
NPU 简介
NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。
在GX8010中,CPU和MCU各有一个NPU,MCU中的NPU相对较小,习惯上称为SNPU。
NPU处理器包括了乘加、激活函数、二维数据运算、解压缩等模块。
乘加模块用于计算矩阵乘加、卷积、点乘等功能,NPU内部有64个MAC,SNPU有32个。
激活函数模块采用最高12阶参数拟合的方式实现神经网络中的激活函数,NPU内部有6个MAC,SNPU有3个。
二维数据运算模块用于实现对一个平面的运算,如降采样、平面数据拷贝等,NPU内部有1个MAC,SNPU有1个。
解压缩模块用于对权重数据的解压。为了解决物联网设备中内存带宽小的特点,在NPU编译器中会对神经网络中的权重进行压缩,在几乎不影响精度的情况下,可以实现6-10倍的压缩效果。
为了能将基于TensorFlow的模型用NPU运行,需要使用gxDNN工具。
gxDNN用于将用户生成的Tensorflow模型编译成可以被NPU硬件模块执行的指令,并提供了一套API让用户方便地运行TensorFlow模型。 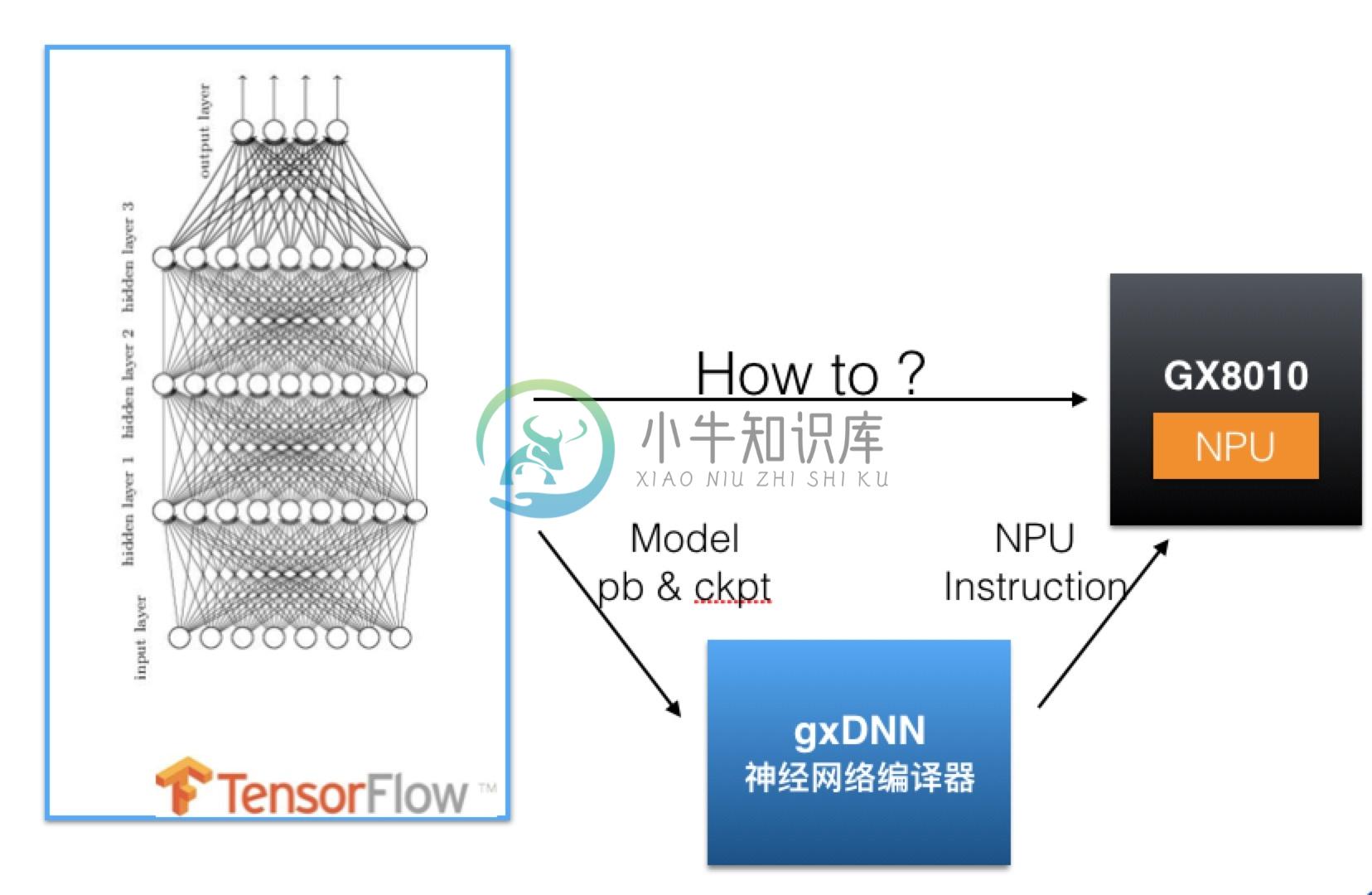 图:gxDNN神经网络处理器的作用
图:gxDNN神经网络处理器的作用
gxDNN包括NPU编译工具和NPU执行器。
NPU编译工具用于生成能够被NPU执行器执行的文件,该文件里包含了NPU执行指令和模型的描述信息。一般在PC机上使用。
NPU执行器提供了一套API,用于解析执行文件,加载模型,输入数据,运行模型得到输出结果。它需要在有NPU硬件模块的机器上使用。
在PC上生成TensorFlow的Graph(pb文件)和Variable(ckpt文件)后,将两者合并为一个pb文件。
在PC上使用GXDNN的NPU编译器,将pb文件转化成能被NPU加载执行的指令文件,在CPU上该文件称为NPU文件,在MCU上为C文件。
芯片端调用NPU API,导入模型,传入输入数据,运行模型,得到输出数据。

TensorFlow的运算流程基于图(graph),图的结点称为op,op将0个或多个输入数据进行计算,生成0个或多个输出数据。NPU编译器的主要工作就是把一个个op转变成可以被NPU硬件模块执行的命令。
针对CPU和MCU的不同特性,生成的指令文件格式也不相同。
用户使用NPU编译工具生成NPU指令文件后,需要调用NPU执行器的API接口,让模型“跑”起来。
由于CPU和MCU的系统不同,提供的API接口也不同。详见 模型部署