
如何动态添加数据帧中某些列的值?

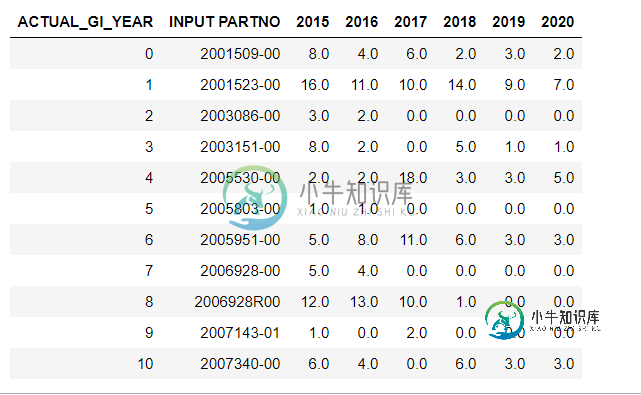
图像中的数据帧
year= 2020 (MAX COLUMN)
lastFifthYear = year - 4
input = '2001509-00'
我想将年份(2020年)和上一个第五年(2016年)之间的所有值相加,其中输入PARTNO=输入
因此,对于输入值,我应该得到4 6 2 3 2(2016 2017 2019 2020),即17
请给我一些密码
共有2个答案

示例设置
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(0, 10, (10, 10)),
columns=list('ab')+list(range(2,10)))
已解决
#sum where a == 9 columns between 3,6 by rows
df['number'] = df.loc[df['a'].eq(9),
pd.to_numeric(df.columns, errors='coerce')
.to_series()
.between(3, 6)
.values].sum(axis=1)
print(df)
a b 2 3 4 5 6 7 8 9 number
0 1 9 9 2 6 0 6 1 4 2 NaN
1 2 3 4 8 7 2 4 0 0 6 NaN
2 2 2 7 4 9 6 7 1 0 0 NaN
3 0 3 5 3 0 4 2 7 2 6 NaN
4 7 7 1 4 7 7 9 7 4 2 NaN
5 9 9 9 0 3 3 3 8 7 7 9.0
6 9 0 5 5 7 9 6 6 5 7 27.0
7 2 1 9 1 9 3 3 4 4 9 NaN
8 4 0 5 9 6 7 3 9 1 6 NaN
9 5 5 0 8 6 4 5 4 7 4 NaN

这里是一些应该工作的代码,但你肯定需要改进你在这里提问的方式:-)
考虑到df是您粘贴为上图的表。
>>> year = 2016
>>> df_new=df.query('INPUT_PARTNO == "2001509-00"').melt(['ACTUAL_GI_YEAR', 'INPUT_PARTNO'], var_name='year', value_name='number')
>>> df_new.year=df_new.year.astype(int)
>>> df_new[df_new.year >= year].groupby(['ACTUAL_GI_YEAR','INPUT_PARTNO']).agg({'number' : sum})
number
ACTUAL_GI_YEAR INPUT_PARTNO
0 2001509-00 17
-
假设我有一个空的dataframe,已经设置了列,但没有行。我从网上搜集了一些数据,所以假设我需要向空数据帧添加一个索引< code>'2176'。当我试图分配该行时,如何自动将它添加到数据库中?这是熊猫的目的还是我应该用别的东西?
-
向pandas对象添加空列的最简单方法是什么?我偶然发现的最好的东西是 有没有一种不那么反常的方法?
-
本文向大家介绍在某些情况下如何更改R数据帧中的列?,包括了在某些情况下如何更改R数据帧中的列?的使用技巧和注意事项,需要的朋友参考一下 有时,特定列的列值与另一列有某种关系,我们可能需要根据某些条件来更改该特定列的值。我们需要进行此更改,以检查列值的更改如何对所考虑的两个列之间的关系产生影响。在R中,我们可以使用单个方括号来更改列值。 示例 请看以下数据帧- 假设我们想从第2列(x2)值中减去2,
-
本文向大家介绍如何在MySQL的列中的某些值中添加前导零?,包括了如何在MySQL的列中的某些值中添加前导零?的使用技巧和注意事项,需要的朋友参考一下 要将前导零添加到某个值,请使用MySQL的功能。语法如下- 这是的示例。 以下是输出- 为了在实际示例中检查它,让我们首先创建一个表- 现在,借助insert命令将一些记录插入表中。查询如下- 显示表中存在多少记录。查询以显示所有记录。 以下是输出
-
我想在我的数据的每一列中找到< code>NaN的数目。
-
我有一个数据框架,其中有2列。第一列似乎没有列名,第二列名为< code>Speed。 这是一个MRE: 这是我执行打印语句时的输出: 这是我想要的输出: