《猫眼》专题
-
熊猫返回不在其他数据框中的数据框中的列
问题内容: 我有两个看起来像这样的数据框: 现在,如果我利用pandas .isin函数,我可以做一些漂亮的事情 列和from存在于while中不 我的问题是:是否有人知道为df_2中但不存在于df_1中的列返回列标签的方法 像这样的东西 先感谢您! 问题答案: 熊猫索引对象具有类似集合的属性,因此您可以直接执行以下操作: 您还可以使用运算符来计算交集,并集和对称差: 过去存在差异的运算符,现已弃
-
如何为熊猫中的多个变量按列创建所有组合?
问题内容: 对于n个变量的给定范围。我以n = 3为例。 注意,上述范围内的值也可以是浮点型的。 我们如何创建一个数据框,其中每一列代表输入变量的唯一组合? 问题答案: 使用Itertools.product,我可以创建一个列表的所有组合,然后您可以将每个组合写入DataFrame
-
将列中的所有值复制到熊猫数据框中的新列
这是一个非常基本的问题,我似乎找不到答案。 我有一个这样的数据帧,叫做df: 然后我从df中提取所有行,其中列'B'的值为'B.2'。我将这些结果分配给df_2。 df_2变成: 然后,我将列B中的所有值复制到名为D的新列中。使df_2成为: 当我执行这样的任务时: 我得到以下警告: 试图在数据帧切片的副本上设置值。尝试使用。loc[row\u indexer,col\u indexer]=改为v
-
熊猫:添加新列并按条件从另一个数据帧赋值
我有两个数据帧DF1和DF2 DF1: DF2: 我想在DF1中创建一列“image1”,并根据以下条件赋值。 检查值是否在和DF2['documentType']=='Image'中可用 因此,输出应该如下所示: 不知道如何解决这个问题,但一些想法: -加入/合并是我的第一个想法,但是如何处理这些条件呢? -可能使用检查条件的功能映射/应用
-
熊猫错误: isin()得到了一个意外的关键字参数'case'
我有以下代码,其中包括一个具有各种资本化的列表。我想使用case=False将Pandas代码设置为忽略区分大小写,但是我的代码触发了以下错误: TypeError:isin()获得意外的关键字参数“case” 你能帮忙吗
-
如何使猫鼬模式属性的类型(另一个)模式需要
我有这个猫鼬帖子模式。 在验证中,类型为,
-
为什么猫鼬总是在我的收藏名后面加一个s
例如,此代码导致创建一个名为“datas”的集合 这个代码会创建一个叫做“用户”的集合 谢谢
-
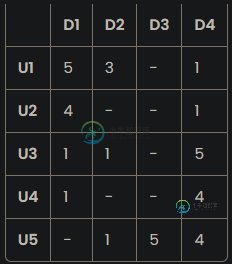 根据列值[duplicate]在熊猫中创建类似矩阵的数据帧
根据列值[duplicate]在熊猫中创建类似矩阵的数据帧我有一个事件日志数据框,每行是一个事件(如查看项目),其中包含列,,以及用户分配项目的。我想创建一个表示所有用户-项目交互的数据框:表示为二维矩阵,每个(i,j)表示用户i和项目j的分数(下图截图)。如果用户尚未看到该产品,则分配NaN。 我试过用循环做这件事,但正如预期的那样,运行时间太长: 有没有更快的方法? 根据评论中的要求,我的数据帧的头部<代码>事件类型与上述分数类似。
-
将某些浮动数据帧列格式化为熊猫的百分比
我试图在IPython笔记本上写一篇论文,但在显示格式方面遇到了一些问题。假设我有以下数据帧,是否有方法将和格式化为2位小数,将格式化为百分比。 里面的数字不乘以100,例如-0.0057=-0.57%。
-
npm install猫鼬会导致gyp和kerberos错误(找不到gssapi / gssapi.h文件)
问题内容: Ubuntu 14.04 *使用以下命令安装了 *nodejs 版本 v4.1.1 : MongoDB的 安装通过MongoDB的文档教程 接下来我尝试通过做安装 猫鼬 我收到以下错误: 我尝试通过安装 make 尝试再次通过npm安装猫鼬,收到以下错误: 我尝试通过安装 g ++ 尝试再次安装猫鼬,收到错误: 关于我的问题是什么? 问题答案: 尝试安装Kerberos开发包:
-
将大熊猫中的时间序列重新采样到每周间隔
问题内容: 如何将大熊猫中的时间序列重新采样为每周从任意一天开始的每周频率?我看到有一个可选的关键字库,但它仅适用于少于一天的时间间隔。 问题答案: 您可以将锚定的偏移量传递给,以及它们涵盖此情况的其他选项。 例如,星期一的每周频率:
-
使用熊猫数据框中的数据创建多个Excel工作表
问题内容: 刚开始使用pandas和python。 我有一个工作表,已读入数据框并应用了前向填充(ffill)方法。 然后,我想创建一个包含两个工作表的Excel文档。 在应用填充方法之前,一个工作表将在数据框中包含数据,而在下一个工作表将应用了填充方法的数据框。 最终,我打算为数据框的特定列中的每个数据唯一实例创建一个工作表。 然后,我想对结果应用某些vba格式-但我不确定哪个dll或插件,或者
-
熊猫:在不知道列名的情况下重命名单个DataFrame列
我知道我可以给单只熊猫重新命名。DataFrame列具有: 但是我想在不知道列名称的情况下重命名它(基于它的索引-尽管我知道字典没有)。我想重命名第1列,如下所示: 但是在DataFrame.columns dict中没有“1”条目,因此不进行重命名。我怎样才能做到这一点?
-
Python(熊猫)-处理数字数据,但添加非数字数据回来
我有一个CSV文件,如下所示: 我想得到每列的平均值,最小值,最大值,并将这些统计数据作为新行。我排除非数字列(构建列),然后运行统计信息。我通过这样做来实现这一点: 如果我当时将此数据写入CSV,它将如下所示: 这接近我想要的,但我希望构建列再次成为第一列,并在最小,平均,最大值的顶部存在构建名称。基本上是这样的: 我试图通过以下方式实现这一目标: 但这给了我一个CSV: 我怎样才能解决这个问题
-
错误:格式错误的节点或字符串:0在熊猫[重复]
我有一个列,其中的值保存为字典,我使用下面的代码将值分解为两个单独的列,但是,我正在努力处理具有空值的行(请参见下面的错误消息):df desired_output_df 我的代码: 但是,我收到以下错误:ValueError:节点或字符串格式错误:0