《猫眼》专题
-
熊猫:在excel文件中查找工作表列表
新版本的Pandas使用以下界面加载Excel文件: 但是如果我不知道可用的床单呢? 例如,我正在使用excel文件,这些文件包含以下表格 数据1,数据2。。。,数据N,foo,bar 但是我不知道什么是先验的。 有没有办法从Pandas中的excel文档中获取工作表列表?
-
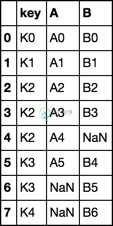 将熊猫数据框与关键重复项合并
将熊猫数据框与关键重复项合并问题内容: 我有2个数据框,两个数据框都有一个可能有重复的键列,但这些数据框大多具有相同的重复键。我想将这些数据帧合并到该键上,但是以这样的方式,当两个数据帧具有相同的重复项时,这些重复项将分别合并。另外,如果一个数据框比另一个数据框具有更多的重复键,我希望将其值填充为NaN。例如: 我正在尝试获得以下输出 因此,基本上,我想将重复的K2键视为K2_1,K2_2 …,然后在数据帧上进行how =’
-
如何摆脱熊猫DataFrame中的“未命名:0”列?
问题内容: 我遇到一种情况,有时当我从中读取时,会得到一个不需要的类似索引的列,名为。 CSV读取与此: 这很烦人!有谁知道如何摆脱这一点? 问题答案: 这是索引列,请通过传递以免将其写出,请参阅文档 例: 与之比较: 您还可以选择通过传递以下内容来判断第一列是索引列:
-
根据列表对熊猫数据框进行排序
问题内容: 我想对以下数据框进行排序: 我想对它进行排序,以便根据列表对LSE列进行重新排序: 当然,其他列也需要相应地重新排序。有没有办法在熊猫里做到这一点? 问题答案: pandas0.15版中对s的改进支持使您可以轻松做到这一点: 如果这只是临时排序,则可能不希望将LSE列保留为a ,但是如果您希望这种排序能够在不同的上下文中使用几次,则是一个很好的解决方案。 在更高版本的,中,已被替换为,
-
大熊猫以新的列名指定为字符串
问题内容: 我最近发现了熊猫的“分配”方法,我发现它非常优雅。我的问题是新列的名称被指定为关键字,因此它不能包含空格或破折号。 但是如果我想将新列命名为“ ln(A)”怎么办?例如 我知道我可以在.assign调用之后立即重命名该列,但是我想了解更多有关此方法及其语法的信息。 问题答案: 您可以将关键字参数传递为字典,如下所示:
-
创建后如何在猫鼬中填充子文档?
问题内容: 我要在item.comments列表中添加评论。在响应中将其输出之前,我需要获取comment.created_by用户数据。我应该怎么做? 我需要在res.json输出中填充comment.created_by字段: comment.created_by是我的猫鼬CommentSchema中的用户参考。它目前只给我一个用户ID,我需要它填充所有用户数据,密码和盐字段除外。 这是人们所
-
熊猫经纬度到连续行之间的距离
问题内容: 我在Python 2.7中的Pandas DataFrame中具有以下内容: 我正在寻找计算数据帧中连续行之间的距离。输出应如下所示: 我尝试如下进行调整: 但是,出现以下错误: 此错误已通过MaxU的注释修复。修复后,此计算的输出没有意义-距离近8000 km: 根据: 这个在线计算器:如果我使用Latitude1 = 74.166061,Longitude1 = 30.512811
-
使用2个字段的猫鼬自定义验证
问题内容: 我想使用猫鼬自定义验证来验证endDate是否大于startDate。如何访问startDate值?使用 this.startDate时 ,它不起作用;我不确定。 是比较两个日期的函数。 问题答案: 您可以尝试将日期戳嵌套在父对象中,然后验证父对象。例如:
-
我能在熊猫身上表演动态累加吗?
问题内容: 如果我有以下数据帧,派生如下: 有没有一种有效的方法“cumsum”行有限制并且每次都有这个限制 已到达,开始新的“cumsum”。在达到每个极限后(不管有多少 rows),则创建一个包含总累计和的行。 下面我创建了一个这样做的函数的例子,但是它非常 速度很慢,尤其是当数据帧变得非常大时。我不喜欢这样,我的朋友 函数是循环的,我正在寻找一种方法使它更快(我猜 没有环路)。 If you
-
如何向熊猫数据框添加额外的行
问题内容: 如果我有一个空的数据框: 有没有一种方法可以向此新创建的数据框添加新行?目前,我必须创建一个字典,将其填充,然后将字典附加到最后的数据框中。有没有更直接的方法? 问题答案: 即将发布的pandas 0.13版本将允许通过不存在的索引数据添加行。但是,请注意,这实际上会创建整个DataFrame的副本,因此这不是有效的操作。 说明在此处,此新功能称为“ 放大设置” 。
-
熊猫对有关索引重复条目的警告
问题内容: 在Pandas方法的文档中,我们具有: 我的结构如下: 我想要这样的东西: 但是当我运行该方法时,它是在说: 这没有意义,即使在示例中,该列上也有重复的条目。我将列用作数据透视表的索引,即方法调用的第一个参数。 问题答案: 对我来说还好吗?您可以发布正在使用的确切数据透视方法调用吗?
-
将大熊猫数据帧分块写入CSV文件
问题内容: 如何将大数据文件分块写入CSV文件? 我有一组大型数据文件(1M行x 20列)。但是,我只关注该数据的5列左右。 我想通过只用感兴趣的列制作这些文件的副本来使事情变得更容易,所以我可以使用较小的文件进行后期处理。因此,我计划将文件读取到数据帧中,然后写入csv文件。 我一直在研究将大数据文件以块的形式读入数据框。但是,我还无法找到有关如何将数据分块写入csv文件的任何信息。 这是我现在
-
Nodejs /猫鼬。哪种方法更适合创建文档?
问题内容: 当我使用猫鼬时,我发现了两种在nodejs中创建新文档的方法。 首先 : 第二 有什么区别吗? 问题答案: 是的,主要区别在于您可以在保存之前进行计算,也可以对构建新模型时出现的信息做出反应。最常见的示例是在尝试保存模型之前确保模型有效。其他一些示例可能是在保存之前创建任何缺失的关系,需要基于其他属性即时计算的值以及需要存在但可能永远不会保存到数据库(异常交易)的模型。 因此,作为您可
-
猫鼬更新“无法使用零件(..)遍历元素
问题内容: 我有一个非常烦人的问题,我无法使用猫鼬更新任何内容。使用起来确实令人沮丧,并且文档根本没有帮助。 我有这个架构: 这是我要向阵列添加设备的代码: 在这一点上我得到错误: 我没有找到解释为什么发生这种情况的原因。我不得不提到该文档(数据库中几乎只有一个文档)是这个: 问题答案: 使用$ push或其他数组更新运算符将元素添加到数组。有关详细信息,请参阅http://docs.mong
-
熊猫-将df.index从float64更改为unicode或字符串
问题内容: 我想将数据框的索引(行)从float64更改为字符串或unicode。 我认为这会起作用,但显然不会: 错误信息: 问题答案: 您可以这样操作: 至于为什么将处理方式从int转换为float的原因不同,那就是numpy的特殊性(pandas所基于的库)。 每个numpy数组都有一个 dtype ,它基本上是其元素的 机器 类型:以这种方式, numpy直接处理本机类型 ,而不处理Pyt