
HPA 缩放在Spring启动期间触发。HPA 中的当前 CPU 指标很高,尽管节点级别的 CPU 利用率较低

我们在 GKE 上有一个启用了自动缩放 (HPA) 的Spring启动应用程序。在启动期间,HPA 会启动并开始缩放 Pod,即使没有流量也是如此。“kubectl 得到 hpa”的结果显示当前 CPU 平均利用率很高,而节点和 POD 的 CPU 利用率非常低。在纵向扩展期间,行为是相同的,并且最终会创建多个 Pod,从而导致 Node 扩展。
应用部署Yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-api
labels:
app: myapp
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
serviceAccount: myapp-ksa
containers:
- name: myapp
image: gcr.io/project/myapp:126
env:
- name: DB_USER
valueFrom:
secretKeyRef:
name: my-db-credentials
key: username
- name: DB_PASS
valueFrom:
secretKeyRef:
name: my-db-credentials
key: password
- name: DB_NAME
valueFrom:
secretKeyRef:
name: my-db-credentials
key: database
- name: INSTANCE_CONNECTION
valueFrom:
configMapKeyRef:
name: connectionname
key: connectionname
resources:
requests:
cpu: "200m"
memory: "256Mi"
ports:
- containerPort: 8080
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 90
periodSeconds: 5
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
- name: cloudsql-proxy
image: gcr.io/cloudsql-docker/gce-proxy:1.17
env:
- name: INSTANCE_CONNECTION
valueFrom:
configMapKeyRef:
name: connectionname
key: connectionname
command: ["/cloud_sql_proxy",
"-ip_address_types=PRIVATE",
"-instances=$(INSTANCE_CONNECTION)=tcp:5432"]
securityContext:
runAsNonRoot: true
runAsUser: 2
allowPrivilegeEscalation: false
resources:
requests:
memory: "128Mi"
cpu: "100m"
用于HPA的Yaml:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-api
labels:
app: myapp
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-api
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
各种命令的结果:
$ kubectl get pods
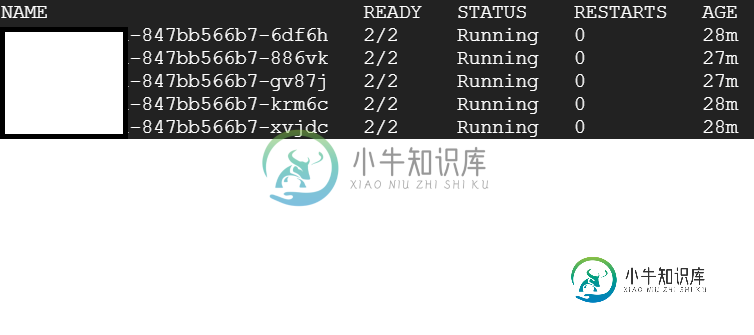
$ kubectl get hpa

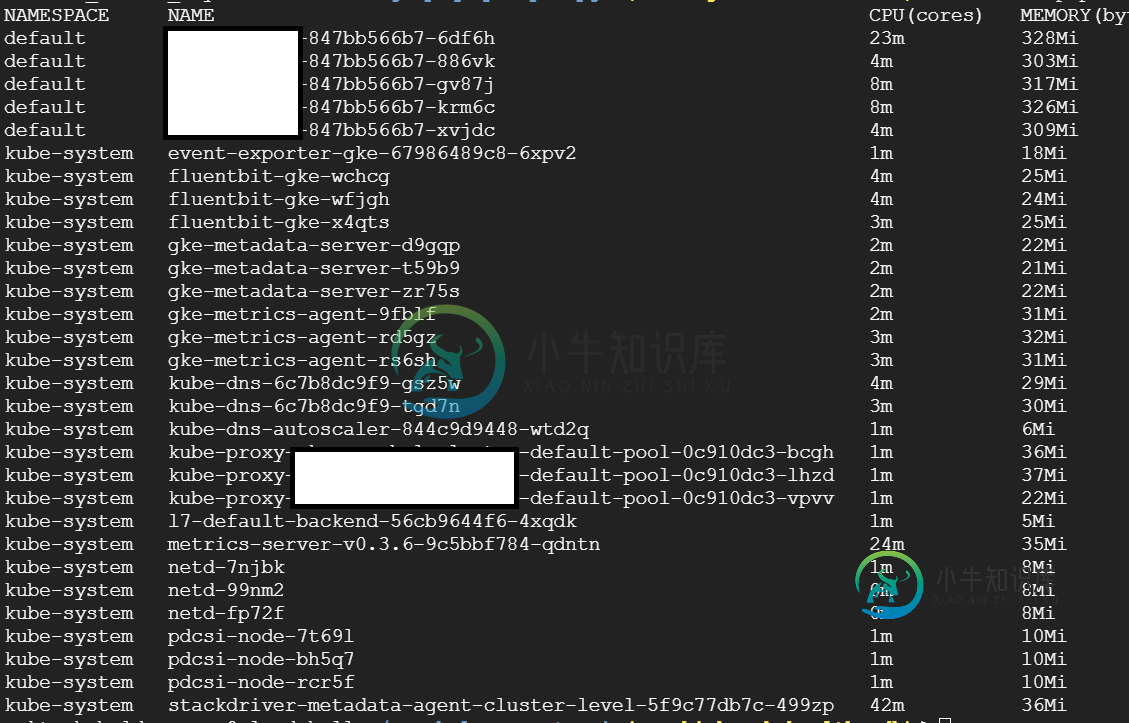
$ kubectl top nodes

$ kubectl top pods --all-namespaces
共有1个答案

由于问题已经在评论部分得到解决,我决定提供一个社区Wiki答案,只是为了更好地了解其他社区成员。
问题中的kubectl get hpa命令显示导致Pods缩放的高当前内存利用率。
从kubectl get hpa命令读取TARGETScolumn可能会令人困惑:
注意:33%的值适用于内存或cpu?
$ kubectl get hpa app-1
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
app-1 Deployment/app-1 33%/80%, 4%/80% 2 5 5 5m37s
我推荐使用< code>kubectl描述hpa
$ kubectl describe hpa app-1 | grep -A 2 "Metrics:"
Metrics: ( current / target )
resource memory on pods (as a percentage of request): 33% (3506176) / 80%
resource cpu on pods (as a percentage of request): 4% (0) / 80%
-
Kubernetes version: 1.12.8-gke.10 正在使用的云:GKE 安装方式: 主机操作系统:(计算机类型)n1-标准-1 国家知识产权局和版本:默认 CRI 和版本:默认 在节点缩放期间,HPA无法获取CPU度量。 同时,和output为:服务器错误(ServiceUnavailable):服务器当前无法处理请求(get-pods.metrics.k8s.io) 有关更多详
-
我的HPA的内容 有谁知道这可能是什么原因?
-
我正在使用mod安全规则https://github.com/SpiderLabs/owasp-modsecurity-crs清理用户输入数据。在将用户输入与mod security rule正则表达式匹配时,我面临着cpu激增和延迟。总的来说,它包含500个正则表达式来检查不同类型的攻击(xss、badrobots、generic和sql)。对于每个请求,我检查所有参数并对照所有这500个正则表
-
谁能解释一下这两种方法的真正区别 vm。GetTotalizationofCPU(CloudSim.clock()); 和 cloudlet.get利用OfCpu(CloudSim.clock()); 提前感谢
-
从库伯内特斯v1.18开始,v2beta2 API允许通过水平Pod Autoscalar(HPA)行为字段配置缩放行为。我计划将具有自定义指标的HPA应用于StatefulSet。 我正在查看的用例是使用自定义指标(例如,我的应用程序上的用户会话数量)进行扩展,但HPA根本不会缩减。K8s SIG-Autoscaling增强功能也描述了此用例-“HPA的可配置缩放速度 用户会话可以在几分钟到几小
-
Kubernetes中不仅支持CPU、内存为指标的HPA,还支持自定义指标的HPA,例如QPS。 本文中使用的yaml文件见manifests/HPA。 设置自定义指标 kubernetes1.6 在kubernetes1.6集群中配置自定义指标的HPA的说明已废弃。 在设置定义指标HPA之前需要先进行如下配置: 将heapster的启动参数 --api-server 设置为 true 启用cus