
如何在熊猫数据帧中使用内/内运算符?[重复]

我想从我的CSV文件中选择数据。
虽然我可以在哪一列中获取数据
"House" == 1 (any single number)
如下所示,我不知道如何从何处获取数据
"House" in [1, 2, 3, 4, 6, 7, 8, 9, 10, 13, 17, 18, 20, 21, 23, 26, 28, 30, 34, 46, 57, 58, 61, 86, 89, 102, 121, 156].
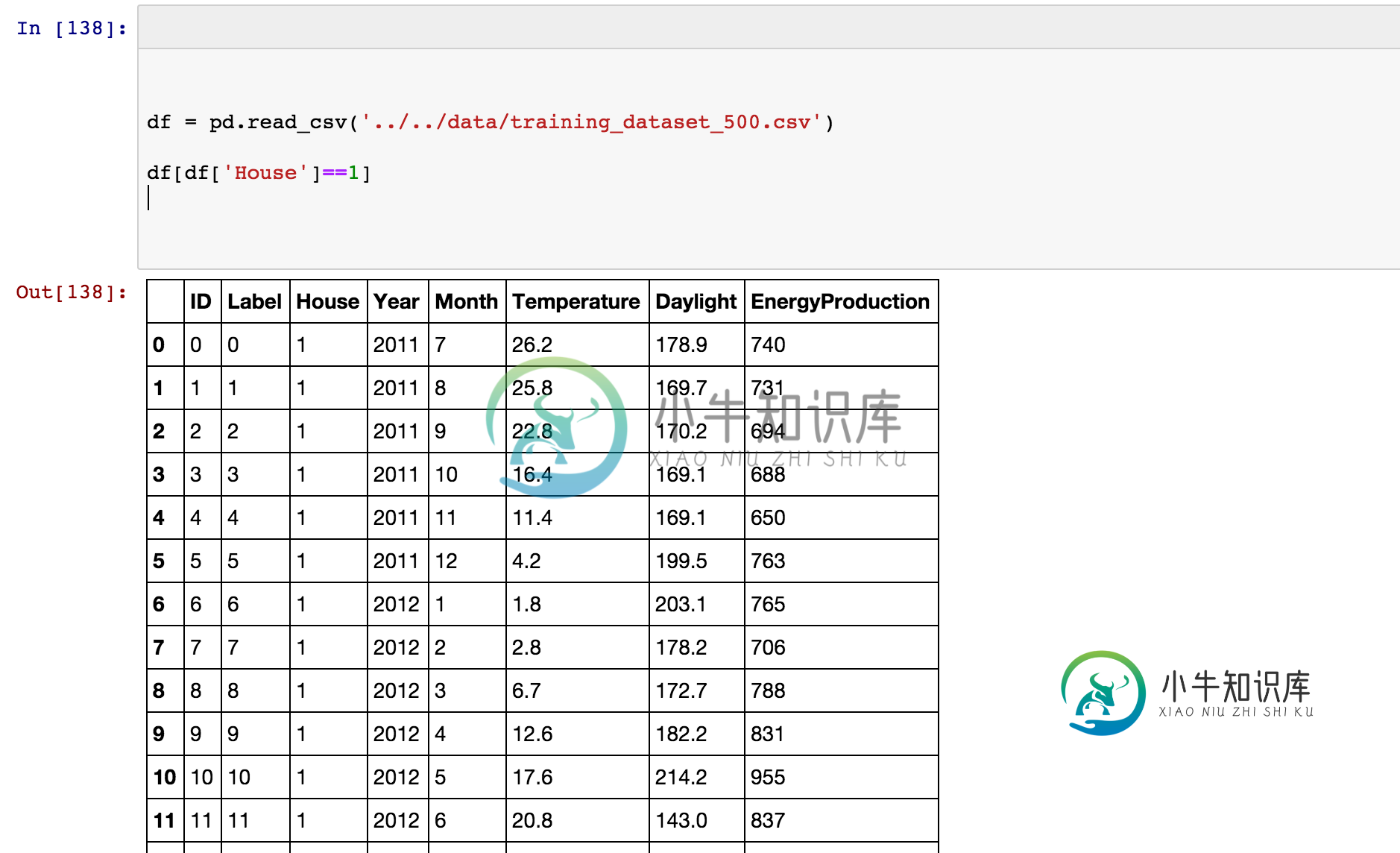
df = pd.read_csv('../../data/training_dataset_500.csv')
df[df['House']==1]
共有1个答案

使用Series.isin()方法检查序列值是否在值列表中。在你的情况下-
df[df['House'].isin([1, 2, 3, 4, 6, 7, 8, 9, 10, 13, 17, 18, 20, 21, 23, 26, 28, 30, 34, 46, 57, 58, 61, 86, 89, 102, 121, 156])]
范例-
In [77]: df
Out[77]:
A B
0 1 5
1 2 6
2 3 7
3 4 8
In [78]: df[df['A'].isin([1,2])]
Out[78]:
A B
0 1 5
1 2 6
-
我有一个需要一个数据帧作为输入的计算。我想对存储在扩展到51GB的netCDF文件中的数据运行此计算-目前,我一直在使用打开文件,并使用块(我的理解是,此打开的文件实际上是一个dask数组,因此一次只能将数据块加载到内存中)。但是,我似乎无法利用这种延迟加载,因为我必须将xarray数据转换为pandas数据帧才能运行我的计算——我的理解是,在这一点上,所有数据都加载到内存中(这是不好的)。 所以
-
这似乎是非常基本的知识,但我还是卡住了,尽管我有一些数据处理的理论背景(通过其他软件)。值得一提的是,我是蟒蛇和熊猫图书馆的新手。 我的任务是将系列名称列的值作为单独的列(从长到宽转换)。我花了很长时间尝试不同的方法,但只有错误。 例如: 我犯了一个错误: ...很多短信...通过值的长度是2487175,索引暗示2 有谁能指导我完成这个过程吗?谢谢 它用于代码“mydata=mydata”。pi
-
我一直在想...如果我正在读取,比方说,一个400MB的csv文件到熊猫数据帧(使用read_csv或read_table),有没有办法猜测这需要多少内存?只是想更好地感受数据帧和内存...
-
假设熊猫数据帧如下所示: 如何将第三行(如row3)提取为pd数据帧?换句话说,row3.shape应该是(1,5),row3.head()应该是:
-
我有一个熊猫数据框,如下所示: 我如何将每分钟的数据分组,并计算每分钟每个状态的数量,以获得此数据帧:
-
我试图通过保持行之间的一致性来随机化我的行,但会混淆行的顺序,从而随机化从属变量。我有以下数据帧: 并将行随机化: 然后执行重置索引,如 期望输出: