《猫眼》专题
-
如何将熊猫数据框中的日期转换为“日期”数据类型?
问题内容: 我有一个熊猫数据框,其中一列包含格式为日期的字符串 例如 目前该列的是。 如何将列值转换为Pandas日期格式? 问题答案: 使用类型
-
现在需要你设计一个“校园版天猫”,请简述你的想法。
本文向大家介绍现在需要你设计一个“校园版天猫”,请简述你的想法。相关面试题,主要包含被问及现在需要你设计一个“校园版天猫”,请简述你的想法。时的应答技巧和注意事项,需要的朋友参考一下 ”校园版天猫“服务的人群大学生最大的特点是他们位置很集中,很多需求非常个性化(例如对一些教材、宿舍神器的需求非学生基本上没有)。因此,我设计的这款产品会和新零售结合起来; 1.校园版天猫会以一个个学校作为节点,并且每
-
在模型上按其引用模型的字段进行猫鼬嵌套查询
问题内容: 关于stackoverflow的这个主题似乎有很多问题,但是我似乎在任何地方都找不到确切的答案。 我有的: 我有Company和Person模型: 我需要的: 查找姓氏为“ Robertson”的人已创建的所有公司 我试过的 然后我发现Person不是嵌入式的,而是被引用的,所以我使用populate来填充Founder- Person,然后尝试使用带有’Robertson’姓氏的fi
-
如何获取另一个模型中定义的猫鼬数据库的架构
问题内容: 这是我的文件夹结构: 我在Songs.js文件中的代码 这是我在文件albums.js中的代码 我怎样才能让albums.js知道 SongSchema 被定义AlbumSchema 问题答案: 您可以直接使用Mongoose获取在其他地方定义的模型: 要在您的示例中通过albums.js获取架构,您可以执行以下操作:
-
熊猫数据框创建新列并填充来自同一df的计算值
问题内容: 这是我的df的简化示例: 我想按行对列中的数据求和: 现在,我的问题来了!我想创建4个新列,并从每一行的总和中计算百分比值。因此,第一个新列中的第一个值应该是(0.095389 / 4.258550),第二个新列中的第一个值(0.556978 / 4.258550)…依此类推…请帮助 问题答案: 您可以像这样手动轻松地为每个列执行此操作: 如果您要一步一步对所有列进行此操作,则可以使用
-
在Python中使用熊猫分析YYYYMMDD和HH在单独的列中的日期
问题内容: 我有一个与csv文件和解析datetime有关的简单问题。 我有一个csv文件,如下所示: 我想使用pandas(read_csv)读取它,并将其放入由datetime索引的数据帧中。到目前为止,我已经尝试实现以下内容: 我得到的结果是: 如您所见,将HH转换为其他日期时的parse_dates。 是否有一种简单有效的方法将“ YYYYMMDD”列与“ HH”列正确组合,以实现类似的目
-
由于额外的列值,在尝试使用熊猫Python读取csv时出错
以下是我试图摆脱的场景: 我试图读取以下类型的csv: 我正在使用以下命令并得到以下错误: 我试图搜索这个问题,并在SO上得到了这个线程: Python熊猫错误标记化数据 所以,我努力了。这不是我所期望的。它正在截断值。 我想要的是这样的: 如果有额外的值,那么将列作为整数值,并在额外值中找到最高的列。然后将剩余的值设为零(0),直到最后一列并读取csv。 我期望的输出如下: 但是请注意,我不想照
-
熊猫。DataFrame.fillna-TypeError:只有整数标量数组可以转换为标量索引
我想从官方熊猫留档...DataFrame.fillna所以基本上用值1填充df数据框“myc”列中的NaN值。 数据帧 代码1 成果目标1 误差表第1页 代码2我后来还尝试列出any_feature列 错误2 尝试解决方案 Not dictionary - Pandas: Getting "TypeError: only integer scalar arrays can be converte
-
使用熊猫to_datetime()方法与正确的语法,未识别的值类型:str?
我正在努力使用pandas的to_datetime函数将csv文件中的条目转换为datetime对象,以便将它们用于可视化。我似乎误解了一些关于如何创建datetime对象或参数的简单问题。 我有一个csv文件,包括几个日期记录,一个日期/时间记录的例子(即一行csv文件的例子)... 我想使用matplotlib可视化这个csv文件中的每个时间。我正在阅读留档,我记得看到Matplotlib与d
-
如何过度应用"utf-8"在熊猫数据框中打开csv/txt文件?
我试图从特定文件路径的文本文件导入数据,但我得到错误 我的问题是,无论如何,我可以将“utf-8”编码应用于所有最终必须打开的文本文件(大约20个其他文件),以便防止上述错误? 代码: 如果我做错了什么,我也愿意接受任何建议。 先谢谢你。
-
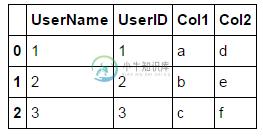 熊猫在具有不同名称的列上合并并避免重复[重复]
熊猫在具有不同名称的列上合并并避免重复[重复]如何将两个熊猫DataFrames合并到两个具有不同名称的列上,并保留其中一个列? 这提供了一个像这样的数据帧 但是很明显,我正在合并和,所以它们是相同的。我想让它看起来像这样。有什么干净的方法可以做到这一点吗? 我唯一能想到的方法是在合并之前将列重新命名为相同的列,或者在合并之后删除其中一个列。如果熊猫自动掉落其中一只,我会很高兴,或者我可以做类似的事情
-
基于其他数据帧中的列值在熊猫数据帧中创建列
我有两个熊猫数据框 步骤2:对于flag=1的行,AA_new将计算为var1(来自df2)*组“A”和val“AA”的df1的'cal1'值*组“A”和val“AA”的df1的'cal2'值,类似地,AB_new将计算为var1(来自df2)*组“A”和val“AB”的df1的'cal1'值*组“A”和val“AB”的df1的'cal2'值 我的预期输出如下所示: 以下基于其他stackflow
-
通过在熊猫的不同列上应用条件过滤数据帧[重复]
我正在寻找通过以下条件过滤df的方法: 由创建的
-
在熊猫中查找时间序列范围中的最小和最大日期
我有一个数据框,如下所示,带有网站名称和每个网站的日期范围。 我希望找到每个站点的开始和结束日期,并按如下方式布置数据框架: 我知道我可以找到整个范围的最小值和最大值,如下所示: 只是不确定最好的方法是将它分别应用于每个站点。
-
最小/最大分组在熊猫中使用单独的时间戳列[重复]
我有一个熊猫数据框与重叠的时间跨度,看起来像这样: 我的目标是获得每组的最小值和最大值。我试过: 但这只按的最小值和最大值进行分组,而我正在寻找每组的的最小值和的最大值。 例如,在聚合之后,grp6应该具有最小的和最大的 熊猫有没有一个简单的解决办法?