
根据列值[duplicate]在熊猫中创建类似矩阵的数据帧

我有一个事件日志数据框,每行是一个事件(如查看项目),其中包含列user_id,item_id,以及用户分配项目的评级。我想创建一个表示所有用户-项目交互的数据框:表示为二维矩阵,每个(i,j)表示用户i和项目j的分数(下图截图)。如果用户尚未看到该产品,则分配NaN。
我试过用循环做这件事,但正如预期的那样,运行时间太长:
collab = pd.DataFrame(columns=log.item_id.unique(), index=log.user_id.unique())
for c in collab.columns:
for u in collab.index:
try:
collab[c].loc[u] = log[(log.item_id == c) & (log.user_id == u)].score
except:
collab[c].loc[u] = np.nan
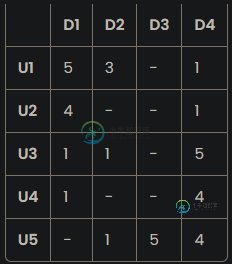
有没有更快的方法?
根据评论中的要求,我的数据帧的头部<代码>事件类型与上述分数类似。
{'item_id': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0},
'user_id': {0: 0, 1: 1, 2: 1, 3: 1, 4: 1},
'event_type': {0: 2, 1: 2, 2: 5, 3: 7, 4: 6},
'create_timestamp': {0: Timestamp('2020-02-03 15:47:25.273977'),
1: Timestamp('2020-02-04 20:19:31.040304'),
2: Timestamp('2020-02-04 20:19:00.110416'),
3: Timestamp('2020-02-04 20:54:31.595305'),
4: Timestamp('2020-02-04 20:20:15.918646')}}
共有1个答案

您可以使用df。pivot():
import pandas as pd
df = pd.DataFrame({'user_id': [1, 1, 1, 2, 2, 2],
'item_id': [1, 2, 3, 1, 2, 4],
'rating': [1, 2, 3, 4, 5, 6]})
df.pivot('user_id', 'item_id')
rating
item_id 1 2 3 4
user_id
1 1.0 2.0 3.0 NaN
2 4.0 5.0 NaN 6.0
-
我有两个熊猫数据框 步骤2:对于flag=1的行,AA_new将计算为var1(来自df2)*组“A”和val“AA”的df1的'cal1'值*组“A”和val“AA”的df1的'cal2'值,类似地,AB_new将计算为var1(来自df2)*组“A”和val“AB”的df1的'cal1'值*组“A”和val“AB”的df1的'cal2'值 我的预期输出如下所示: 以下基于其他stackflow
-
问题内容: 我有一个熊猫数据框,看起来像这样: 一千行左右,六列。大多数单元格为空(NaN)。考虑到不同的列中包含文本,我想知道每列中文本的概率是多少。例如,这里的小片段将产生如下内容: 也就是说,Al01栏中有4个匹配项;在这4个匹配中,BBR60列中没有匹配,CA07列中也没有匹配,NL219列中有3个匹配。等等。 我可以遍历每一列并使用值构建字典,但这似乎很笨拙。有没有更简单的方法? 问题答
-
我有点被困在提取一个变量的值和另一个变量的条件上。例如,以下数据帧: 当时,如何获取的值?每次提取的值时,都会得到一个对象,而不是字符串。
-
如果我有一个包含以下列的数据帧: 我想能够说:这里是一个数据框,给我一个列的列表,它是类型Object还是类型DateTime? 我有一个将数字(Float64)转换为两位小数的函数,我想使用这个特定类型的dataframe列列表,并通过这个函数将它们全部转换为2dp。 也许 吧:
-
问题内容: 如果我有一个包含以下列的数据框: 我想说:这是一个数据框,请给我列出对象类型或日期时间类型的列的列表吗? 我有一个将数字(Float64)转换为两位小数的函数,并且我想使用此数据框列的特定类型的列表,并通过此函数运行它以将它们全部转换为2dp。 也许: 问题答案: 如果您想要某种类型的列的列表,可以使用:
-
我有一个pandas dataframe,需要根据dataframe中其他列的值创建新列。这是数据帧 人城市国家国家 美国伊利诺伊州芝加哥 美国亚利桑那州凤凰城B酒店 C美国加利福尼亚州圣地亚哥 我想根据state中的值创建两个新列 创建新列df[“城北”]=df[“城市”]其中state=“伊利诺伊” 创建新列df[“城市南部”]=df[“城市”],其中州不等于“伊利诺伊州” 我试过了 但是不等