
HPA扩展,即使当前CPU低于目标CPU

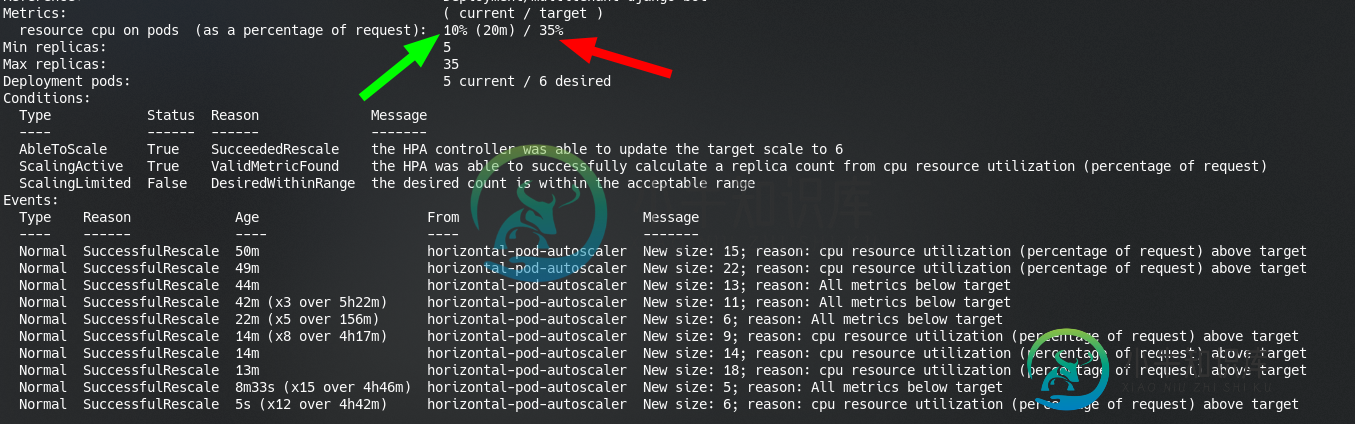

我的HPA的内容
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: django
spec:
{{ if eq .Values.env "prod" }}
minReplicas: 5
maxReplicas: 35
{{ else if eq .Values.env "staging" }}
minReplicas: 1
maxReplicas: 3
{{ end }}
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: django-app
targetCPUUtilizationPercentage: 35
有谁知道这可能是什么原因?
共有2个答案

缩放基于%的请求而不是限制。我认为我们应该更改这个答案,因为已接受答案中的示例显示:
limits:
cpu: 1000m
但目标 CPU 利用率百分比基于以下请求:
requests:
cpu: 1000m
对于每个pod的资源指标(如CPU),控制器从HorizontalPodAutoscaler针对的每个Pod的资源指标API中获取指标。然后,如果设置了目标利用率值,则控制器将利用率值计算为每个箱中的容器上的等效资源请求的百分比。如果设置了目标原始值,则直接使用原始度量值。然后,控制器取所有目标箱的利用率或原始值(取决于指定的目标类型)的平均值,并产生一个比率,用于缩放所需副本的数量。
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#how-does-a-horizontalpodautoscaler-work

这很棘手,可能是一个bug,但我不这么认为,正如我将解释的,大多数时候人们配置的值太低。
< code > targetCPUUtilizationPercentage 根据pod可以使用的所有CPU来配置百分比。在Kubernetes上,如果不对CPU使用指定一些< code >限制,我们就无法创建< code>HPA。
让我们假设这是我们的极限:
apiVersion: v1
kind: Pod
metadata:
name: apache
spec:
containers:
- name: apache
image: httpd:alpine
resources:
limits:
cpu: 1000m
在HPA内部的targetCPUtilizationPercentage中,我们指定75%。
这很容易解释,因为我们要求100% (1000m = 1个CPU内核)的单核,所以当这个内核的使用率达到75%左右时,HPA就会开始工作。
但是,如果我们将极限定义为:
spec:
containers:
- name: apache
image: httpd:alpine
resources:
limits:
cpu: 500m
现在,我们的吊舱可以利用的100%CPU仅为单核的50%。很好,所以这个吊舱100%的cpu使用率意味着,在硬件上,单核使用率为50%。
这对于目标CPU利用率百分比是无动于衷的,如果我们保持75%的值,HPA将在我们的单个内核使用率约为37.5%时开始工作,因为这是这个pod可以消耗的所有CPU的75%。
从pod/hpa的角度来看,他们从不知道自己在CPU或内存方面受到了限制。
对于上面问题中使用的一些程序——CPU峰值确实会发生——但是只在小时间范围内(例如10秒峰值)。由于这些峰值的持续时间很短,度量服务器不会保存这个峰值,而只会在1m窗口后保存度量。在这种情况下,这些窗口之间的峰值将被排除在外。这解释了为什么在度量仪表板中看不到峰值,而是由HPA接收。
因此,对于cpu限制较低的服务,较大的纵向扩展时间窗口(HPA中的< code>scaleUp设置)可能是理想的。
-
我们在 GKE 上有一个启用了自动缩放 (HPA) 的Spring启动应用程序。在启动期间,HPA 会启动并开始缩放 Pod,即使没有流量也是如此。“kubectl 得到 hpa”的结果显示当前 CPU 平均利用率很高,而节点和 POD 的 CPU 利用率非常低。在纵向扩展期间,行为是相同的,并且最终会创建多个 Pod,从而导致 Node 扩展。 应用部署Yaml: 用于HPA的Yaml: 各种命
-
我需要定期将数据从TMP数据库复制到远程PROD数据库,并在列中进行一些数据修改。当我使用PROD数据库中的postgres_fdw扩展(带有映射外部模式)时,复制一百万条记录的过程将持续6分钟。 但是,当我使用dblink从PROD数据库复制相同的表时(SQL运行在PROD数据库上,而不是TEMP上),该过程持续20秒。 如何优化和缩短从临时数据库复制数据的过程? 我必须在TMP数据库上运行SQ
-
我对我的pod的所有容器设置了CPU和内存请求=限制,以使其符合有保证的服务质量等级。现在,查看过去6小时内同一Pod的CPU使用率和CPU节流图。 这看起来是不是很正常,也在意料之中? CPU使用率甚至一次都没有达到设定限制的50%,但有时仍被限制在58%。 还有一个附带的问题,节流图中25%的红线表示什么? 我对这个主题做了一些研究,发现内核中有一个错误Linux可能导致这个问题,它在内核的4
-
TypeScript与Java的? 我可以这样模仿它: 但有没有办法把它缩短为: ? 也许这还没有实施? 还是有其他语法? 或者不支持这个是有原因的?
-
关于SO的压倒性建议是编译SDK通常应该与目标SDK匹配。 https://stackoverflow.com/A/27629181/360211 同样,最好让[compileSdk]与您的目标sdk版本相匹配。 null
-
问题内容: 我想用Java解决带有多个线程的数学问题。我的数学问题可以分为多个工作单元,我想通过几个线程来解决。 我不希望有固定数量的线程在工作,而是与CPU核心数量匹配的线程数量。我的问题是,为此我在互联网上找不到简单的教程。我发现的只是带有固定线程的示例。 如何才能做到这一点?你能提供例子吗? 问题答案: 你可以通过使用静态运行时方法,确定提供给Java虚拟机的进程数availableProc