《猫眼》专题
-
如何一次将一个函数应用到熊猫数据帧中的多个列
我经常处理格式不好的数据(即数字字段不一致等) 可能还有其他方法,我不知道,但我格式化数据帧中单个列的方法是使用函数并将该列映射到该函数。 问题:1-如果我有一个包含50列的数据框,并且想要将该格式应用于多个列,等等列1, 3, 5, 7, 9, 你能去吗 ...这样我可以格式化所有的数字列在一行?
-
熊猫在*上阅读。用cedilla分隔的dat文件未在dataframe中拆分为列
这是我第一次研究熊猫,请原谅我的无知。我的要求是将一个文件从S3下载到Ec2上,并将dat文件放到数据帧上。这就是我的输入文件数据的外观 由于数据似乎没有任何编码,所以我决定使用带有分隔符的read_Csv作为cedilla并存储在dataframe中。 但由于某些原因,它无法识别相同的数据并将数据放在一列中。 该文件似乎像ASCII和未编码。我确实尝试过使用UTF-8和UTF-16编码,并将Un
-
熊猫-用另一个数据帧的值填充一个数据帧的每一行
我有两个Dataframes一个与日期集(df1)和另一个与emp_ids集(df2)。我试图创建一个新的Dataframe,这样df2中的每个emp_id都被标记为df1中的每个日期。 下面给出了我的数据帧的外观 df1 df2 预期产出: 我将日期列转换为字符串,并尝试执行以下操作,但返回的数据框为空 我尝试做
-
代码需要太多时间进行规范化和在熊猫中应用函数
这只是我的代码中的示例数据。我想规范化其他列中的合计列。目前我有大约2000个小组,正常化和fgroup需要15分钟。 减少时间的方法有哪些。 谢谢
-
熊猫:如何删除重复的行,但保持所有行的最大值[重复]
如何删除重复行,但保留所有行的最大值。例如,我有一个包含4行的数据帧: 从这个数据帧中,我想有一个这样的数据帧(3行,按'a'分组,保留所有在'c'中有最大值的行):
-
如何将用户采集与猫鼬中的其他数据采集联系起来?
我正在制作一个带有节点的待办事项列表网站。js并使用mongoose数据库。在这个数据库里我有两个同事, 具有如下模式的用户集合:constuserschema=newmongoose。模式({email:String,password:String,googleId:String}) 列表集合,用于存储具有以下模式的列表项:const itemschema={name:String}如何确保如果
-
在猫鼬模式上应用2dsphere索引是否会强制要求位置字段?
问题内容: 我有一个猫鼬的架构和模型,定义如下: 如果我尝试: 我收到错误消息: 尽管不需要此架构中的location字段,但无论如何它似乎都在起作用。我尝试添加可以避免此错误的方法,但是似乎有点hack,因为这显然不是一个很好的默认值,理想情况下,该架构不需要用户始终有位置。 MongoDB / mongoose的地理空间索引是否暗示需要建立索引的字段? 问题答案: 默认情况下,声明为数组的属性
-
如何使用猫鼬获取当前物品的下一个和上一个物品
问题内容: 我有一个博客。在单个帖子页面上,我想显示指向上一个帖子的链接,如果有一个链接,则在底部发布下一个帖子。该链接应为特定帖子的标题。 我如何用猫鼬最简单的方式做到这一点? 我当前的控制器如下所示: 架构如下所示: 问题答案: 因此,假设您拥有这样的架构: 我想_id是mongo ObjectId,所以我们包含发布日期,我可以对其进行排序 让我们考虑一下,我已经打开了ID为的当前帖子(而不是
-
 TensorFlow卷积神经网络之使用训练好的模型识别猫狗图片
TensorFlow卷积神经网络之使用训练好的模型识别猫狗图片本文向大家介绍TensorFlow卷积神经网络之使用训练好的模型识别猫狗图片,包括了TensorFlow卷积神经网络之使用训练好的模型识别猫狗图片的使用技巧和注意事项,需要的朋友参考一下 本文是Python通过TensorFlow卷积神经网络实现猫狗识别的姊妹篇,是加载上一篇训练好的模型,进行猫狗识别 本文逻辑: 我从网上下载了十几张猫和狗的图片,用于检验我们训练好的模型。 处理我们下载的图片 加
-
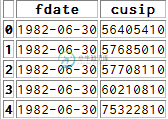 合并其中一个值介于其他两个值之间的熊猫数据框
合并其中一个值介于其他两个值之间的熊猫数据框问题内容: 这个问题已经在这里有了答案 : 如何联接两个列范围在一定范围内的数据框? (5个答案) 2年前关闭。 我需要在一个标识符和一个数据帧中的日期位于另一个数据帧中的两个日期之间的条件下合并两个熊猫数据帧。 数据框A具有日期(“ fdate”)和ID(“ cusip”): 我需要将此与此数据框B合并: 在和之间和。 在SQL中,这是微不足道的,但是我看到的如何在pandas中做到这一点的唯一
-
猫鼬之前/之后的中间件软件无法使用ES6访问[this]实例
问题内容: 我有两难选择,尝试使用中间件向猫鼬模型添加一些预逻辑,并且无法像往常一样访问实例。 问题:*是否有访问实例的方法? 问题答案: 在这种情况下,粗箭头符号()无效。相反,只需使用老式的匿名函数符号: 原因是粗箭头将函数按词法绑定到当前作用域(此处有更多内容,但TL; DR:粗箭头表示法不是一般的快捷方式表示法,而是专门创建词法绑定的函数),而该函数 应 在Mongoose提供的范围内调用
-
将函数应用于熊猫数据框的每一行以创建两个新列
问题内容: 我有一个熊猫DataFrame,其中包含多个列: 我想基于对数据框的每一行应用一个函数为此数据框创建两个新列。我不想多次调用该函数(例如,通过执行两次单独的调用),因为它占用大量计算资源。我尝试通过两种方式来执行此操作,但它们都不起作用: 使用: 我编写了一个函数,该函数接受a并返回我想要的值的元组: 尝试将此应用于DataFrame会出现错误: 然后,我将使用此问题中显示的方法将从返
-
以有效的方式附加基于多种条件的熊猫数据帧列(python)
我有一个如下所示的数据框,我必须准备“目标列” 如果同一列下的两个单词之间有逗号,则必须按第2行所示标记两次。如果没有逗号但有空格,则必须将其视为同一个单词,即必须标记一次。另外,请注意顺序也很重要(第3行和第6行)。忽略任何内容(即没有单词,因此没有标签) 我已经使用了迭代(即使用iloc,for循环),但是它需要大量的时间,因为数据点超过200k,标签的数量也超过20个。我希望有一个有效的代码
-
如何设置和显示x/y标签与熊猫图在ipython笔记本?[重复]
当我在ipython笔记本中绘制熊猫系列并根据这个答案设置标签时: 并对细胞进行评估。绘图显示标题,但不显示x或y标签。如何在ipython笔记本中执行此操作? 还有Chrispy在那篇帖子上的评论 为什么x和y标签不能作为参数添加到pd.plot()中? 也可能是一个值得回答的相关问题。 编辑:谢谢,现在我知道错误,我的错。但是为什么它没有给我一个错误的值分配给方法
-
如何将自定义函数应用到每一行的熊猫数据帧[重复]
我想应用一个自定义函数并创建一个名为population2050的派生列,该列基于数据框中已经存在的两列。 当我运行上面的代码时,我得到一个错误。我是否没有正确使用“应用”功能?