下图所示双月牙数据集分类。 使用到的工具: python3.5 tensorflow1.2.1 numpy matp
-
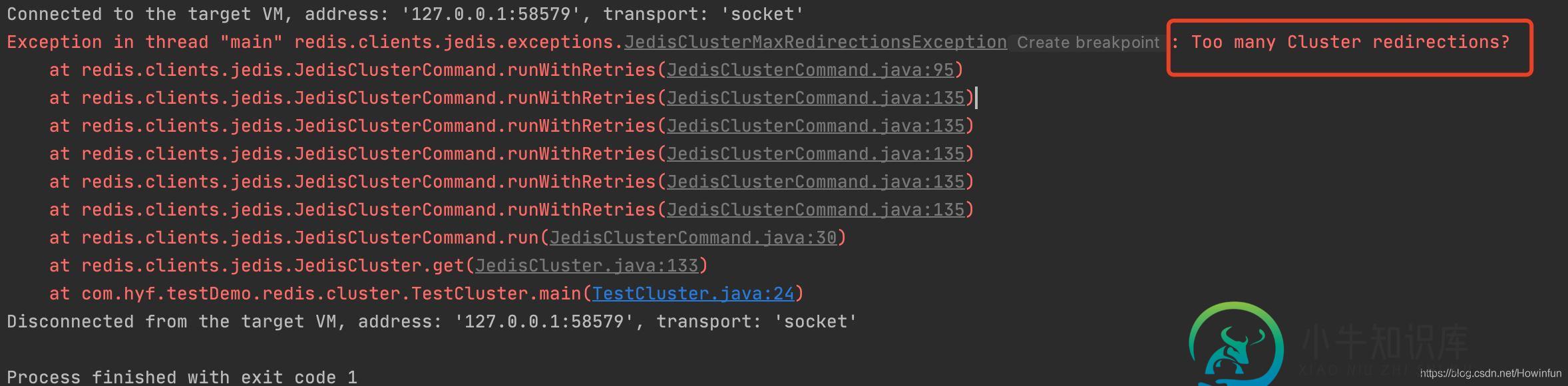 Docker 部署单机版 Pulsar 和集群架构 Redis(开发神器)的方法
Docker 部署单机版 Pulsar 和集群架构 Redis(开发神器)的方法本文向大家介绍Docker 部署单机版 Pulsar 和集群架构 Redis(开发神器)的方法,包括了Docker 部署单机版 Pulsar 和集群架构 Redis(开发神器)的方法的使用技巧和注意事项,需要的朋友参考一下 一、前言: 现在互联网的技术架构中,不断出现各种各样的中间件,例如 MQ、Redis、Zookeeper,这些中间件在部署的时候一般都是以主从架构或者集群的架构来部署,公司一般
-
由原始类型引起的代码重复:如何避免精神错乱?
问题内容: 在我的一个Java项目中,由于Java处理(而非)原语的方式,我受到代码重复的困扰。不必后手动复制到四个不同的位置相同的变化(,,,) 再次 ,对于 第三次 的时候, 再 和 再次 我来到非常接近(?)来抢购。 共识似乎收敛到两个可能的选择: 使用某种代码生成器。 你能做什么? 这就是生活! 嗯,第二种 解决方案 是我现在正在做的事情,并且它对我的理智逐渐变得危险,就像众所周知的酷刑技
-
 PyTorch上搭建简单神经网络实现回归和分类的示例
PyTorch上搭建简单神经网络实现回归和分类的示例本文向大家介绍PyTorch上搭建简单神经网络实现回归和分类的示例,包括了PyTorch上搭建简单神经网络实现回归和分类的示例的使用技巧和注意事项,需要的朋友参考一下 本文介绍了PyTorch上搭建简单神经网络实现回归和分类的示例,分享给大家,具体如下: 一、PyTorch入门 1. 安装方法 登录PyTorch官网,http://pytorch.org,可以看到以下界面: 按上图的选项选择后即可
-
为什么在卷积神经网络中使用ReLU作为激活单元?
我正在尝试使用CNN对图像进行分类,据我所知,ReLu是每个卷积层中激活单元的常用选择。根据我的理解,ReLU将保留所有正图像强度,并将负图像强度转换为0。对我来说,这就像是处理步骤,而不是真正的“启动”步骤。那么,在这里使用ReLU的目的是什么?
-
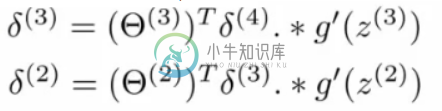 反向传播(神经网络)中获取增量项时的尺寸误差
反向传播(神经网络)中获取增量项时的尺寸误差我正在创建一个具有以下维度的三层图像识别神经网络:400个特征、40个节点、40个节点、10个目标(数字0到9的图像),因此这些是我的权重(θ): 我遵循吴恩达的方法。我在反向传播工作中遇到了一些问题。首先,我通过找出实际结果和预测之间的差异来得到delta\u 4项。然后,使用以下等式获得剩余的δ项, 其中g'是sigmoid函数的导数。我编码了以下函数: 然后,获得梯度的整个反向传播过程如下所
-
卷积神经网络中卷积滤波器为什么翻转?[已关闭]
此问题似乎与在帮助中心定义的范围内编程无关。 我不明白为什么在使用卷积神经网络时需要翻转滤波器。 根据千层面文件, flip_filters:bool(默认值:True) 是在将过滤器滑动到输入上之前翻转过滤器,执行卷积(这是默认设置),还是不翻转过滤器并执行相关。请注意,对于千层面中的其他一些卷积层,翻转会产生开销,默认情况下是禁用的–使用从其他层学习的权重时,请查看文档。 这是什么意思?我从未