
如何将某些列移动到行中?

假设我有下面的df。我想组合价格列和值列,以便所有价格都在一列中,所有卷都在另一列中。我还想要标识价格级别的第三列。例如,unit1、unit2和unit3。
import numpy as np
import pandas as pd
df = pd.DataFrame(
{
'uid': ['U100', 'U200', 'E100', 'E200', 'E300', 'A100', 'A200', 'A300', 'A400', 'A500'],
'location': ['US', 'US', 'EU', 'EU', 'EU', 'Asia', 'Asia', 'Asia', 'Asia', 'Asia'],
'unit1_price': [10, 20, 15, 10, 10, 10, 20, 20, 25, 25],
'unit1_vol': [100, 150, 100, 200, 150, 150, 100, 200, 200, 200],
'unit2_price': [10, 25, 30, 20, 10, 10, 10, 10, 20, 20],
'unit2_vol': [200, 200, 150, 300, 300, 200, 150, 225, 225, 250],
'unit3_price': [0, 0, 0, 20, 20, 20, 20, 20, 20, 20],
'unit3_vol': [0, 0, 0, 500, 500, 500, 500, 500, 500, 500]
}
)
df
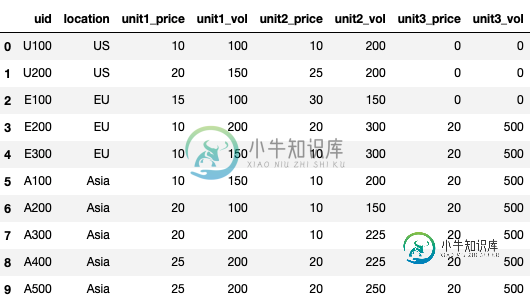
这就是最终的df应该是什么样子:
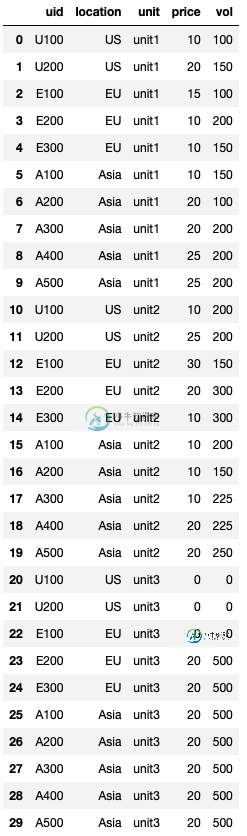
我尝试使用熔体,我认为几乎有正确的答案。
pd.melt(df, id_vars=['uid', 'location'], value_vars=['unit1_price', 'unit1_vol', 'unit2_price', 'unit2_vol', 'unit3_price', 'unit3_vol'])
这就是熔融时部分df的样子:
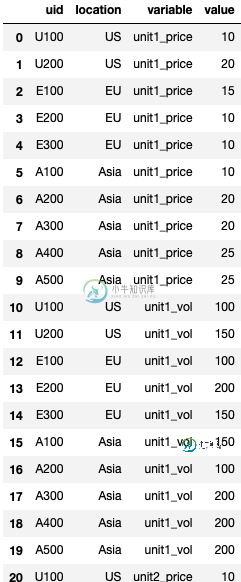
上面的问题是,数量和价格在同一列中,但我希望它们在两个单独的列中。
我使用了正确的函数吗?
共有3个答案

您可以使用pd形成两个数据帧。首先熔化,然后将其合并回一个数据帧。
df1 = df.melt(id_vars=['uid', 'location'], value_vars=['unit1_price', 'unit2_price', 'unit3_price'],var_name='unit',value_name='price')
df2 = df.melt(id_vars=['uid', 'location'], value_vars=['unit1_vol', 'unit2_vol', 'unit3_vol'],var_name='unit', value_name="volume")
ddf = pd.concat([df1,df2['volume']],axis=1).sort_values(by=['uid','unit'],ignore_index=True)
ddf['unit']=ddf['unit'].str.split('_',expand=True)[0]

也许是这样:
import pandas as pd
df = pd.DataFrame(
{
'uid': ['U100', 'U200', 'E100', 'E200', 'E300', 'A100', 'A200', 'A300', 'A400', 'A500'],
'location': ['US', 'US', 'EU', 'EU', 'EU', 'Asia', 'Asia', 'Asia', 'Asia', 'Asia'],
'unit1_price': [10, 20, 15, 10, 10, 10, 20, 20, 25, 25],
'unit1_vol': [100, 150, 100, 200, 150, 150, 100, 200, 200, 200],
'unit2_price': [10, 25, 30, 20, 10, 10, 10, 10, 20, 20],
'unit2_vol': [200, 200, 150, 300, 300, 200, 150, 225, 225, 250],
'unit3_price': [0, 0, 0, 20, 20, 20, 20, 20, 20, 20],
'unit3_vol': [0, 0, 0, 500, 500, 500, 500, 500, 500, 500]
}
)
price = pd.melt(
df, id_vars=['uid', 'location', 'unit2_vol', 'unit1_vol', 'unit3_vol'], value_vars=['unit1_price', 'unit3_price', 'unit2_price'], var_name="price", value_name="price_value"
)
res = pd.melt(
price, id_vars=['uid', 'location', 'price', 'price_value'], value_vars=['unit2_vol', 'unit1_vol', 'unit3_vol'], var_name="vol", value_name="vol_value"
)
print(res)
输出:
uid location price price_value vol vol_value
0 U100 US unit1_price 10 unit2_vol 200
1 U200 US unit1_price 20 unit2_vol 200
2 E100 EU unit1_price 15 unit2_vol 150
3 E200 EU unit1_price 10 unit2_vol 300
4 E300 EU unit1_price 10 unit2_vol 300
.. ... ... ... ... ... ...
85 A100 Asia unit2_price 10 unit3_vol 500
86 A200 Asia unit2_price 10 unit3_vol 500
87 A300 Asia unit2_price 10 unit3_vol 500
88 A400 Asia unit2_price 20 unit3_vol 500
89 A500 Asia unit2_price 20 unit3_vol 500

尝试使用熔化,然后在拆分后枢转
s = df.melt(['uid','location'])
s[['unit','type']] =
s['variable'].str.split('_',expand=True)
s = s.pivot(index = ['uid','location','unit'],columns = ['type'],values = 'value').reset_index()
s
Out[967]:
type uid location unit price vol
0 A100 Asia unit1 10 150
1 A100 Asia unit2 10 200
2 A100 Asia unit3 20 500
3 A200 Asia unit1 20 100
4 A200 Asia unit2 10 150
-
我有一个熊猫数据框,有4行4列-这里是一个简单的版本: 我想做的是把它转换成一个2*8的数据帧,每个数组都有B、C和D——所以它看起来像这样: 在阅读熊猫文档时,我尝试了以下方法: 但是给了我一个错误,我无法识别源(以 DataError:没有要聚合的数字类型 ) 接下来,我想根据一个值分割数据帧,但我认为.groupby命令可能会处理它
-
问题内容: 这个问题已经在这里有了答案 : 熊猫将一些列转换为行 (4个答案) 2年前关闭。 我有一个熊猫数据框,有4行4列-这是asimple版本: 我想做的是将其转换为2 * 8数据帧,并对每个数组使用B,C和D Alligng-因此它看起来像这样: 在阅读熊猫文档时,我尝试了以下方法: 但给我一个错误,我无法识别来源(结尾为 DataError:没有要聚合的数字类型 ) 接下来,我想基于A值
-
所以我的数据集有一些信息,按业务n日期如下: 我需要以下格式的数据:我如何转换它。我不想在我的输出数据集中使用多级 我尝试了以下语法: 我得到的结果如下: 当我打印列时,它不会将LOB显示为列。我的最终数据帧还应该包括业务,日期字段作为列,以便我可以加入这个数据帧与另一个业务数据帧
-
我有一个web应用程序,前端有一个引导表,它的数据由Django rest框架呈现。由于数据是使用数据字段呈现的,所以它只有表头,没有表列。 我想使某些列可编辑,但有些列不可编辑,但无法编辑。contenteditable='true'/'false'标志在列级别不起作用。如何使某些列可编辑,但某些列不可编辑
-
我有例如[100,30]数据帧,我想找到哪些行有超过20列的值?所有行都有30列,但其中一些有NaN值,因此我设置了20列的限制,我想在col.iloc=20之后找到哪些行有列的值 例如,即使在行号05我们有更多的楠值,由于分布,我想找到哪些行有超过3列的X值或楠值(在下表中,我想找到行号1、3、4和7的索引。 我的预期结果: 我发现行的 ID:1,3,4,7 是行在列中有值 但在大型数据帧中 这
-
这是我的密码: 它返回表中所有列的数组。但我不需要把所有的专栏都写下来。我只需要返回以下列:。我对此进行了搜索并找到了答案:(使用函数) 但它并没有返回预期的结果。它返回以下内容: 如您所见,没有和列。我怎样才能修好它?