
大熊猫

我有一个数据帧,如:
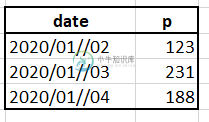
所以我想通过两个“for循环”添加一些列,如:
新的类似数据帧的图片:
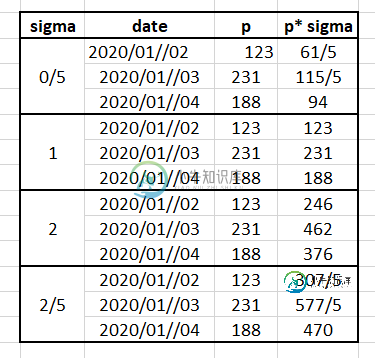
我的代码不起作用:
for I in range(0,len(df["date"]):
for sigma in rang(1,2/5):
df["P*sigma"].iloc[0:i]=df["p"].iloc[0:i]*df["sigma"].iloc[sigma]
print(df)
如何编写代码来获得像第二张图片这样的数据帧?
共有3个答案

在python中,可以使用muliplication符号*重复数组。如果您有自由列sigma、date和p,则很容易以正确的形状定义数据帧。要创建新列,只需执行元素乘法(不需要apply()调用)。之后,如果需要,可以设置索引。
import pandas as pd
sigma = [0.5, 1, 2, 2/5]
date = ['2020/01//02', '2020/01//03', '2020/01//04']
p = [123,231,188]
df = pd.DataFrame({'sigma':sigma*len(p), 'date':date*len(sigma), 'p':p*len(sigma)})
df['p*sigma'] = df['p']*df['sigma']
df.set_index(['sigma', 'date'], inplace=True)
>>>df
p p*sigma
sigma date
0.5 2020/01//02 123 61.5
1.0 2020/01//03 231 231.0
2.0 2020/01//04 188 376.0
0.4 2020/01//02 123 49.2
0.5 2020/01//03 231 115.5
...

在像这样添加行和列“sigma”之后,您可以使用DataFrame.apply like
df["P*sigma"] = df.apply(lambda x: x["p"] * x["sigma"], axis=1)

您可以使用多索引来实现这一点,多索引可以通过多种方式实现,但我始终更喜欢使用来自\u product()的。
请注意,在执行此操作之前,我们必须做一些准备。我们必须确保在原始数据帧上正确设置了索引,并且必须拉长原始数据帧以允许新行。
import pandas as pd
df = pd.DataFrame({'date': ['2020/01/01', '2020/01/02', '2020/01/03'], 'p': [123, 231, 188]})
df = df.set_index('date')
sigma = [0, 1, 2, 5]
# Create new 2-level index
multi_index = pd.MultiIndex.from_product([sigma, df.index], names=['sigma', 'date'])
# Make longer
df = pd.concat([df] * len(sigma))
# Set new index
df = df.set_index(multi_index)
# Print result
print(df.head())
>>> p
>>> sigma p
>>> 0 2020/01/01 123
>>> 2020/01/02 231
>>> 2020/01/03 188
>>> 1 2020/01/01 123
>>> 2020/01/02 231
如果您想创建新的列或使用索引值,您可以使用get_level_values()获取这些值,如下所示:
df["p*sigma"] = df.index.get_level_values("sigma") * df["p"]
print(df.head())
>>> p p*sigma
>>> sigma date
>>> 0 2020/01/01 123 0
>>> 2020/01/02 231 0
>>> 2020/01/03 188 0
>>> 1 2020/01/01 123 123
-
我正在读取一个包含多个datetime列的csv文件。我需要在读取文件时设置数据类型,但datetimes似乎是个问题。例如: 运行时出现错误: 不理解数据类型"datetime" 通过pandas在事实之后转换列。to_datetime()不是一个选项,我不知道哪些列将成为datetime对象。这些信息可以更改,并且来自于通知我的数据类型列表的任何信息。 或者,我尝试用numpy.genfrom
-
问题内容: 我有一个包含屏幕名称,tweet,收藏夹等的Pandas DataFrame。我想找到“ favcount”(我已经做过)的最大值,并返回该“ tweet”的屏幕名称 我似乎找不到任何东西,任何人都可以帮助我朝正确的方向发展吗? 问题答案: 使用 来获取最大价值的指标。那你可以用 编辑: 现已弃用,切换为
-
我一直在尝试使用Swagger生成REST API文档。 关注了链接,但无法使其生效。得到以下错误 下一步搜索并找到最接近我的问题的链接。再次遵循它,但仍然得到上述错误。我看不到swagger.json被生成。 版本信息 我是否错过了一些使其工作所需的配置?或者我需要更多的图书馆吗? 谢谢
-
问题内容: 我正在使用以下df: 我想在所有年份中强制使用数字: 有没有简单的方法可以做到这一点,还是我必须全部输入? 问题答案: 更新: 您以后不需要转换值,可以在读取CSV时 即时 进行: 如果您需要将多列转换为数字dtypes,请使用以下技术: 样本来源DF: 将选定的列转换为数字dtypes: PS,如果要选择 所有 ()列,请使用以下简单技巧:
-
问题内容: 我正在做一些地理编码工作,我曾用它来屏幕刮取位置地址所需的xy坐标,我将xls文件导入了panda数据框,并希望使用显式循环来更新没有xy坐标的行,例如下面: 我已经阅读了为什么在遍历熊猫DataFrame之后该功能不能“使用”?并且完全意识到,iterrow仅提供给我们一个视图,而不是一个供编辑的副本,但是如果我真的要逐行更新值怎么办?是否可行? 问题答案: 您从中获得的行是不再连接
-
查看以下: 问题是它不会在ipython笔记本中按默认值打印所有行,但我必须切片才能查看结果行。即使以下选项也不会更改输出: 有人知道如何显示整个阵列吗?